20 Frontiers & Open Problems
“Any sufficiently advanced technology is indistinguishable from magic.”
— Arthur C. Clarke (Clarke’s Third Law)
After this chapter you will have a map of where agent research is heading and the hard problems that remain.
20.1 Capable, but far from solved
We have come a long way. This book began with a single language model that could only produce text, and step by step we gave it tools, memory, reasoning, orchestration, teammates, evaluation, observability, guardrails, and a path into production and the wider world. It is worth pausing, at the end, to hold two truths at once: today’s agents are genuinely capable — capable enough to write code, research questions, and automate real work — and they are far from solved. Both halves matter, and mistaking either for the whole leads you astray.
The honest way to picture the current moment is by analogy to an earlier technology at a similar stage. The self-driving car of a decade ago could cruise a clear highway impressively well and then be defeated by a construction cone or a light snowfall — dazzling in the demo, brittle at the edges, and a long, hard road from “works in the good case” to “trustworthy everywhere.” Agents are at that same adolescent stage: they shine on the happy path and stumble on the long tail, they can be brilliant and unreliable in the same afternoon. Recognizing this is not pessimism; it is the prerequisite for working on what comes next. This final chapter is a map of that frontier — the problems still unsolved, the directions the field is moving, and the responsibilities that come with building this technology. Consider Figure 20.1 its legend.
The thread that has run through every chapter — start simple, add capability only when the problem earns it, and stay honest about limits — is exactly the thread we need to follow one last time as we look ahead. So let us begin where any honest map of a frontier must: with the territory not yet charted, the problems that remain genuinely open.
20.2 The problems that remain open
A mature field is defined not only by what it has solved but by how clearly it can state what it has not. For agents, several problems remain genuinely open — not engineering details to be tidied up, but deep challenges that current approaches only partly address [1]. Reassuringly, each one is a familiar friend: every open problem is the unfinished edge of a capability we spent a chapter building.
Five stand out. The first is long-horizon reliability — the compounding-error problem from Chapter 8, unsolved at scale. Agents can chain a handful of steps well but still lose their way across the hundreds of steps a truly complex, days-long task demands, because small errors accumulate faster than agents can recover from them. The second is continual learning and self-improvement: today’s agents do not truly learn from experience once deployed, since the model’s weights are frozen. Voyager’s growing skill library (Section 19.4) is a clever workaround — learning stored outside the model — but an agent that genuinely gets better at its job the way a person does remains a research frontier. The third is memory at scale: the systems of Chapter 11 work for a conversation, but keeping useful memory over months or years without it decaying into noise or contradiction is unsolved. The fourth is evaluation itself, the honest admission from Chapter 15 that we still lack robust ways to measure open-ended agent quality — you cannot reliably improve what you cannot reliably measure. The fifth, and weightiest, is alignment and governance: ensuring that increasingly autonomous agents pursue the goals we actually intend, safely, the concern of Chapter 17 scaled up to systems of real power. Table 20.1 ties each to the chapter that introduced its foundation.
| Open problem | What’s still hard | Foundation laid in |
|---|---|---|
| Long-horizon reliability | Errors compound over very long tasks | Chapter 8 |
| Continual learning | Frozen weights; no true learning post-deployment | Section 19.4 |
| Memory at scale | Useful recall over months without decay | Chapter 11 |
| Evaluation | Measuring open-ended quality robustly | Chapter 15 |
| Alignment & governance | Autonomy that stays aligned with intent | Chapter 17 |
The encouraging way to read that table is that you are not a spectator to these problems but equipped to work on them: every one sits directly atop machinery you now understand from the inside. These are the questions the field is actively wrestling with — which naturally raises the question of how, and where the momentum is carrying us next.
20.3 Where the field is heading
Predicting the future of a fast-moving field is a good way to look foolish in hindsight, so rather than forecast specific breakthroughs, it is safer and more useful to name the directions where momentum is clearly building. The instructive parallel is the early internet: progress accelerated not from one invention but from the moment shared standards like TCP/IP and HTTP let everyone build on the same foundation, and an ecosystem exploded on top. Agents are in that standards-forming phase now, and three currents are worth watching.
The first is standardization and interoperability. The Model Context Protocol of Chapter 10 is the clearest example — a common way for agents to connect to tools and data that, if it takes hold, turns today’s bespoke integrations into a plug-and-play ecosystem, the “USB-C moment” maturing into an actual marketplace of interoperable parts. The second is stronger reasoning at the core. Much of an agent’s competence is inherited from the reasoning ability of the model beneath it, which we examined in Chapter 5 and Chapter 7; as models are increasingly trained specifically to reason and plan over many steps, every agent built on them inherits the lift without changing its architecture. The third is better tooling and infrastructure — the frameworks of Chapter 12 and Chapter 13, and the evaluation and observability platforms of Part 4, are maturing from research code into dependable engineering foundations, which is exactly what lets a technology move from labs into production at scale.
Notice that none of these is a promise of artificial general intelligence or any particular dramatic leap; they are the unglamorous, compounding improvements — better standards, better models, better tools — that actually move a field forward. That measured framing matters, because the more capable agents become along these axes, the more urgent the question we have deferred to last: not what agents can do, but what we should let them do.
20.4 A responsible outlook
Every chapter of this book has, in its own way, been about a single balance: the tension between capability and control. We gave agents the power to act, and then — with guardrails, oversight, evaluation, and observability — we worked to keep that power accountable. As agents grow more capable, that balance does not become less important; it becomes the whole game. The right way to feel the stakes is the way society already treats any powerful tool. A car grants enormous freedom, and precisely because it does, we surround it with licenses, rules of the road, seatbelts, and brakes — not to blunt its usefulness but to make that usefulness survivable. The freedom and the safeguards are not opponents; the safeguards are what let us enjoy the freedom at all.
The failure mode to fear is not capability itself but capability that outruns control — an agent powerful enough to cause real harm, wired without the checks to prevent it. Figure 20.2 draws the balance the rest of this book has been quietly maintaining: as the left pan of capability grows heavier, the right pan of control must grow with it, or the whole thing tips.
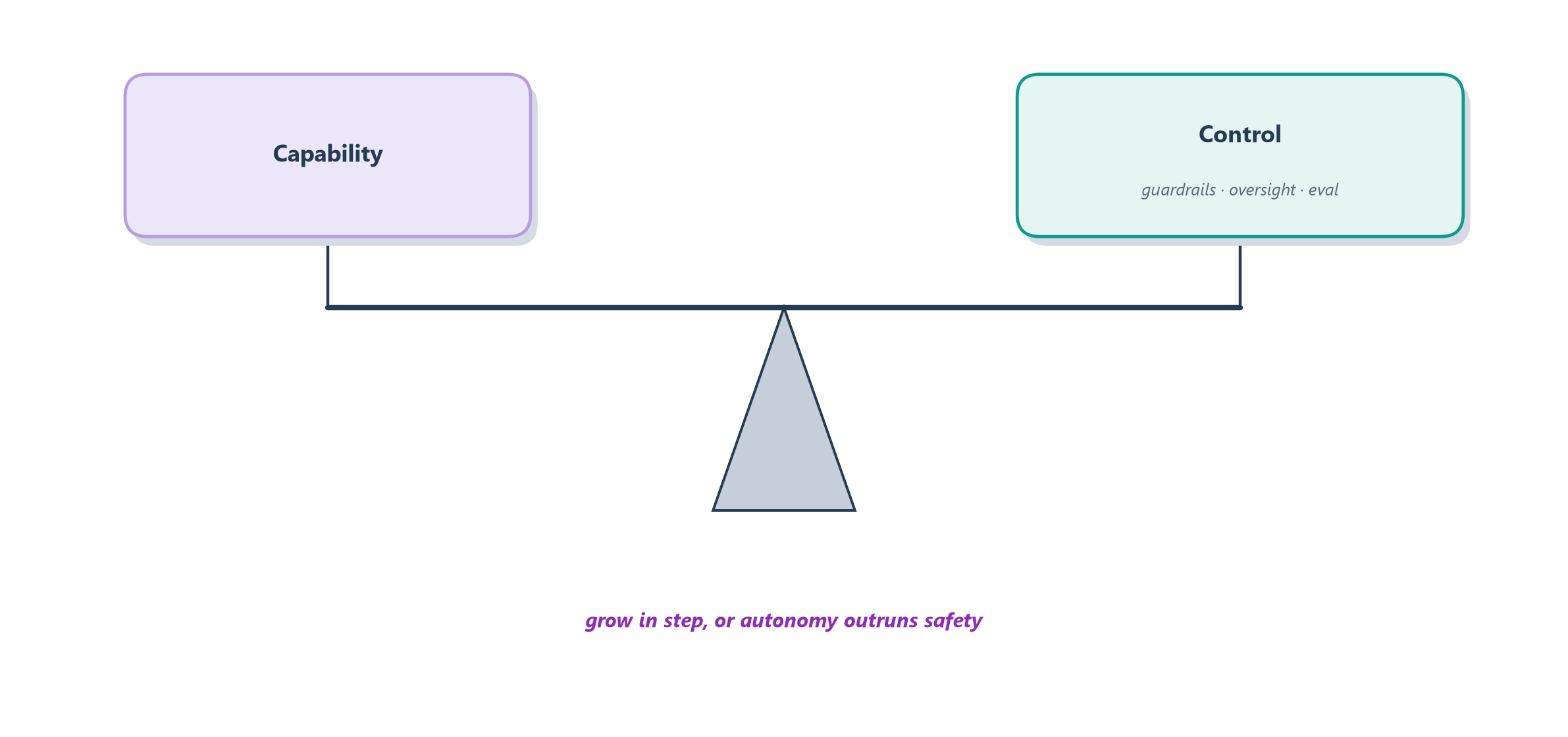
This is not an abstract worry; it lands as concrete responsibility on the people who build these systems. It means matching an agent’s autonomy to the stakes of its task — the discipline of Section 5.6 and the oversight spectrum of Section 17.4 — and asking, before reaching for autonomy at all, whether the problem genuinely earned it [2]. It means being honest about societal impact: agents will reshape work, and someone must remain accountable when an autonomous system acts in the world, because accountability cannot itself be automated away. The engineer who internalizes this — who reaches for the simplest thing that works, adds power only when the problem demands it, and never lets capability outrun control — is exactly the responsible builder this technology needs. That, more than any single technique, is the durable lesson worth carrying out of this book.
20.5 Summary
This chapter mapped the frontier — the problems still open, the directions the field is moving, and the responsibility that must grow alongside capability.
- Today’s agents are capable but far from solved — brilliant on the happy path, brittle on the long tail, like self-driving cars a decade ago.
- Five problems remain genuinely open: long-horizon reliability, continual learning and self-improvement, memory at scale, evaluation, and alignment and governance. Each is the unfinished edge of a capability built earlier in this book.
- The field’s momentum runs along three durable currents: standardization (protocols like MCP), stronger reasoning in the underlying models, and better tooling and infrastructure — steady compounding progress, not a single dramatic leap.
- The defining challenge is the balance between capability and control: as agents grow more powerful, the guardrails, oversight, and accountability around them must grow in step.
- The durable lesson: reach for the simplest thing that works, add power only when the problem earns it, and never let capability outrun control.
20.5.1 A closing word
We end where we began, but you see it differently now. In Chapter 5 an agent was little more than a language model that could produce text. Across Part 2 we turned that model into a reasoner, gave it tools and memory, and taught it to plan. In Part 3 we drew the line between workflows and agents, learned the patterns that tame complexity, and built real systems with LangGraph, the OpenAI Agents SDK, and multiple cooperating agents. In Part 4 we did the unglamorous, essential work of making those systems trustworthy — evaluating them, observing them, guarding them, and deploying them at cost. And in Part 5 we watched agents step off the screen and into the world, and stood, finally, at the edge of what is known.
The throughline of every one of those chapters was a single piece of judgment: start simple, and add capability only when the problem earns it. That principle is what separates a demo from a system, and it is the most durable thing you can carry forward, because it will still be true long after any particular model or framework in these pages has been replaced.
The frontier in this chapter is not a wall marking where the subject ends; it is a shoreline marking where your work begins. You now understand agents from the inside — from a single token of reasoning to a fleet of cooperating systems — and the open problems on that shore are not spectator sports but invitations. Go build carefully, measure honestly, and keep capability and control rising together. The next chapter of this story is yours to write.