8 Workflows vs. Agents
“Civilization advances by extending the number of important operations which we can perform without thinking about them.”
— Alfred North Whitehead, An Introduction to Mathematics
After this chapter you will be able to decide, for a given task, whether to use a predefined workflow or a model-driven agent, and how to combine the two.
8.1 Opening intuition
The last three chapters gave an LLM a great deal of power. We saw what it can reason about, we gave it hands, a book, and a notebook, and we taught it to think, act, reflect, and search. It would be natural to conclude that the answer to every problem is now “build an agent and let it figure things out.” This chapter exists to talk you out of that conclusion. The most consequential design decision in this whole field is often not how to make an agent clever, but whether to use a free-ranging agent at all, and surprisingly often, the right answer is not to.
We first met this fork in the road all the way back in Section 1.4, and now we can treat it properly. The single question that separates the two paths is this: who owns the control flow: you, or the model? Picture the difference between a railway and a taxi. A railway follows a fixed track laid down in advance; every train takes the same route, which is exactly why it is so dependable and easy to reason about, and exactly why it can never take you somewhere the track does not already go. A taxi is the opposite. You give the driver a destination and hand over control of the route; they decide which turns to take, reroute around a traffic jam, and improvise when the road is closed. That flexibility is precisely what you want when the journey is unpredictable, and precisely what you do not want when a fixed, well-understood route already gets you there every time.
That is the whole tension of this chapter in a picture. A workflow is the railway: you, the developer, lay down the steps in advance, and the LLM runs along that track. An agent is the taxi: you hand the model a goal and let it decide the steps for itself. Neither is better in the abstract; they are tools for different jobs. The skill this chapter builds is knowing which one a given problem is asking for and, because real systems are rarely pure, how to combine them so that most of your system enjoys the predictability of rails while a few carefully chosen stretches get the freedom of a driver. We begin by making the two definitions precise.
8.2 Two ways to build with LLMs
The taxi-and-railway picture has a precise counterpart in how practitioners talk about these systems. Anthropic, drawing on work with dozens of teams building LLM systems in production, groups everything under the umbrella of agentic systems but draws one sharp architectural line through the middle of it [1]. On one side are workflows: systems where LLMs and tools are orchestrated through predefined code paths that you, the developer, wrote. On the other are agents: systems where the LLM dynamically directs its own process and tool usage, keeping control over how it accomplishes the task. The dividing line is exactly the one we drew: whether the sequence of steps is fixed in your code or decided by the model at run time.
It helps to make this concrete. Imagine a system that takes a customer email, drafts a reply, and translates it into the customer’s language. As a workflow, you would write three steps in code: call the model to classify the email, call it again to draft a reply, call it a third time to translate. The path is fixed (always classify, then draft, then translate), and the LLM is doing the work at each station, but your code is driving the train. As an agent, you would instead hand the model the goal (“handle this customer’s email”) along with tools to look up orders, issue refunds, and send replies, and let it decide what to do: maybe it looks up the order, realizes a refund is warranted, issues it, and only then writes a reply, a sequence you never spelled out. Figure 8.1 puts the two side by side.
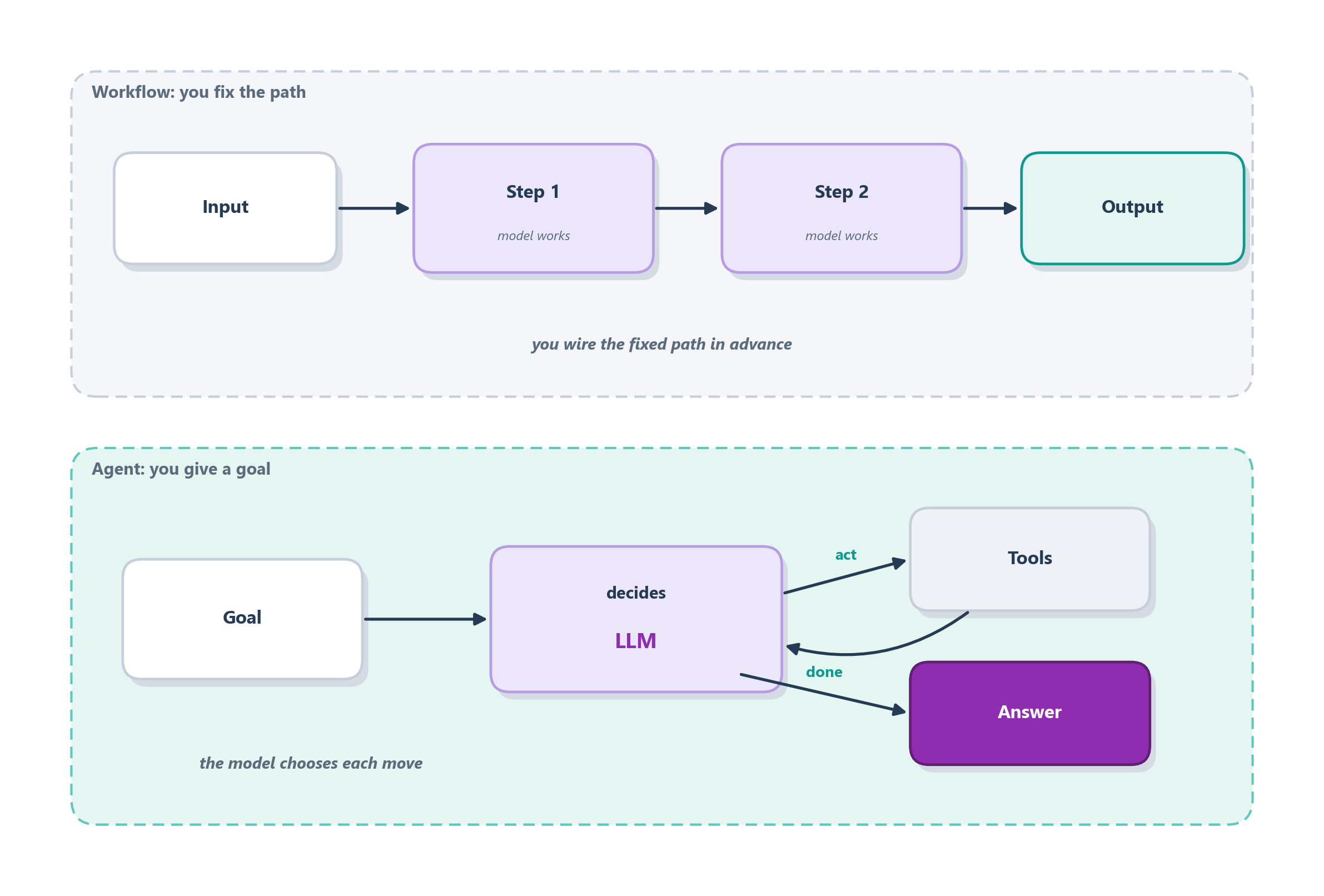
Two things are worth noticing before we go further. First, both are agentic systems in the loose sense that both put a language model at the heart of the work; the distinction is not “smart versus dumb” but “who decides the order of operations.” Second, and this is the point the rest of the chapter turns on, the augmented LLM from Chapter 6 is the building block in both cases. A workflow is several augmented-LLM calls wired together by your code; an agent is a single augmented LLM placed inside the reasoning loop from Section 7.5 and handed the wheel. The difference lives entirely in where the control flow comes from, and that difference has real, practical consequences. It is time to weigh them.
8.3 When to choose which
Now that the two options are clearly drawn, how do you pick? The honest starting point is a piece of advice that sounds almost too plain to be useful, and yet it is the single most important guideline in the practice of building these systems: find the simplest solution that works, and add complexity only when it demonstrably earns its place [1]. Very often the simplest solution is not an agent, and sometimes it is not even a workflow: a single well-crafted LLM call, given the right context and a couple of examples, is enough for a great many tasks. The instinct to reach straight for a fully autonomous agent is the most common and expensive mistake newcomers make.
The reason to hesitate is that autonomy is not free; it is a trade. When you hand the model the control flow, you buy flexibility, the ability to handle inputs you never anticipated and to find paths you never hard-coded, but you pay for it in three currencies. You pay in predictability, because a system that decides its own steps will not do the same thing twice, which makes it harder to test and harder to reason about. You pay in cost and latency, because an agent that loops for many turns makes many model calls where a workflow would make a fixed, small number. And you pay in exposure to compounding errors, because in a long autonomous run a mistake in step three becomes the input to step four, and small errors snowball into large ones, exactly the risk we flagged when we first opened up the reasoning loop. Table 8.1 lays the trade-offs out side by side.
| Consideration | Workflow (you drive) | Agent (model drives) |
|---|---|---|
| Control flow | Fixed in your code | Decided by the model at run time |
| Predictability | High, same path every time | Lower, varies with input and run |
| Cost & latency | Low and bounded | Higher and open-ended |
| Best for | Well-defined, decomposable tasks | Open-ended tasks with no fixed path |
| Main risk | Too rigid for messy inputs | Compounding errors; harder to debug |
Read the table as a single rule of thumb. Workflows win when the task is well-defined, when you can look at it and already know the steps, when you want the same behavior every time, and when predictability and cost matter more than adaptability. Agents win when the task is genuinely open-ended, when you cannot predict how many steps it will take or what they will be, when the path depends on what the model discovers along the way, and when you have enough trust in the model’s judgment (and enough guardrails) to let it operate on its own [1]. A tax-filing pipeline with fixed, auditable stages wants to be a workflow. A coding agent asked to fix an unfamiliar bug across an unknown number of files, where you truly cannot script the path in advance, is a natural fit for an agent. The question to keep asking is not “how capable is the model?” but “does this task actually need the model to own the control flow?” Most of the time, part of it does and part of it does not, which is why the systems that work best in practice are rarely pure.
8.4 Autonomy is a trade, not an upgrade
We have twice now called autonomy a trade and hurried past it. The phrase deserves to sit at the center of its own section, because it is the idea that keeps every later decision honest. It is tempting to read the progression from a single call to a workflow to an agent as a ladder, with the full agent perched at the top as the most advanced, most capable design. That reading is wrong, and it is one of the costliest misconceptions in this field. Handing the model the control flow is not a promotion; it is a purchase. You buy flexibility, and you pay for it in predictability, cost, latency, debuggability, and control. An agent is not a better workflow. It is a different bargain.
A helpful way to hold this in your head is a discretionary spending budget. Imagine you have just hired a capable new employee. On their first day you would not hand over the company card with no limit and say “use your judgment on everything.” You give them discretion where their judgment genuinely adds value, such as how to phrase a delicate reply to an angry customer or how to prioritize a chaotic inbox, and you keep firm rules where it does not, such as how expenses are filed, when a refund must be escalated, and which approvals a large purchase needs. Autonomy in a software system works exactly the same way. Every system has an autonomy budget: a limited amount of uncertainty, variation, cost, and operational risk you are willing to tolerate in exchange for letting the model choose its own path. The budget is finite. Spend it only where the flexibility it buys clearly pays for itself.
Figure 8.2 makes the trade visible. As you slide a task rightward toward more autonomy, the thing you are buying (flexibility) does rise, but so does everything on the bill: cost, latency, output variance, and the burden of evaluating and guarding a system that no longer does the same thing twice.
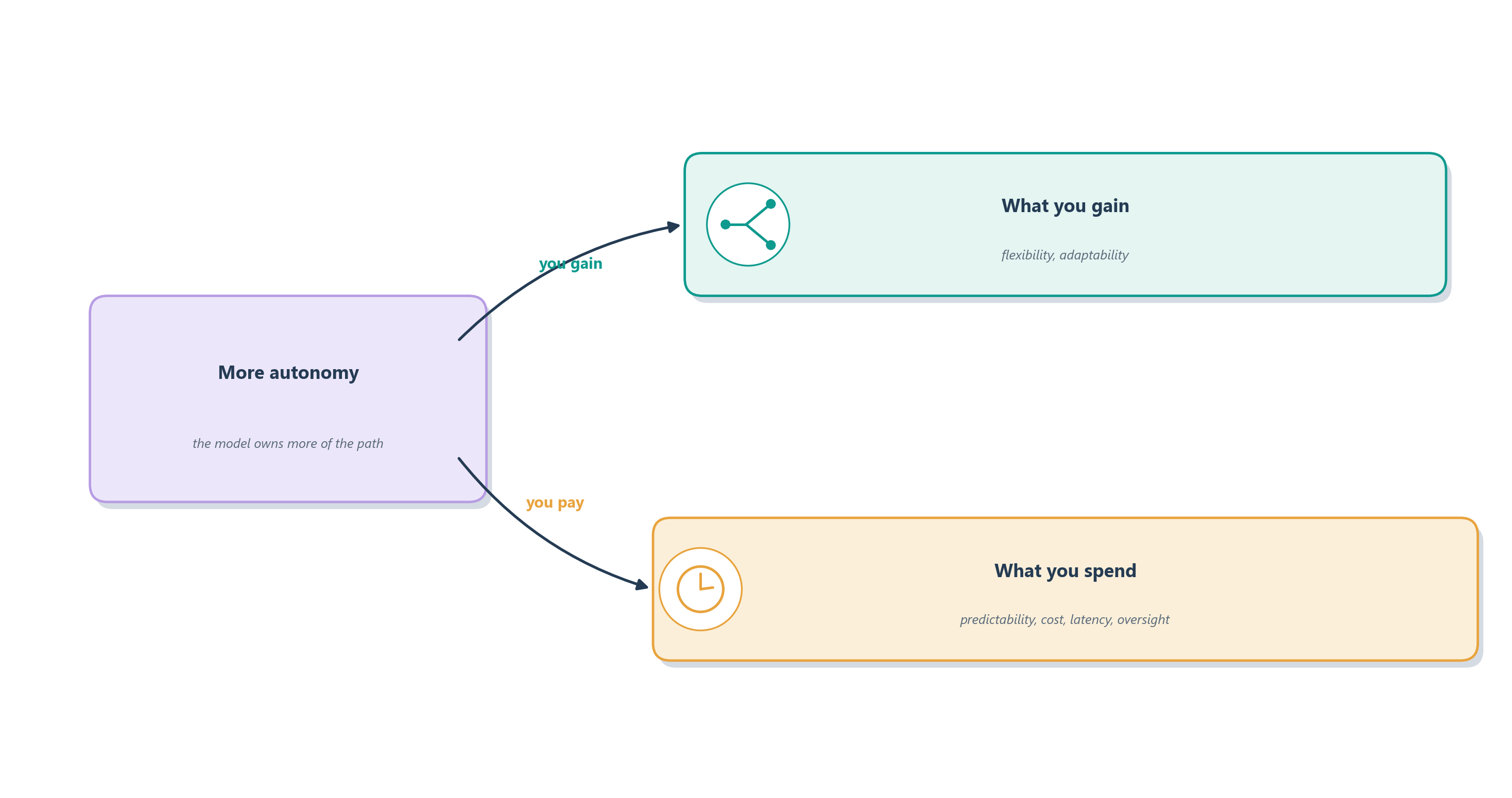
The rest of this section is just two questions asked with that budget in mind. When does a task genuinely earn the autonomy you would spend on it, and when does it deserve less than your instinct wants to give?
8.4.1 When a task earns more autonomy
Some work quietly refuses to be scripted, and you can feel it the moment you try to write it down. You sit to list the steps and the list falls apart before the third line, because the third step depends on what the first two uncover. That is the clearest sign a task has earned some autonomy: the path cannot be fixed in advance. You know the destination but not the route, because the route is discovered by walking it, and each observation along the way quietly rewrites what should happen next. The right third action simply does not exist until the results of the first two are in.
That discovery only counts for something if the agent can see where it is going, so the next sign travels close behind: reliable tools and honest feedback are available. An agent needs contact with reality. When its moves can be checked against search results, a database, a failing test, or any other patch of ground truth, a wrong turn is caught and corrected on the next step instead of compounding silently into a confident, elaborate mistake. Autonomy without feedback is not exploration; it is freefall.
There is also the plain economics of attention. Autonomy earns its place when stopping to ask a human at every turn would be too slow or too expensive to bear. If a person has to bless each small decision, you have not built an agent so much as an elaborate way to make someone click approve all day, and you have surrendered most of what the flexibility was meant to buy. Delegating limited judgment becomes worthwhile exactly when the cost of constant oversight outruns the risk of letting the model act.
What makes that delegation safe is a final pair of signs, and both are about consequences. The output can be verified before it acts on the world: a plan can be read, code can be run against its tests, a drafted reply can be checked before it ever reaches a customer. And the environment itself is safe to explore, so a wrong move can be undone, contained, or recovered rather than causing irreversible harm. Verification is the safety net under the tightrope; a reversible environment is soft ground to land on. Together they let an agent wander a little without the wandering ever costing anything real.
Figure 8.3 makes the pattern concrete with an everyday errand. Planning a trip on a fixed script, search flights, book the cheapest, book a hotel, send the itinerary, works right up until a price spikes or a date slips. The adaptive version keeps the same goal but lets each finding steer the next move, looping back to widen the search or to compare a better option. The panel on the right names the six signals that, taken together, make that flexibility worth buying.
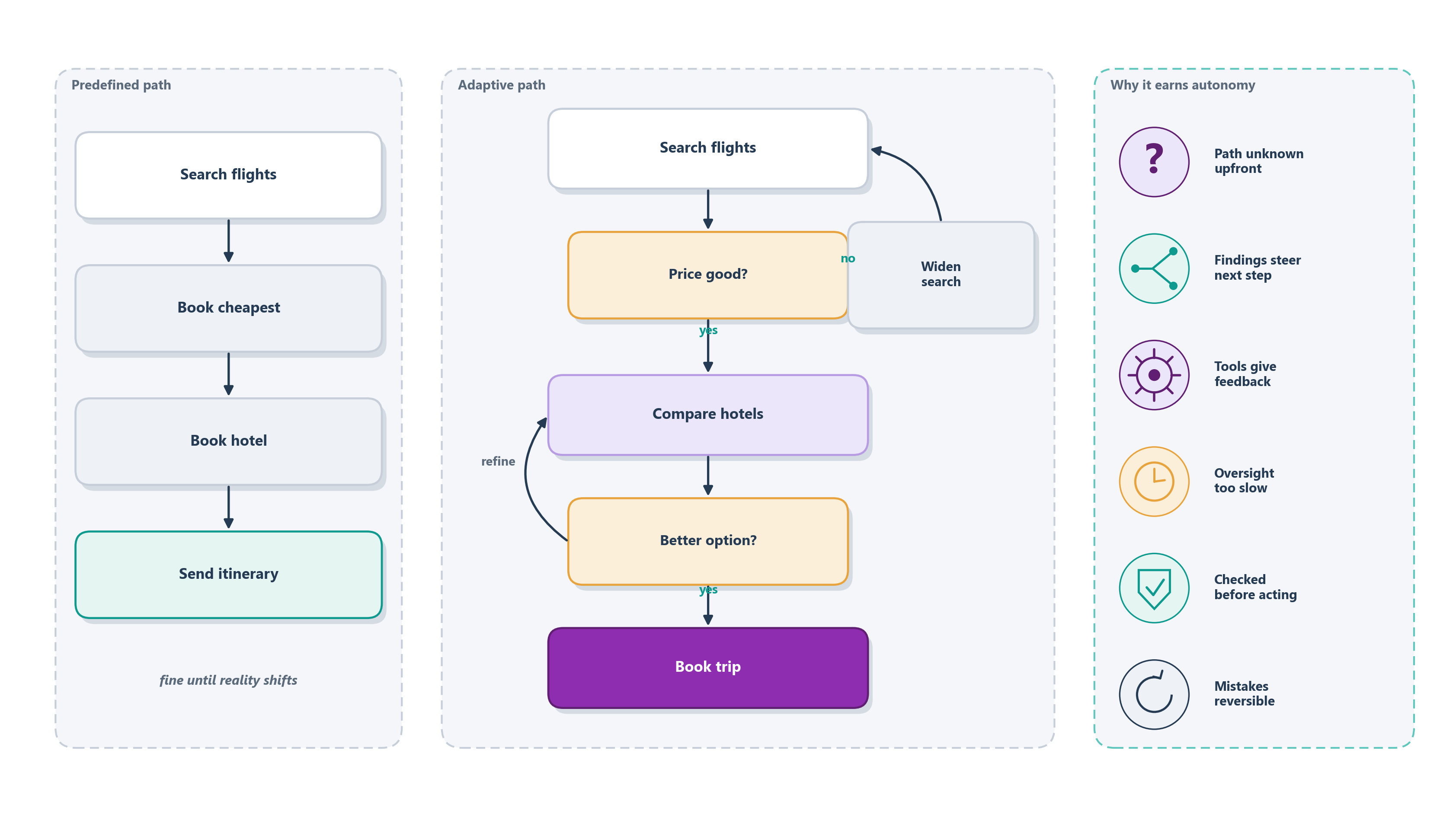
No single one of these is decisive. A task earns autonomy when several hold at once: the path is unknowable, the feedback is honest, the oversight would be too dear, and the mistakes are cheap to catch and cheap to undo. The less predictable the route and the more trustworthy the feedback and the safeguards around it, the more autonomy the work can justify. When they converge, autonomy stops being an indulgence and becomes the right tool, and its extra cost and variance are simply the fair price of handling work no fixed path could. This is the “simplest thing that works” principle read from the other side: you take on the complexity of an agent precisely when the task proves it has earned the spending [1].
8.4.2 When a task deserves less autonomy
The mirror image matters just as much, and it is where good instincts most often betray you, because a task can wear the costume of an agent while quietly deserving far less. The tell is usually that you already know the steps. If you can sit down and name the path from start to finish, writing it down is cheaper, faster, and safer than asking a model to rediscover it on every run. Rediscovery is only a virtue when the path was genuinely unknown; when it was known all along, it is just waste dressed up as intelligence.
Two further signs raise the stakes past mere waste. When the process is regulated or audited, a reviewer must be able to see the same reviewable control flow every time, not a fresh improvisation that happened to work. And when an action is irreversible, such as moving money or deleting records, a single confident mistake cannot be taken back, and confident mistakes are the one thing language models produce reliably. In both cases the right move is to take discretion off the table rather than hope the model uses it wisely.
The last three signs are quieter but no less telling. Sometimes consistency simply matters more than creativity, and two identical requests must return two identical, defensible answers rather than two plausible variations. Sometimes the success criteria are fixed and precise, with exactly one correct outcome, so there is nothing for exploration to find. And sometimes the output must obey strict business rules that are far easier to enforce in a few lines of code than to wish for in a prompt. In each case the flexibility of an agent buys you nothing and costs you the very predictability you were relying on.
This is why seasoned practitioners keep a whole category of deterministic workflows on hand: designs in which your code owns the control flow and the model only does the work inside each step, never deciding the shape of the whole. That is the right choice when the sequence of steps is known ahead of time, when you need explicit guardrails over the system’s behavior, or when compliance and auditability demand a control flow a human can review [2]. Read the two lists together and a single rule emerges: the more unknowable the path and the more forgiving the mistakes, the more autonomy a task can justify; the more the path is known and the more a wrong move costs, the less it deserves. Autonomy you decline to spend here is autonomy you still have, ready for the work that truly needs it.
8.5 Start from the process, not the agent
Knowing how to spend an autonomy budget is only half the discipline. The other half is knowing where to look before you spend anything at all, and here newcomers make a predictable mistake: they start by choosing the technology (“we’re building an agent”) and only then go looking for a problem to point it at. The order should be reversed. Before you decide between a workflow and an agent, map the business process the system is meant to carry out, because the process, not the technology, tells you where autonomy is needed.
Think of how a good architect works. Before choosing steel or glass or where to spend the budget, they study how the building will actually be used: where people enter, how they flow from room to room, where they queue and wait, which doors need security, which corridors carry the heaviest traffic. The materials come last, chosen to serve the way the space will really live. Designing an LLM system is the same. First you trace how the work actually flows, and only then do you choose which stretches run on rails and which get a driver.
Mapping a process spine means answering a short, unglamorous list of questions about the work itself: what triggers the work; what output is ultimately required; what systems are read along the way; what systems are written to; what decisions get made; which of those steps are deterministic (the same every time); which need genuine judgment; where errors can creep in; where a human approval is required; and what success finally looks like. None of these questions mentions models or agents, and that is the point. They describe the terrain, and the terrain is what you are building for.
Run that list over Ledgerly’s support process and a clear spine appears: a ticket arrives, the system identifies the customer and the type of issue, it retrieves the relevant account data, it diagnoses what actually happened, it applies the refund or escalation policy, it drafts a response, and it updates the ticket. Laid out this way, the process almost sorts itself. Identifying the customer, retrieving account data, applying a written policy, and updating the ticket are deterministic steps you already know how to script. Diagnosing a tangled complaint, where the story is ambiguous and the next lookup depends on the last, is the one step that needs judgment. Only after the spine is drawn do you decide which steps stay deterministic and which earn an agentic detour, and that same sorting, deterministic work in code versus open-ended work handed to the model, is the one practitioners reach for again and again [2].
The same mapping exercise, run across a handful of everyday tasks, produces the rough classification in Table 8.2. Read down each column and notice that the sorting tracks how knowable the path is, not how important or impressive the task sounds.
Those four columns are really four stops along a single spectrum of autonomy, sketched in Figure 8.4. As you move from left to right, you hand the model progressively more of the control flow: a single call answers in one shot, a workflow runs a fixed order of steps, a hybrid keeps that order but hands one hard stretch to the model, and an agent is given only a goal and the freedom to find its own path.
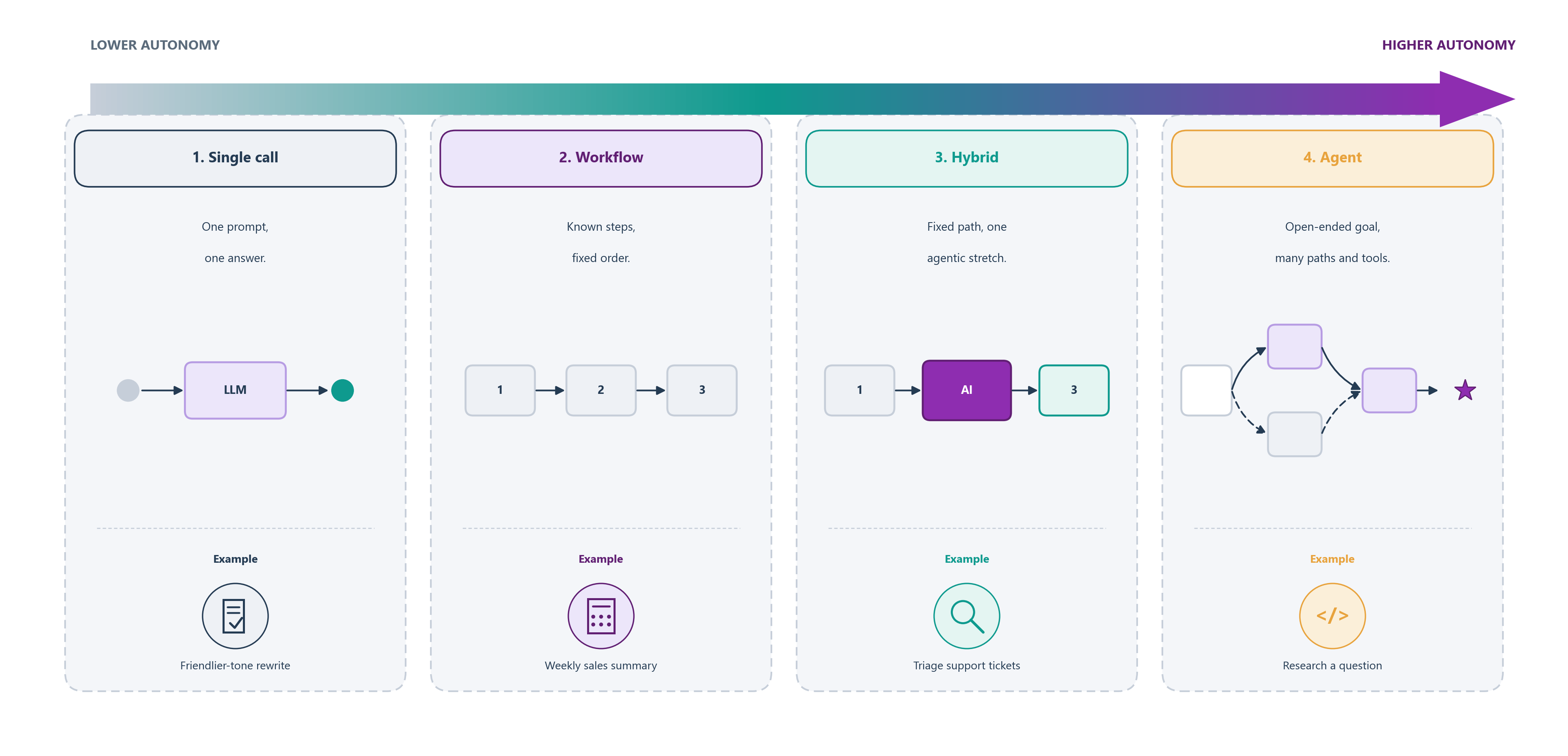
| Single call | Workflow | Hybrid | Agent |
|---|---|---|---|
| Rewrite a message in a friendlier tone | Generate a weekly sales summary from fixed tables | Triage incoming support tickets | Research a business question online |
| Translate a document into five languages | Investigate an unknown billing dispute | Fix an unknown bug across a codebase |
With the terrain mapped and the tasks sorted, we are finally ready to design the systems that live on it, and almost none of them are pure.
8.6 Hybrids: the best of both
If the previous section left you feeling that you have to pick a side, here is the good news: you usually don’t. The workflow-versus-agent choice is not made once for a whole system; it is made per stretch of the journey. The most robust real-world systems are hybrids: mostly laid out on rails, with a short agentic detour wired in exactly where the path genuinely can’t be known in advance. Think of it as a railway line with one stretch where the train is allowed to leave the track, drive itself around an obstacle, and rejoin the rails on the other side. The overall trip stays predictable and cheap, and you spend the expensive freedom of an agent only where it actually buys you something.
A customer-support system is the classic example. Nearly all of it can be a workflow: a fixed pipeline receives a ticket, classifies its topic, looks up the customer’s account, retrieves the relevant help-center articles, drafts a reply, and routes it for sending. Every one of those steps is well-defined, and you want them to run the same dependable way every time; this is railway territory. But suppose a small fraction of tickets are gnarly: a multi-part complaint that touches billing, shipping, and a warranty claim at once, where no fixed path fits. For those, the workflow can hand off to an agentic step (“given this messy ticket and these tools, work the problem until it’s resolved or escalate to a human”) and then fold the result back into the normal pipeline for sending and logging. Figure 8.5 shows the shape.
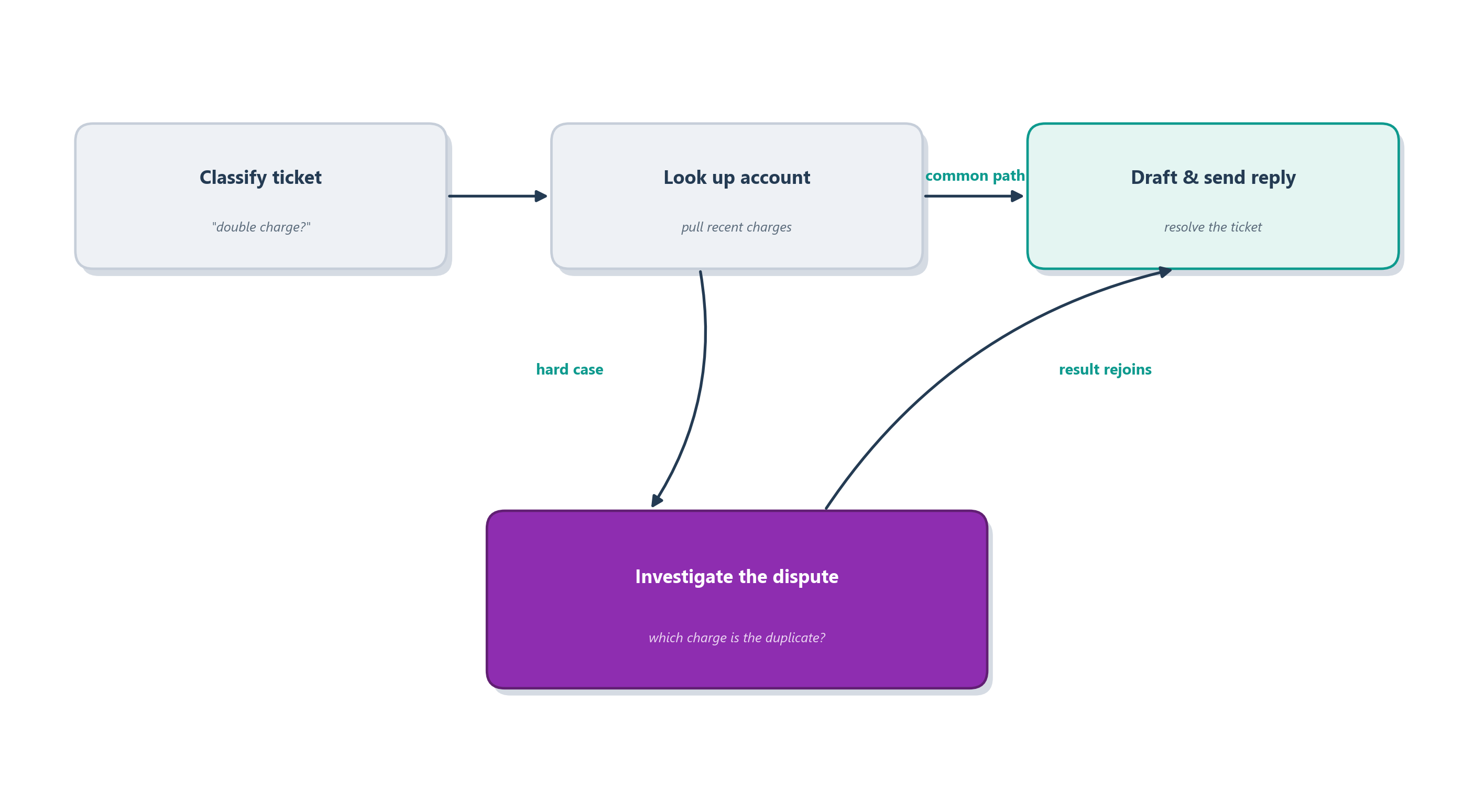
This is the pattern to reach for far more often than a pure agent. It lets you honor the “simplest thing that works” principle at the level of each step rather than the whole system: the 90% of the job that is well-defined stays on rails, and you pay the cost, unpredictability, and compounding-error risk of autonomy only on the 10% that truly needs it. It also makes the system dramatically easier to debug, because when something goes wrong you can usually tell whether the failure was in a fixed step (which you can inspect and reproduce) or in the agentic detour (which you can sandbox and constrain). Designing a good hybrid, then, comes down to a single repeated judgment, namely for each step, do I own the control flow or does the model? That is exactly the decision the next section turns into a checklist.
8.6.1 Hybrid is the mature default, not a compromise
That single repeated judgment gets easier the moment you stop thinking of a hybrid as a compromise. It is tempting to read a hybrid as a timid agent, an autonomous system with its wings clipped, something you would replace with a “real” agent once you trusted the model more. That framing is backwards. In production, a hybrid is usually the mature design, not the training-wheels version of one. It is the shape you arrive at precisely because you understand the task well enough to know which parts deserve autonomy and which do not.
The clarity comes from dividing ownership cleanly. The workflow owns the predictable spine: intake and routing, input validation, guardrails on what may be touched, human approvals, state updates, and every step governed by a known business rule. The agentic step owns the genuinely open parts: ambiguous diagnosis, interpreting unstructured input, open-ended research, handling exceptions nobody scripted, and reasoning about policy over messy, real facts. The agent does its work, produces a result, and hands control back, and the workflow carries that result through the dependable final stages. This is the “one agentic detour” from earlier drawn as a division of labor rather than a diagram: rails wherever the path is known, a driver only across the one stretch that no map covers.
8.6.2 The agentic step needs a contract
Dividing ownership cleanly raises an obvious question: when the workflow calls that agentic step, what exactly is it calling? A well-designed agentic substep is not an open invitation to “go figure it out.” It is a component with a contract, the same way a well-behaved function has a signature, preconditions, and postconditions. The contract is what lets a predictable workflow trust an unpredictable step without inheriting its unpredictability. Table 8.3 lists the fields worth pinning down.
| Contract field | What it pins down |
|---|---|
| Input schema | The exact information the step receives, in a fixed shape |
| Allowed tools | The closed set of tools the step may call, and nothing beyond it |
| Max steps | A hard ceiling on loops or tool calls before the step must return |
| Output schema | The structured result the workflow will parse, not free prose |
| Confidence / uncertainty field | An explicit signal of how sure the step is, so the workflow can react |
| Evidence used | The facts and sources the conclusion actually rests on |
| Stop condition | What “done” means, so the step knows when to return a result |
| Escalation condition | When to hand off to a human instead of deciding |
| Failure modes | What the step returns when it cannot succeed, never a silent guess |
| Human-approval trigger | The conditions under which a person must sign off before acting |
Ledgerly’s diagnosis step shows the contract in the concrete. Its input is the customer’s complaint plus the account ID, the billing period in question, and the invoices already retrieved by the workflow. Its allowed tools are exactly three: a charge lookup, a plan-history lookup, and a policy-document retrieval, and nothing that can move money or close a ticket. Its output is a small structured object: a diagnosis category, the evidence it relied on, a recommended action, a confidence score, and an escalation flag. Notice what the step does not do. It does not issue the refund, it does not close the ticket, and it does not decide policy on its own. It investigates and reports, and the deterministic workflow around it reads that report and decides whether to proceed. The model supplies judgment; the code keeps control.
When you write the contract, resist the temptation to push hard rules into the agent’s prompt. Rules like “refunds above the threshold need a manager’s approval,” “verify identity before sharing account details,” “these fields are required,” “this tool may only be called after authorization,” and “a resolution code must be set before a ticket can close” are business logic, and business logic belongs in code. A prompt is flexible by design, which is exactly why it is the wrong place for a rule that must hold every single time. Code is enforceable; a prompt is a strong suggestion. Keep the enforceable rules in the workflow, and let the agentic step reason only over the parts that genuinely call for judgment.
8.7 A decision guide
Let’s turn everything so far into something you can actually run in your head when you sit down to design a system. The reasoning of this chapter collapses into a short chain of questions, asked in order, from cheapest option to most expensive. Figure 8.6 draws it as a flowchart; the trick is to stop at the first option that works rather than falling through to the bottom out of ambition.
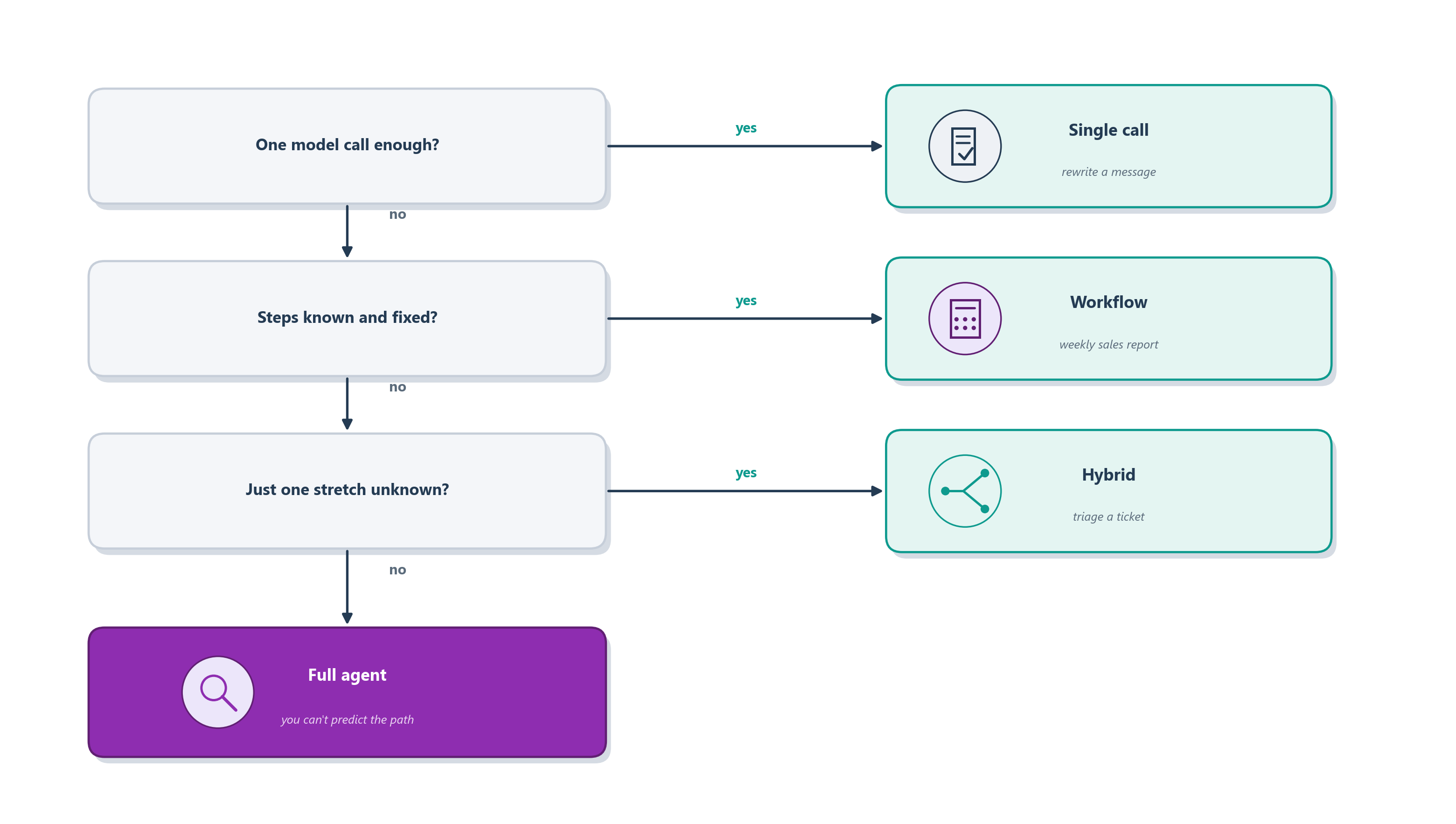
Walk down it slowly, because the order matters. First, ask whether a single well-crafted LLM call can do the job; a surprising amount of work (summarizing, classifying, rewriting) needs nothing more, and reaching for anything heavier is wasted effort. Second, if it takes several steps but you already know what those steps are and what order they go in, you have a workflow: write the path in code and let the model do the work at each station. Third, if you cannot script the whole path but only part of it is genuinely unpredictable, build a hybrid: keep the known stretches on rails and reserve an agentic step for the messy part. Only at the bottom, when the task is open-ended enough that you truly cannot predict the steps in advance, do you hand the model the control flow and build a full agent, and even then you do it with the guardrails and sandboxed testing that autonomy demands.
When you do reach the bottom of the guide and build an agent, treat it as the beginning of the work, not the end. An autonomous system that decides its own steps must be tested in a sandbox, fenced with guardrails on the tools it can touch, and watched in production; the freedom you handed the model is exactly what makes these safeguards non-negotiable. We devote whole chapters to it later: evaluation in Chapter 15 and safety in Chapter 17.
One honest caveat keeps this guide from being the whole story. Choosing that you want a workflow tells you the control flow is yours, but it does not tell you what shape that control flow should take: should the steps run in a chain, branch by routing, fan out in parallel, or loop through a critic? Those recurring shapes are a subject of their own, and they are exactly where we go next.
8.8 The more autonomy you give, the more evaluation you owe
The tip that closed the decision guide made a promise: the freedom you hand the model is exactly what makes testing and guardrails non-negotiable. Before we assemble everything into Ledgerly’s real system, it is worth taking the testing half of that promise seriously, because it follows straight from the autonomy trade. Every unit of autonomy you spend is a unit of evaluation you now owe. A workflow and an agent are not just built differently; they have to be judged differently, and forgetting that is how a demo that dazzled turns into a production system nobody can trust.
The difference is the difference between grading a multiple-choice test and grading a game of chess. On a multiple-choice test you can check each answer in isolation: question by question, the answer is either right or wrong, and the steps do not interact. A workflow evaluates like that. Because you fixed the path, you can inspect each station on its own and ask whether it did its job. An agent is nothing like a multiple-choice test. It is more like a chess game or an open-ended essay, where no single move is right in isolation and you have to judge the whole line of play. The agent acts over many turns, calling tools, modifying state, and adapting based on what it finds, which means a good final answer can come from a reckless path and a bad outcome can hide a sound one. Worse, because each step feeds the next, a small mistake early does not stay small: it becomes the input to the next step, and errors propagate and compound down the trajectory [3]. You cannot judge that by looking only at the last move.
Table 8.4 lays the two styles of judgment side by side. The left column is the step-by-step checking a fixed path allows; the right column is the whole-trajectory judgment an autonomous one demands.
| Workflow evaluation (check each step) | Agent evaluation (judge the whole trajectory) |
|---|---|
| Did each step produce the output the next step expected? | Did it choose a sensible path toward the goal? |
| Did each gate catch invalid intermediate results? | Did it call the right tools, and only those, at the right time? |
| Did the deterministic rules fire when they should have? | Did it stop at the right moment, neither too early nor too late? |
| Did each handoff pass the correct data forward? | Did it recover from an error instead of compounding it? |
| Did it satisfy the task’s constraints and avoid unsafe actions? |
Because agents resist step-by-step grading, practitioners have built a small, sturdy vocabulary for evaluating them, and it is worth meeting here so the pattern is familiar later. An evaluation is assembled from four parts. A task is a single test with defined inputs and a success criterion. A trial is one attempt at that task, and because an agent’s output varies from run to run, you repeat trials rather than trusting a single lucky pass. A grader is the logic that scores some aspect of a trial, and graders come in three flavors: code-based checks, a model acting as an LLM judge, and a human reviewer. And every trial leaves two things worth distinguishing: the transcript, meaning the full record of what happened including every tool call and reasoning step, and the outcome, meaning the final state the agent left behind in the world [3]. The usual guidance is to grade the outcome rather than insist on one exact path, since many good paths can reach the same right result, while still watching transcript-level signals such as which tools were used and how many turns it took, because for an agent how it got there is part of whether you can trust it [3].
This is only a first taste; evaluation earns a chapter of its own in Chapter 15, and the guardrails that fence an agent’s actions get theirs in Chapter 17. The point to carry forward is simply the equation in this section’s title. Autonomy and evaluation are two sides of one coin: the more of the control flow you hand the model, the more of the judging you take on in return. With that debt acknowledged, we can finally assemble Ledgerly’s system and watch the whole chapter come together on a single hard ticket.
8.9 Case study: the Ledgerly support agent
Where we left off, Section 6.7 gave the Ledgerly agent hands, an open book, and a notebook. Now we decide when to let it use that freedom, because the customer-support system described just above is Ledgerly’s, and the hybrid shape from Section 8.6 is exactly the architecture we first sketched in Section 1.8. The judgment this chapter asks for, namely “for each request, do I own the control flow or does the model?”, is what turns that sketch into a concrete design.
Run Ledgerly’s real traffic down the decision guide from Section 8.7 and it sorts itself into three lanes. Most tickets are a single well-crafted call: “email me invoice #4471” or “what plan am I on?” need one lookup and one reply, so reaching for anything heavier would only add latency. A smaller set are known multi-step workflows: a refund has a fixed procedure every time (look up the charge, check it against the policy, issue the refund if it qualifies, then reply), so we script that path in code and let the model do the work at each station. And a stubborn minority are genuinely open-ended: the multi-part complaint that tangles a double charge, a failed plan change, and a warranty question at once, where no fixed path fits. Only that last lane hands the model the wheel.
Drawing the line this way keeps Ledgerly honest about the trade from this chapter. The predictable majority stays on rails, cheap and auditable, and the expensive freedom of an agent, along with its compounding-error risk, is spent only on the fraction that truly needs it. Notice that the refund lane stays a workflow even though it moves money, because its steps never change. What makes a request agentic is unpredictability, not importance.
| Example ticket | Who owns the control flow | Lane |
|---|---|---|
| “Email me invoice #4471.” | you: one fixed step | FAQ, a single call |
| “Refund my duplicate charge.” | you: a fixed procedure | Refund, a workflow |
| “Two wrong charges and a failed plan change at once.” | the model: no fixed path | Complex, an agent |
8.9.1 Workflow, agent, or hybrid for one hard ticket
The three lanes are tidy in a table, but the real lesson of this chapter only lands when you watch a genuinely hard ticket move through the system. Take the kind of message that lands in Ledgerly’s complex lane: “I changed my plan last month and now I see two charges. Why did this happen, and can you refund one of them?” It is ambiguous (the second charge might be a duplicate or a legitimate proration), it touches money, and its resolution depends on facts nobody has looked up yet. It is exactly the sort of ticket that tempts an engineer to reach for a full agent.
That temptation is the wrong move, and it is worth being precise about why. The bad design hands the whole ticket to an autonomous agent and lets it decide everything: what data to fetch, what the policy means, whether a refund is owed, how much, then executes the refund and closes the ticket. Every one of those is a place where the model’s judgment is now load-bearing for an irreversible, money-moving action, and the compounding-error risk we keep returning to now has real dollars attached. Handing that much control to a model is not sophistication; it is spending your entire autonomy budget on a step that never asked for it.
The better design is the hybrid this chapter has been building toward: a deterministic workflow that wraps a single agentic detour, with the money and the rules kept firmly in code. Figure 8.7 traces the eight stages.
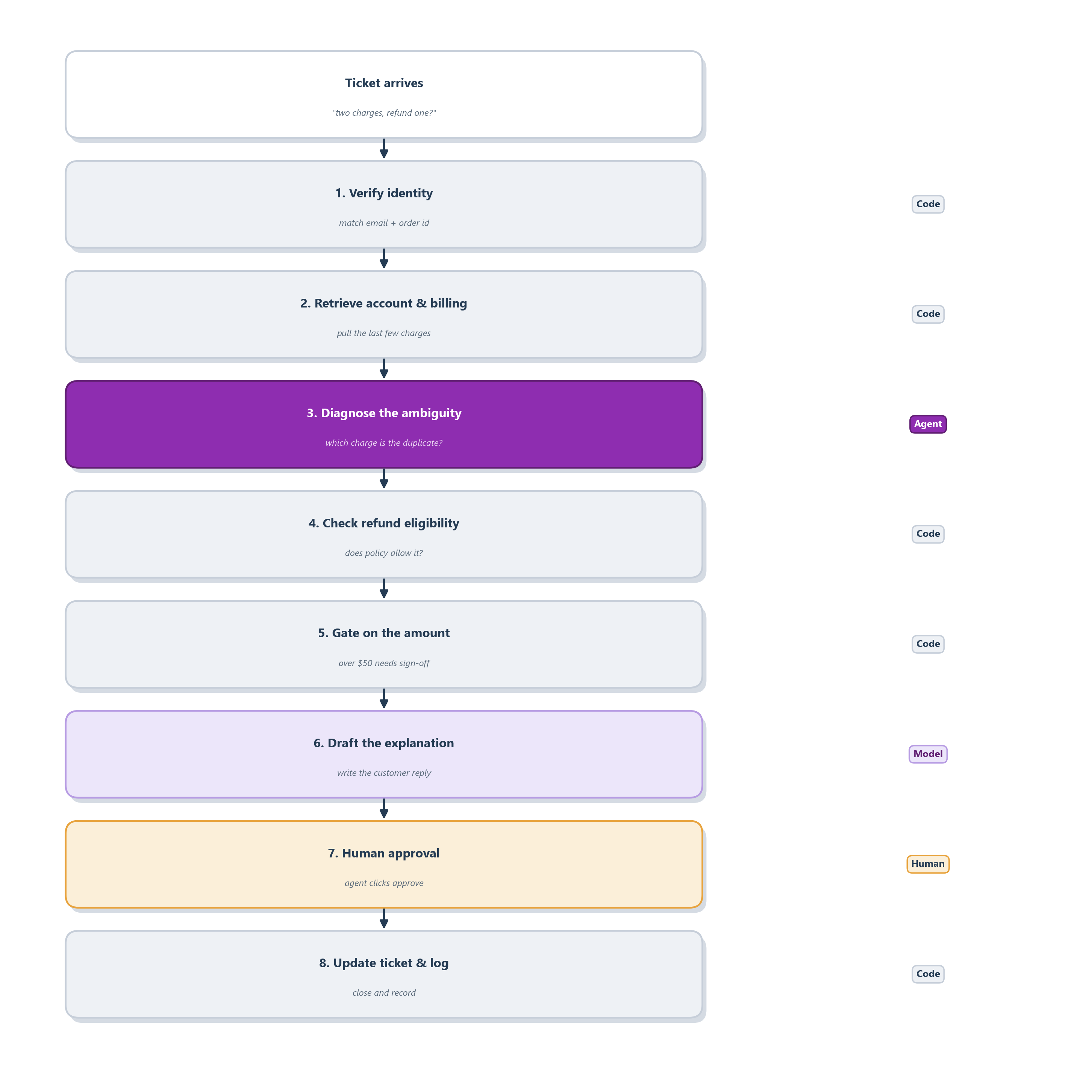
Walk the stages and notice how little the model actually gets to decide. The workflow verifies identity and retrieves the account and billing period, because those steps are the same every time. Only then does control pass to the agentic diagnosis step, whose job is the one genuinely open question: given these charges and this plan change, what actually happened? It investigates and returns a structured verdict, and there it stops. The workflow takes over again to run the deterministic refund-eligibility checks and to gate the refund by amount and approval policy, so no refund above the threshold slips through without a human. The model is invited back to draft the customer explanation in warm, clear prose, a job it is genuinely good at, but a human approves the actual refund before it happens, and the workflow updates the ticket and logs the outcome for the audit trail. The agent touched exactly one stage: the one where the path was unclear.
That is the whole chapter compressed into a single pipeline. Use the agent where the path is unclear; use the workflow where the rule is known. One agentic step, wrapped in deterministic rails, gives you the flexibility to handle a messy complaint without giving up the predictability, auditability, and control that a money-moving process demands.
A hybrid that pauses for human approval, as this one does at stage seven, needs durable state. The reviewer might approve minutes or hours after the diagnosis ran, and they must be approving this refund, still attached to the exact evidence and account snapshot that justified it. If the intermediate state is lost when the process pauses, the approval floats free of the facts that created it, which is precisely the kind of gap an auditor will find. Durable execution, with automatic checkpointing between steps, is what keeps the human’s decision connected to the evidence [2].
We now have three lanes but no machinery to run them. Section 9.10 assembles Ledgerly’s support desk from the handful of recurring patterns this next chapter introduces.
The atom from Section 6.7 now has a shape:
- A router reads each ticket and picks a lane by who owns the control flow.
- FAQ lane: a single well-crafted call.
- Refund lane: a fixed workflow (look up, check policy, refund, reply).
- Complex lane: an agent, reserved for open-ended tickets.
- Every lane draws on the Ch6 faculties: bounded tools, grounded retrieval, memory.
8.10 Summary
This chapter drew the most important line in the design of LLM systems and gave you a way to place any task on the right side of it.
- The real question is who owns the control flow, you or the model. A workflow is a railway: you fix the steps in code and the model does the work at each station. An agent is a taxi: you hand the model a goal and it decides the steps itself [1].
- The augmented LLM is the building block of both. A workflow wires several augmented-LLM calls together with your code; an agent puts one augmented LLM inside the reasoning loop and hands it the wheel. The difference is only where the control flow comes from.
- Autonomy is a trade, not an upgrade. Handing the model the control flow buys flexibility but costs predictability, raises cost and latency, and exposes you to compounding errors. Start with the simplest thing that works and add complexity only when it earns its place.
- Workflows suit well-defined tasks; agents suit open-ended ones. If you already know the steps, write them down. Reach for a full agent only when you genuinely cannot predict the path in advance.
- The best real systems are hybrids. Keep most of the work on rails and reserve an agentic step for the small part that truly needs it: you get predictability where you can and flexibility where you must.
- Every system has an autonomy budget. Autonomy buys flexibility and spends predictability, cost, latency, and control, so treat that trade as a finite budget and spend it only where flexibility clearly pays for itself.
- Start from the process, not the agent. Map the business process first (its triggers, reads, writes, decisions, and approvals), and only then decide which steps stay deterministic and which earn an agentic detour [2].
- A hybrid is the mature default, and its agentic step needs a contract. The workflow owns intake, validation, rules, approvals, and state; the agentic step owns the ambiguous, open-ended part, bound by a contract (input and output schema, allowed tools, stop and escalation conditions). Keep enforceable business rules in code, not in prompts.
- The more autonomy you give, the more evaluation you owe. A workflow can be checked step by step; an agent must be judged as a whole trajectory, because it acts over many turns and its errors compound, so grade the outcome while still watching the path [3].
With the decision settled, the next question is one of form: when you do build a workflow, what shapes does its control flow tend to take, and what does a well-structured agent loop look like up close? Those recurring patterns (chaining, routing, parallelization, reflection, and more) are the subject of Chapter 9.
8.11 Exercises
- Sort the tasks. For each of the following, decide whether you would build a single LLM call, a workflow, a hybrid, or a full agent, and justify your choice using the decision guide: (a) translating a document into five languages; (b) triaging incoming bug reports and filing them to the right team; (c) researching an open question by browsing the web until it finds a defensible answer; (d) generating a weekly sales summary from a fixed set of tables.
- Find the agentic step. Take a mostly-predictable system you know (or invent one) and identify the single stretch where the path genuinely cannot be known in advance. Sketch it as a hybrid in the style of Figure 8.5, with a workflow around one agentic detour.
- Price the autonomy. Explain in your own words the three “currencies” you spend when you give the model the control flow, and describe a concrete situation in which the flexibility you gain is clearly not worth the price.
- Stress-test the guide. Construct a task that seems open-ended at first glance but that, on reflection, decomposes into a fixed set of known steps. What made it look like an agent problem, and what revealed it was really a workflow?
- Write a contract. Pick a task that genuinely needs an agentic step, then write that step’s contract using the fields in Table 8.3: its input and output schema, its allowed tools, its stop and escalation conditions, and the trigger for human approval. Which rules did you deliberately keep in the surrounding workflow rather than the prompt, and why?
- Map a process spine. Take a real process you understand (onboarding a customer, reviewing an expense, publishing an article) and map its spine using the questions in
- Mark each step as deterministic or judgment-needing, and circle the single step, if any, that truly earns autonomy.
- Judge the trajectory. Explain why an agent needs trajectory-level evaluation and not just a final-answer check. Give one concrete trajectory check (a signal about the path the agent took) that a final-answer-only test would miss entirely, and say what failure it would catch.