18 Deployment & Cost
“Premature optimization is the root of all evil.”
— Donald E. Knuth
After this chapter you will be able to reason about the latency, cost, and reliability trade-offs of running agents in production.
18.1 The meter is running
Our agent is now evaluated, observable, and guarded — but it still lives on a workbench. Turning it into a service that real users depend on forces us to confront the trade we have gestured at all book long and can no longer avoid: an agent’s autonomy is expensive. Every step of reasoning is a call to a large model, which costs both money and time, and an agent may take many steps to finish a job. This chapter is about managing that expense deliberately rather than discovering it on an invoice.
The cleanest way to feel it is to return to the taxi from Chapter 8. A workflow, we said, is like a train on fixed rails — and its cost is like a train ticket: a known, fixed price for a known route. An agent is like a taxi, and it comes with a taxi’s defining feature: the meter is running. Every moment the agent spends thinking, every extra tool call it decides to make, every loop back to reconsider, ticks the meter upward in tokens and in seconds the user waits. That flexibility is exactly what makes the taxi valuable — it can go where no train track leads — but it also means the fare is variable and, if you are not watching, alarmingly large. Figure 18.1 shows the meter climbing across a run.
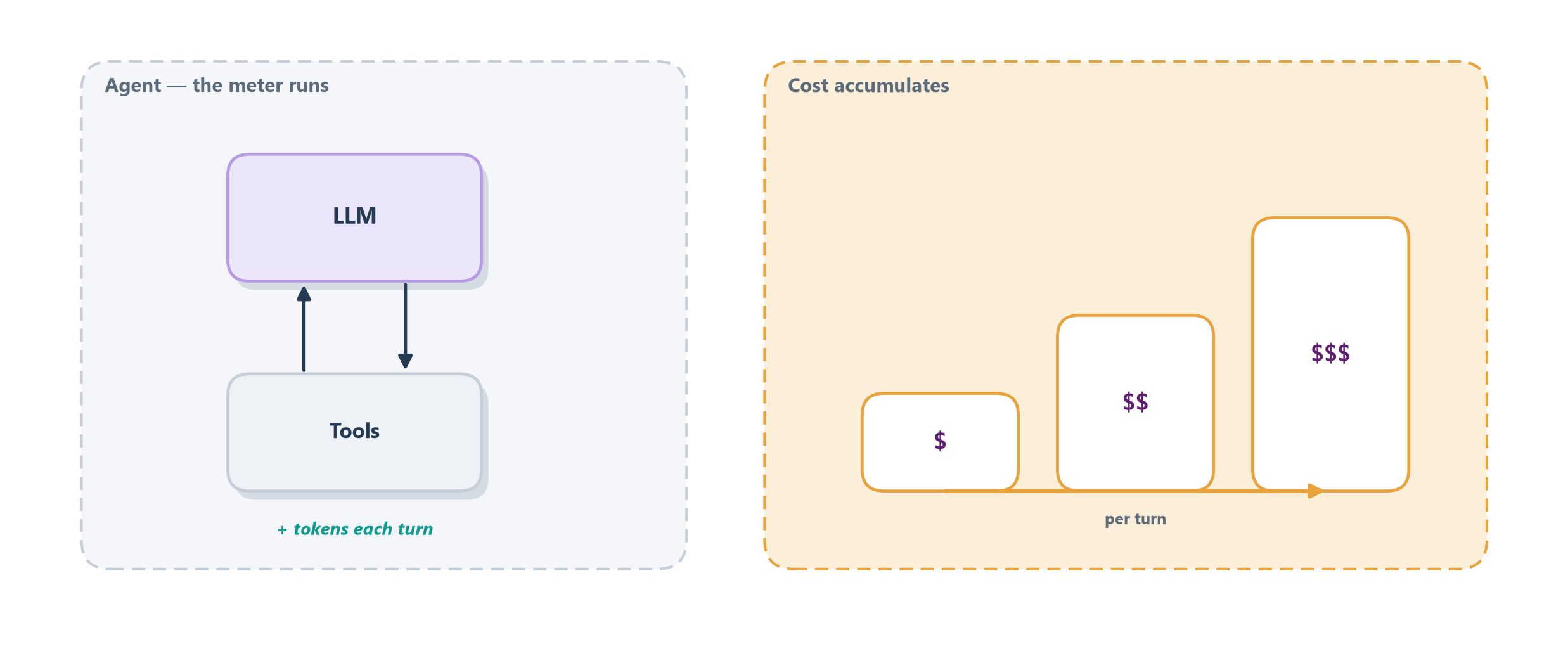
This is the practical face of a principle Anthropic states plainly: agentic autonomy trades cost and latency for capability, and you should reach for it only when the task justifies the fare [1]. But “use it only when justified” is a design-time decision; once you have decided an agent is warranted, you still have to run it well. That means pulling three sets of levers — the ones that control cost and latency, the ones that keep the service reliable when the world misbehaves, and the ones that let it scale to many users at once. We start with the meter itself: the levers that make each run cheaper and faster.
18.2 Levers for cost and latency
Once the meter is running, the engineer’s job is to make each run cheaper and faster without making the agent worse — and there are four reliable levers for it. The unifying idea is the one any careful household or business already knows: don’t pay premium prices for economy work. A hospital does not send every patient to its top surgeon; it triages, matching the level of resource to the level of need. Running agents affordably is the same discipline applied to model calls.
The first and biggest lever is model routing, the deployment-time face of the routing pattern from Section 9.3: use a small, cheap, fast model for the many easy steps — classifying a request, formatting an answer — and reserve the large, expensive model for the genuinely hard reasoning. Since a big model can cost many times more per token than a small one, sending only the hard steps its way can cut cost dramatically while barely touching quality. The second lever is caching: if the same question or the same sub-computation recurs, store the answer and serve it again for free rather than paying the model to redo it — the same “look it up instead of recomputing” instinct behind the memory of Section 11.3. The third is batching, grouping many independent requests into one call where the provider allows it, trading a little latency for a lot of throughput. The fourth is limiting turns — capping how many reasoning-and-tool loops the agent may take, which is the stop condition from Section 17.4 seen now as a cost control, not just a safety one: an agent that cannot loop forever cannot run up an unbounded bill. Figure 18.2 gathers the four.
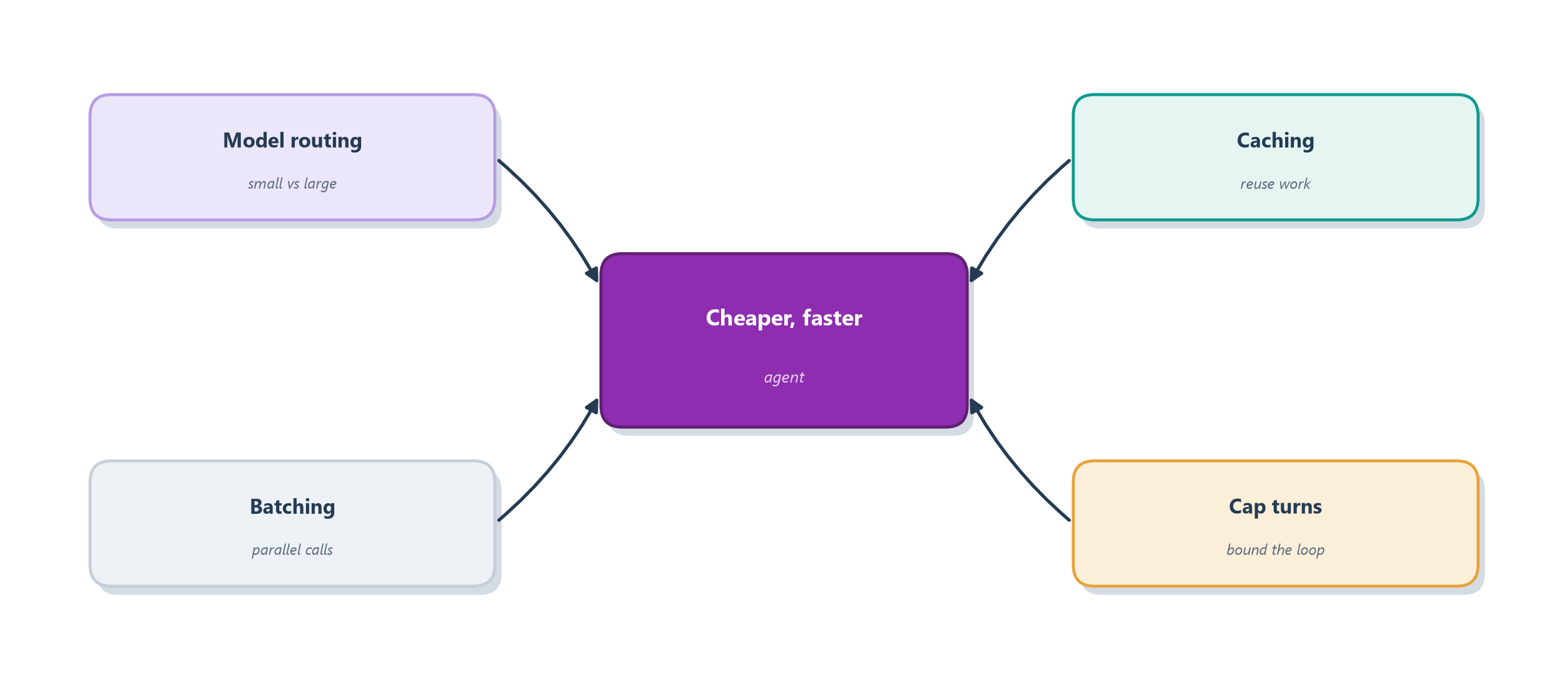
The theme tying these together is that most of an agent’s cost comes from treating every step as equally expensive when it is not. Match the model to the difficulty, avoid repeating work you have already done, group what can be grouped, and refuse to let a runaway loop bill you forever — and the same agent that looked ruinously expensive becomes practical to run at scale. Cost and speed are only half of production, though. An agent that is cheap and fast but falls over the moment a tool times out is not a service anyone can trust, which brings us to reliability.
18.3 Reliability when the world misbehaves
Production is a hostile environment for a program that depends on external services. The model API will occasionally be slow or return an error; a tool’s server will time out; a network hiccup will drop a call mid-flight. An agent that assumes everything always works will fail the first time reality proves otherwise, so reliability engineering is about building an agent that degrades gracefully instead of collapsing. The analogy is a good delivery service: when a road is blocked it reroutes, it does not wait forever at a closed bridge, and — crucially — it never delivers the same package twice.
Four techniques do most of the work, and three are standard resilience patterns adapted to agents. Retries handle transient failures: when a call fails for a fleeting reason, try again, ideally with exponential backoff so a struggling service is not hammered. Timeouts prevent hanging: every external call gets a deadline, so a tool that never responds does not freeze the whole agent — the closed-bridge rule. Stop conditions, from Section 17.4, are the circuit breaker: when something is clearly going wrong, halt rather than thrash. The fourth technique is the one agents make essential rather than merely nice — idempotency. Because agents take real actions in the world, a naive retry is dangerous: if “charge the customer $50” times out after the charge went through but before the confirmation came back, retrying would charge them twice. The fix is to make actions idempotent — tag each with a unique key so the same request, repeated, has the same effect as doing it once. Figure 18.3 wraps a single tool call in these protections.
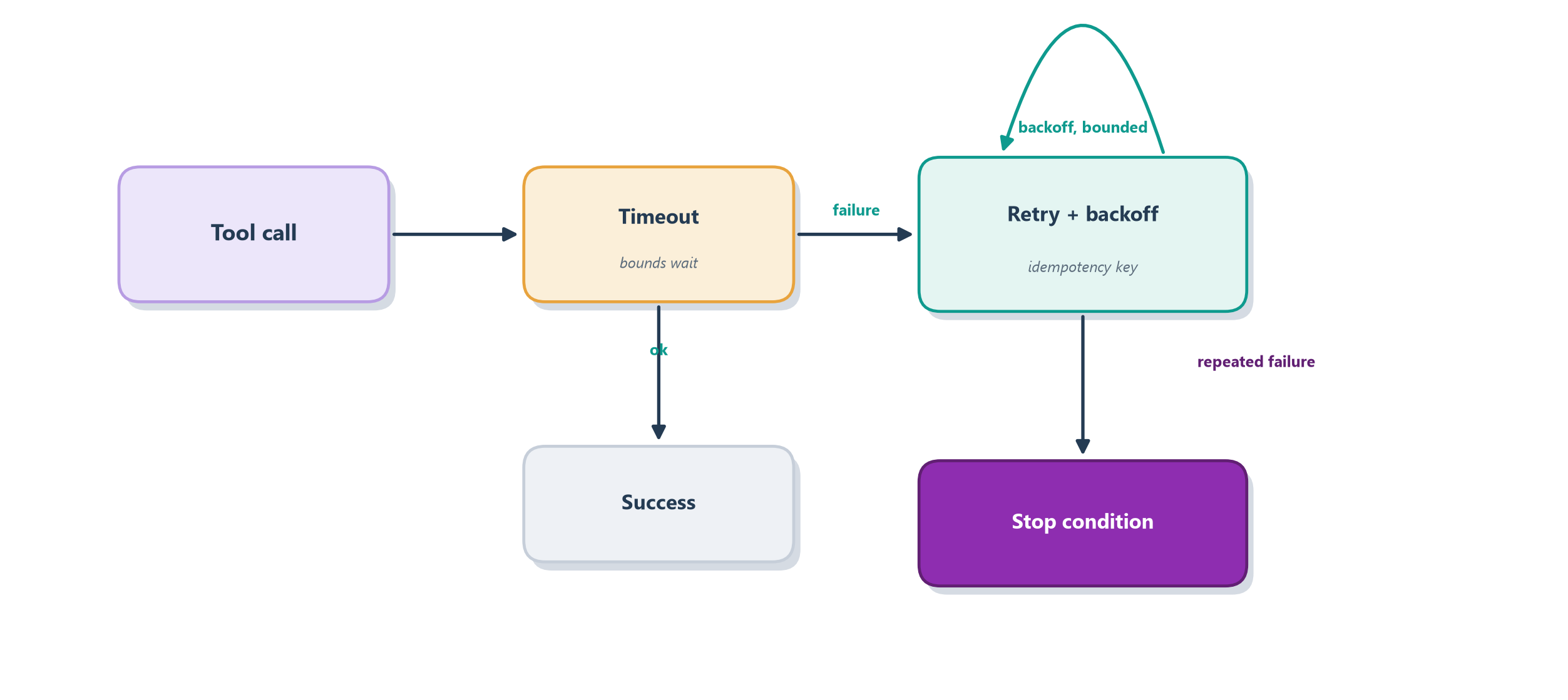
The mindset shift these patterns encode is to treat failure as normal and design for it, rather than treating it as an exception you hope never comes. This complements the two failure disciplines we already have: where evaluation asked “is the agent’s judgment good?” and safety asked “can it be attacked?”, reliability asks “does it hold up when its dependencies wobble?” Together they make an agent trustworthy. What remains is the last production question — not how one run behaves, but how the system behaves when thousands of runs arrive at once.
18.4 Scaling and operations
One agent serving one user on a laptop is a demo; a service serving thousands at once is a different engineering problem, and three concerns dominate it. The analogy is scaling a restaurant from a single table to a full dining room on a busy night: you need many staff working in parallel, you cannot exceed what the kitchen can produce, and every order must be tracked somewhere central so any waiter can pick it up.
The first concern is concurrency. Agent runs are long and spend most of their time waiting — on the model, on tools, on the network — so a server should handle many runs at once rather than one at a time, which is why agent systems lean heavily on asynchronous, non-blocking execution. The second is rate limits. Model providers cap how many requests and tokens you may use per minute, and a busy service will hit those ceilings, so you must queue and throttle your own traffic and handle the provider’s “too many requests” responses gracefully rather than letting them cascade into user-facing errors. The third, and the one most particular to agents, is state persistence. An agent is stateful — it carries memory and, as we saw in Section 12.3, checkpoints of its progress. If that state lives inside one server’s process, you can never add a second server, because the next request might land on a machine that has never heard of this conversation. The fix is to externalize state into a shared store, exactly the role the checkpointer and memory systems of Chapter 11 were designed to fill, so any worker can resume any run. Figure 18.4 shows the resulting shape.
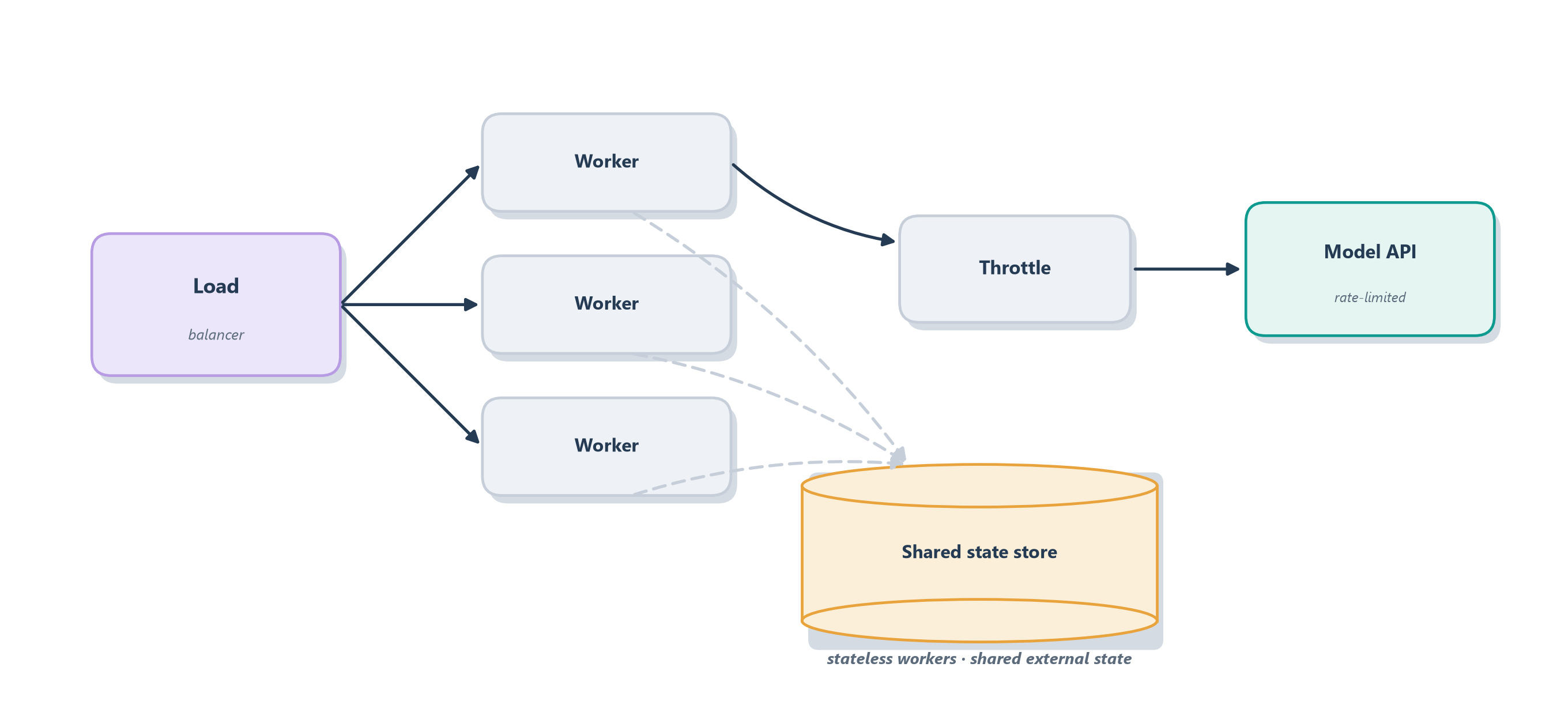
The lesson that ties this chapter together is that an agent is not just a clever prompt but a piece of software infrastructure, subject to the same operational realities as any other distributed system — budgets, failures, and load. Treat it that way and the classic disciplines of software engineering apply cleanly on top of everything specific to agents we have built. With that, an agent can be run responsibly and at scale, and Part 4 is complete: we can evaluate it, observe it, guard it, and operate it. Part 5 turns from these established practices toward the horizon — beginning with agents that step beyond text and APIs to act in the visual, physical world of screens and devices.
18.5 Case study: the Ledgerly support agent
Where we left off, Section 1.8 sketched Ledgerly as an idea. Eleven installments later it can reason, use tools, remember its customers, orchestrate itself as a graph, and defend against attack. This chapter ships it, and the four cost levers from Section 18.2 map straight onto the lanes we drew back in Section 8.9:
- Model routing. The easy FAQ lane and the triage step run on a small, cheap model; only the open-ended double-charge investigations escalate to a large one. Most tickets are easy, so most tickets are cheap.
- Caching. Ledgerly caches its retrieval of the refund policy and common invoice lookups, so a hundred identical “what’s your refund window?” tickets do not pay for a hundred identical searches.
- Batching and turn caps. Embeddings for incoming tickets are batched, and every run is capped at a bounded number of reason–act turns so a confused agent cannot run up an unbounded bill.
Then reliability, because Ledgerly moves money. The billing API gets a timeout and a bounded retry with backoff (Section 18.3), so a slow provider does not hang a customer. But retrying an action that pays out is dangerous: a naive retry could refund the same customer twice. The fix is an idempotency key on issue_refund, one unique token per intended refund, so if the request is retried the billing system recognizes it and pays exactly once. That single detail is what makes the whole guarded, checkpointed refund flow safe to run at scale.
And because thousands of customers write in at once, Ledgerly’s state, its memory and its graph checkpoints, lives in the shared store from Section 11.9 and Section 12.7 rather than inside one server’s process (Section 18.4), so any worker can pick up any conversation.
The whole deployment plan fits on one card:
| Lever | Ledgerly setting |
|---|---|
| Model routing | small model for FAQ and triage; large only for complex tickets |
| Caching | the refund policy and common invoice lookups |
| Batching and caps | batched embeddings; bounded reason–act turns per run |
| Reliability | timeout plus bounded retry; idempotency key on refunds |
| Scaling | memory and graph checkpoints in a shared store |
That closes the arc. We began in Section 1.8 unsure whether Ledgerly should even be an agent; we end with a system that is designed, specified, built, orchestrated, evaluated, observed, guarded, and now deployed, affordably and reliably, at scale. Every chapter of this book added one more part to it. Part 5 now carries these same disciplines to the frontier, where agents step beyond text and APIs to act in the visual and physical world.
Every part of Figure 9.10 is now live, the whole system, shipped:
- Router to three lanes (FAQ call, refund workflow, complex agent), each backed by bounded MCP tools and three-store memory.
- A shared evaluator gate and a human-approval step fence quality and the one irreversible action.
- Evaluated (golden set), observable (traces and metrics), and guarded (defense in depth).
- New this chapter: shipped for scale, cheap-model routing, turn and cost caps, idempotent refunds, and shared state so any worker resumes any conversation.
18.6 Summary
This chapter took the agent off the workbench and into production, where autonomy meets budgets, failures, and load. The recurring theme was that an agent is software infrastructure and must be run like it.
- Autonomy is expensive — the meter is running. Each reasoning step is a paid model call, so an agent’s cost is a variable taxi fare, not a fixed train ticket. Use autonomy where it is justified [1].
- Four levers cut cost and latency: route easy steps to a small model and hard ones to a large one, cache repeated work, batch independent calls, and cap the number of turns.
- Design for failure, because it is normal. Retries with backoff, timeouts, and stop conditions keep the agent standing when dependencies wobble — and idempotency keys make retries safe for agents that take real-world actions.
- Scaling needs concurrency, rate-limit handling, and externalized state. Long, waiting runs demand async execution; provider ceilings demand throttling; and state must live in a shared store so any worker can resume any run.
- An agent is a distributed system. The classic operational disciplines apply on top of everything agent-specific.
Part 4 is now complete: we can evaluate an agent, observe it, guard it, and operate it at scale — the full production toolkit. Everything so far, though, has assumed an agent that acts through text and structured tool calls. Part 5 looks toward the frontier, where agents break out of that mold to perceive and act in richer worlds. We begin with agents that use a computer the way a person does — by looking at the screen and moving the mouse: Chapter 19.
18.7 Exercises
- Train or taxi? Explain why an agent’s cost is a variable fare rather than a fixed ticket, and name one task where the taxi is worth it and one where the train would do.
- Pull a lever. For an agent whose bill is too high, walk through how you would apply model routing and turn limits, and estimate qualitatively where the savings come from.
- Make it idempotent. Describe a scenario where a naive retry double-charges a customer, and explain how an idempotency key prevents it.
- Survive a wobble. A tool your agent depends on starts timing out intermittently. Which reliability techniques from the chapter keep the service usable, and how?
- Scale it out. Explain why an agent that stores its state in one server’s memory cannot be scaled to two servers, and what change fixes it.