— Louis Sullivan, The Tall Office Building Artistically Considered (1896)
After this chapter you will be able to compare reactive, deliberative, and hybrid architectures and recognize them inside modern LLM agents.
3.1 Opening intuition
Chapter 2 showed that agents come in families — reactive, deliberative, BDI, learning. This chapter turns those families into an engineer’s question: how do you actually wire one together? Give two engineers the same goal — “keep the room at 21°C” — and they may build very different machines. One wires a thermostat: sense temperature, switch the heater, done. The other builds a system that models the building’s thermal mass, predicts the weather, and pre-heats before a cold front. Same goal, radically different internal wiring. That wiring is the agent’s architecture: how perception, reasoning, memory, and action are organized inside the loop.
Architecture is not an academic detail. It determines what an agent can do, how it fails, how much it costs to run, and how easy it is to debug. Think of it as the floor plan of the agent: the same rooms (perception, reasoning, memory, action) can be arranged in very different ways, and the arrangement decides how the whole house lives. This chapter gives you three reference floor plans — reactive, deliberative, and hybrid — hangs them all on one common backbone, and then shows where a modern LLM agent sits.
3.2 The common backbone: sense–plan–act
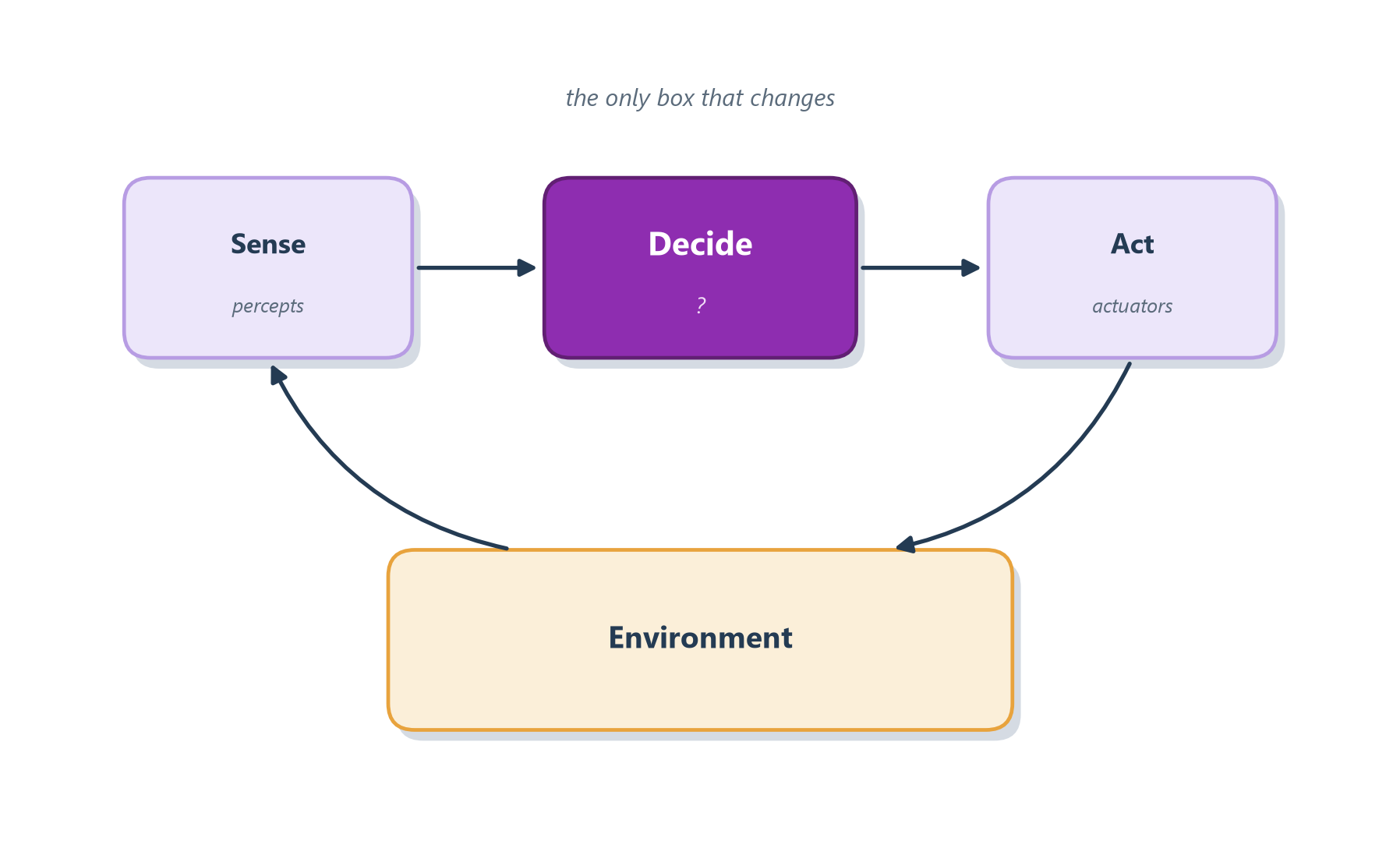
Strip any agent down and you find the same loop introduced in Section 1.2: sense the environment, decide what to do, act, and repeat. Architectures differ almost entirely in what happens in the middle box, as Figure 3.1 makes clear.
Figure 3.1: The sense–plan–act backbone shared by every architecture. What changes between architectures is only the middle ‘Decide’ box.
Keep this picture in mind: everything below is a different answer to “what goes in the Decide box, and how much state does it keep?”
3.3 Reactive architectures
A reactive agent maps the current percept directly to an action, with little or no internal state and no explicit look-ahead. Behavior comes from condition–action rules (or layered behaviors, as in Brooks’ subsumption architecture) [1].
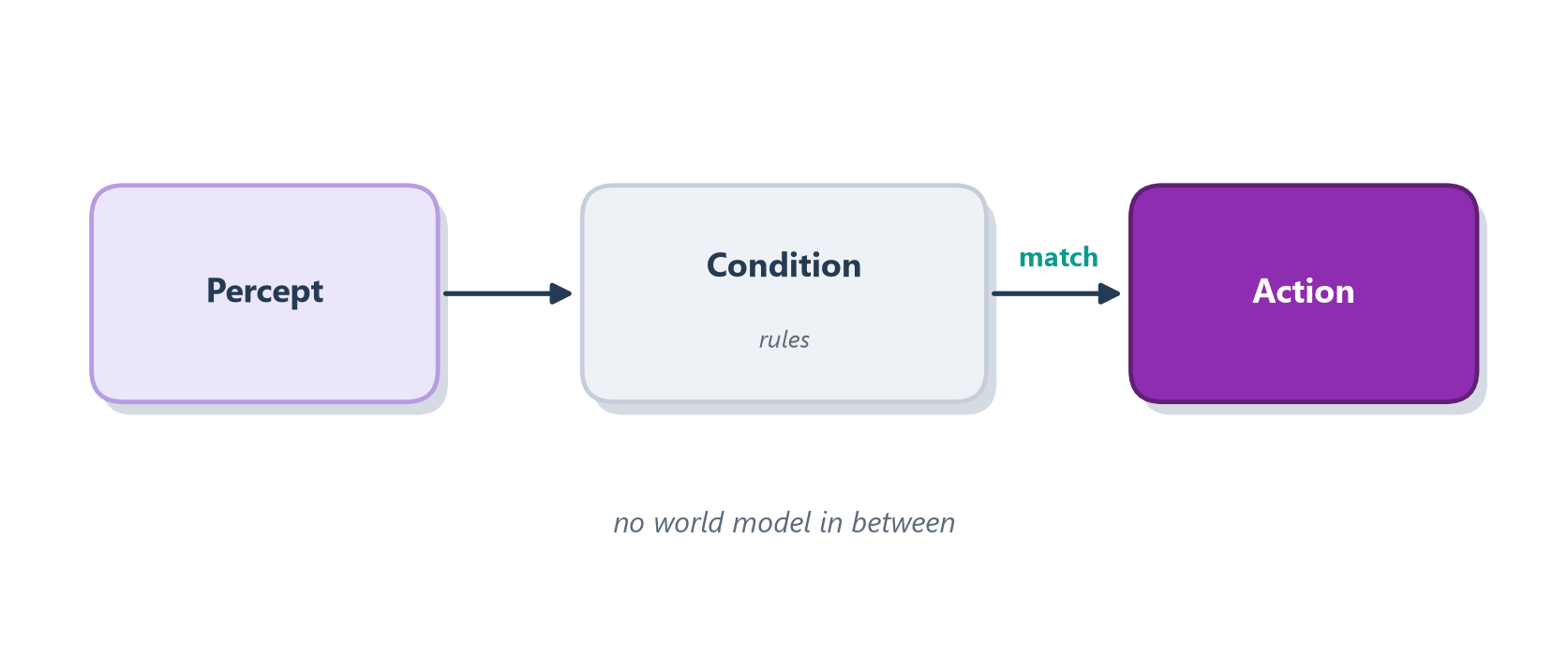
The mental image is a light switch with a motion sensor in an office hallway. Someone walks by and the light snaps on; the hallway falls quiet for a few minutes and the light clicks off again. That’s the whole behavior. Notice what the system doesn’t have: it keeps no record of who walked past this morning, it holds no expectation about who might come by this afternoon, and it certainly isn’t planning the building’s lighting for the week. There is nothing in the middle but a single rule wiring a percept (“motion detected”) straight to an action (“turn on”), and then another wiring its absence to the opposite action. That direct percept-to- action wiring, with no world model sitting in between, is the entire essence of the reactive style, and Figure 3.2 draws it.
Figure 3.2: A reactive agent: a percept matches a condition rule and fires an action, with no world model in between.
When it shines. Reactive designs are at their best in real-time control, tight feedback loops, and well-understood environments — anywhere that responding quickly and reliably matters more than thinking ahead. Because there is almost nothing to compute, a reactive agent answers instantly and rarely surprises you, which is exactly what you want from a motion-sensor light or a thermostat.
Where it breaks. The flip side is that having no memory and no plan means the agent can’t pursue any goal that unfolds over several steps. And because it only ever responds to the present moment, a reactive agent can loop forever if the environment doesn’t happen to change in response to what it does — it has no way of noticing that it is stuck.
# A minimal reactive (reflex) agent: percept -> action, no memory.def reflex_thermostat(temperature: float, target: float=21.0) ->str:if temperature < target -0.5:return"heat_on"if temperature > target +0.5:return"heat_off"return"hold"for t in [18.0, 21.0, 23.5]:print(f"{t}°C -> {reflex_thermostat(t)}")
18.0°C -> heat_on
21.0°C -> hold
23.5°C -> heat_off
3.4 Deliberative architectures
A deliberative agent maintains an explicit model of the world and reasons over it — searching or planning to choose actions that reach a goal [2]. The Decide box now contains a world model plus a planner.
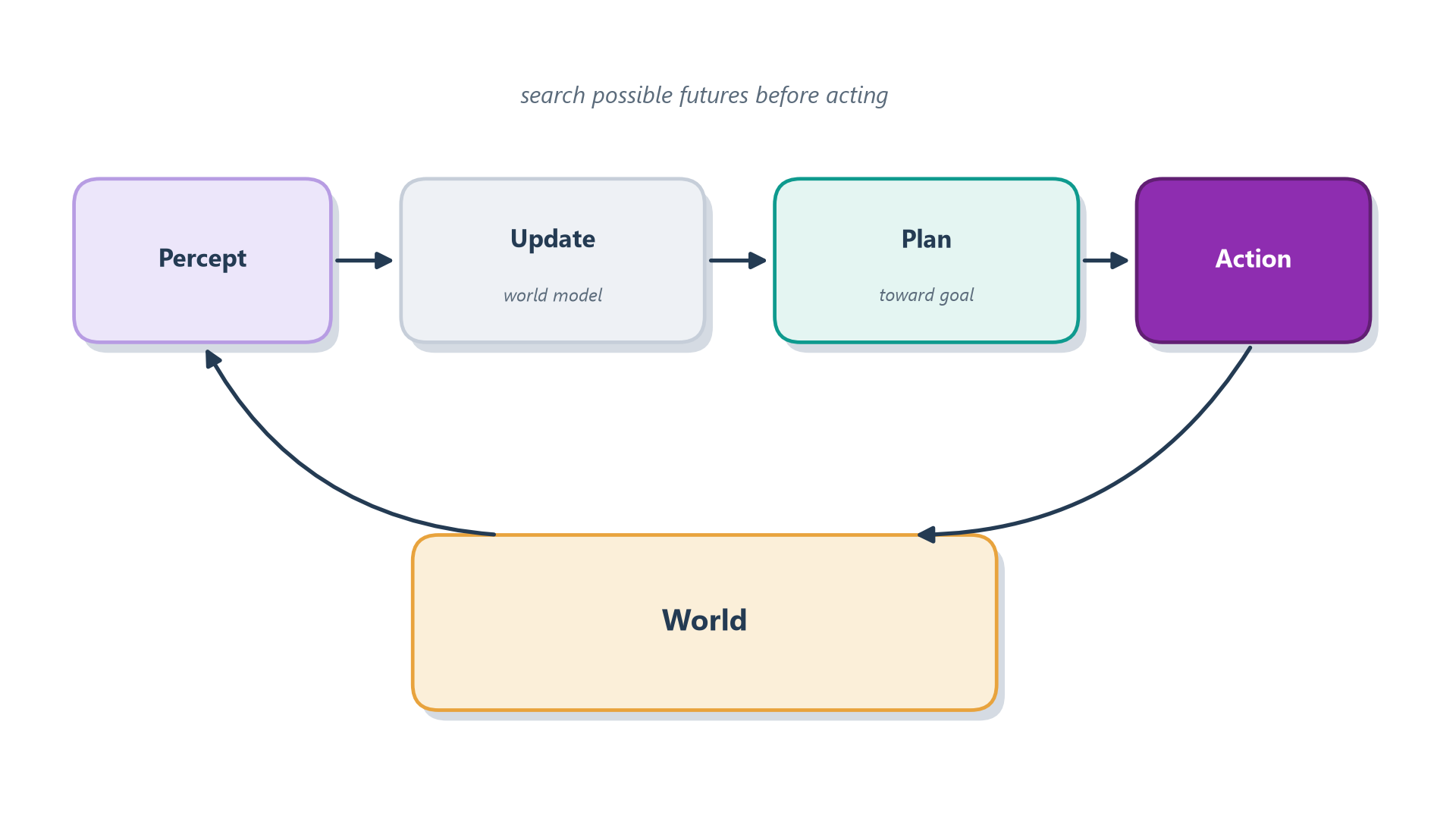
Picture a chess player sitting perfectly still, staring at the board before touching a single piece. Nothing is happening on the outside, but a great deal is happening on the inside: “If I move my knight here, she’ll probably take it with her bishop, but then I recapture with the pawn and suddenly her king is exposed…” The player is running possible futures forward in imagination, several moves deep, pruning the lines that end badly and following the ones that lead somewhere good — and only after all that internal search do they reach out and move. That pause, filled with simulated futures, is the deliberative style at work. Figure 3.3 shows the same shape as a loop: take in the board through the senses, update an internal model of the position, search that model several moves ahead for a plan, and only then act.
Figure 3.3: A deliberative agent updates a world model from each percept, plans toward its goal, and only then acts.
When it shines. Deliberative designs pay off on multi-step tasks where thinking ahead genuinely helps and the environment is predictable enough to model faithfully — logistics and scheduling, game playing, and structured problem solving of all kinds. Whenever the cost of a wrong move is high and you have the information needed to see it coming, planning before you act is worth the extra time.
Where it breaks. A deliberative agent is only ever as good as its model of the world. Building an accurate model of a messy environment is hard, the planning itself can be slow, and a plan built against a stale model falls apart the instant it meets reality. This is precisely the brittleness we saw in the symbolic tradition (Section 2.2), now wearing an architectural hat.
3.5 Hybrid / layered architectures
Reaction is fast but shallow; deliberation is deep but slow and brittle. Real systems usually want both, so they layer them: a fast reactive layer handles moment-to- moment control while a slower deliberative layer sets goals and plans. Lower layers can act immediately; higher layers steer.
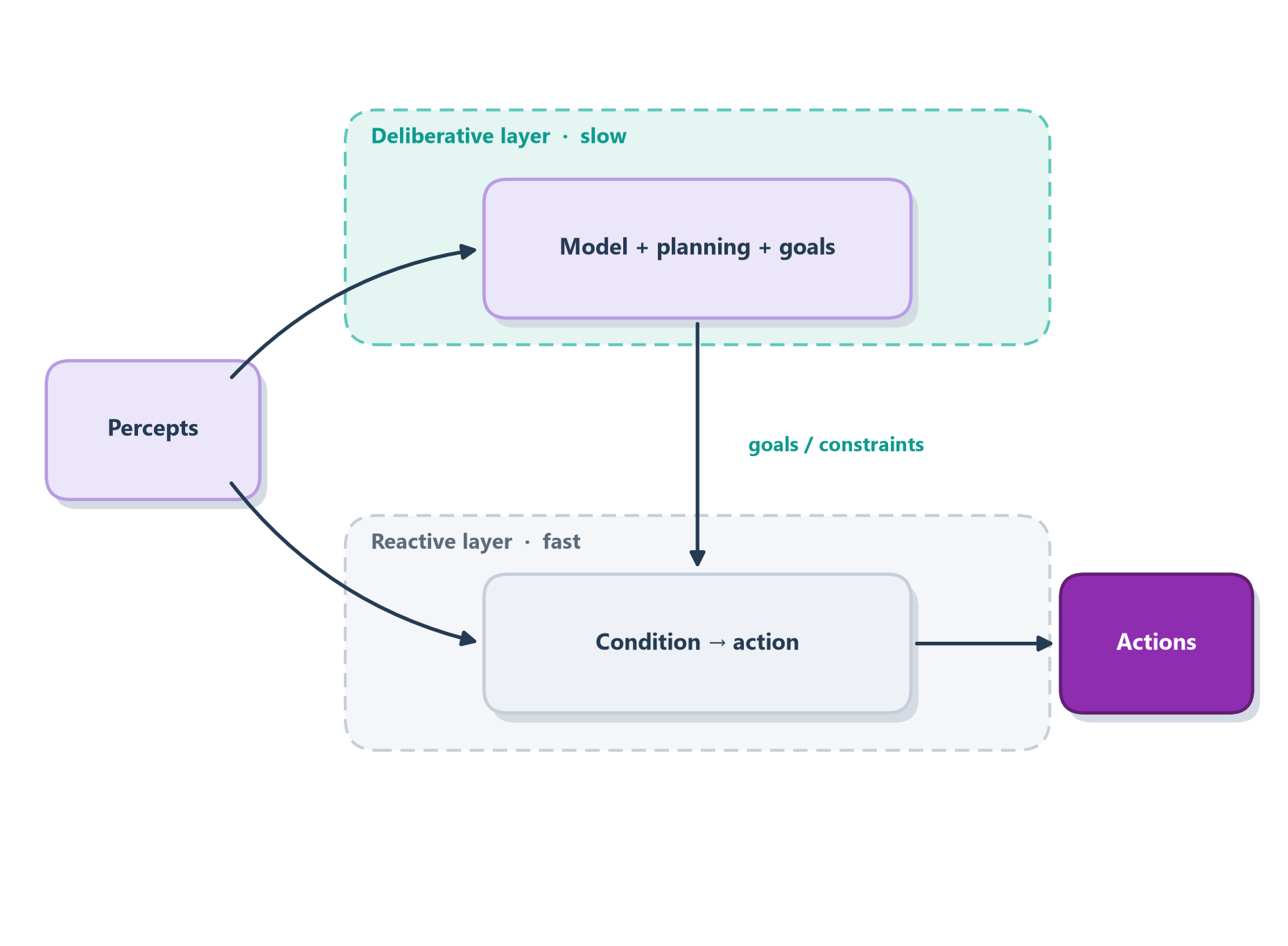
Driving a car is the perfect example, because you can feel both layers running in your own head at once. Down at the fast layer, your reflexes are doing the moment-to-moment work: they keep the car centered in its lane, ease off the gas when the car ahead slows, and slam the brake the instant a light turns red — all without any conscious thought, so completely that you can do it while holding a conversation. Meanwhile, up at the slow layer, a more reflective part of your mind is planning: it’s deciding which exit to take, noticing you’re low on gas and wondering whether to stop now or after the next town, reconsidering the whole route because traffic is building. The two layers run at the same time and mostly don’t interfere — reflexes handle the next half-second, planning handles the next half- hour, and each is left to do what it’s best at. Figure 8.5 draws exactly that split.
Figure 3.4: A hybrid architecture: a slow deliberative layer sets goals that steer a fast reactive layer, which handles immediate control.
When it shines. Almost every serious autonomous system — robots, self-driving stacks, and, as we’ll see, capable LLM agents — is some form of hybrid. The layering lets you get the safety and speed of reaction without giving up foresight.
The design question is always the same: which decisions belong in the fast layer, and which in the slow one? Put too much in the slow layer and the agent is sluggish and brittle; too much in the fast layer and it is short-sighted.
Note🧠 Deep dive: three horizons of control
A useful way to assign responsibilities is by time horizon. Reactive control handles the next instant (avoid the obstacle). Executive control handles the next few steps (finish this sub-task). Deliberative control handles the whole task (achieve the goal). Confusing the horizons — planning at reflex speed, or reacting where you should plan — is a common source of both cost blow-ups and erratic behavior.
3.6 Where LLM agents sit
A modern LLM agent is best understood as a hybrid architecture in disguise, with the pieces relabeled:
Classical component
LLM-agent realization
World model / beliefs
The prompt, conversation history, retrieved documents, and memory
Deliberative planner
The model’s reasoning (chain-of-thought, ReAct, reflection)
Reactive layer
Direct tool calls triggered by the latest observation
Actuators
Function/tool calls, code execution, messages
The loop + stop rule
“LLM calls tools based on feedback, in a loop,” with a termination condition [3]
Two properties make LLM agents distinctive. First, the “world model” is largely implicit and linguistic — held in the context window rather than a formal symbol store — which makes it flexible but prone to hallucination. Second, planning and acting are interleaved: rather than plan once and execute (pure deliberation), capable agents alternate short bursts of reasoning with actions and re-ground themselves in each tool result [3], [4]. This interleaving is not just tidy — it measurably helps. The ReAct study found that a model reasoning and acting in a loop hallucinates far less than one that only reasons in its head (pure chain-of-thought), precisely because each action fetches a real fact from the world to check its thinking against [4]. That interleaving is the hybrid compromise from earlier in the chapter — deliberate a little, react a little, repeat — arrived at from a new direction.
Tip🛠️ In practice
When an LLM agent misbehaves, figuring out which layer failed can save you hours of guessing. If the final answer is wrong but the steps it took were sensible, the fault usually lies in the deliberative layer — its reasoning or the context you gave it — so that is where to look first. If the plan was sound but it called a tool incorrectly, the problem is in the reactive layer, and the fix is almost always a clearer tool schema and better documentation — the agent–computer interface we cover in Chapter 10. And if the agent simply loops forever, the culprit is a missing or weak stop condition in the loop itself.
3.7 Choosing an architecture
So how do you actually pick one? The honest answer is that the environment chooses for you, and your job is mostly to avoid over-building. This echoes the “least autonomy that works” principle from Section 1.7: reach for the simplest architecture the task will tolerate, and add machinery only when the task genuinely demands it.
If the task is predictable, fast, and essentially single-step — decide whether an email is spam, hold a room at a set temperature — then a reactive design is not just enough, it is the right call. Adding a planner would only make the system slower and more fragile without buying you anything.
If the task is still predictable but unfolds over several steps, where thinking ahead genuinely pays off — routing a delivery truck, playing a board game — then you want a deliberative design that can look before it leaps. Here the cost of planning earns its keep, because a good plan avoids expensive mistakes down the line.
And if the task is open-ended, only partially visible, or safety-critical — a self-driving car, or an LLM agent loose on a large codebase — then you almost always want a hybrid: fast reflexes for the moment-to-moment, slower deliberation to set direction. For LLM-driven versions specifically, the practical form of this is to interleave short bursts of reasoning with grounded tool calls, so the agent keeps checking its thinking against the real world rather than trusting a plan it made minutes ago.
3.8 Summary
Every agent shares the sense–plan–act backbone; architectures differ in what fills the decide step and how much state it keeps.
Reactive agents map percepts to actions — fast and robust, but no foresight.
Deliberative agents plan over an explicit model — powerful, but slow and brittle when the model is wrong.
Hybrid architectures layer fast reaction under slow deliberation; most serious autonomous systems are hybrids.
LLM agents are hybrids with relabeled parts, distinguished by an implicit linguistic world model and interleaved planning and acting.
Where next? We now have the anatomy of an agent, but not the standard by which we judge its choices. Chapter 4 closes Part I by asking what it means for an agent to act well — how the environment shapes what “good” even means.
3.9 Exercises
Classify each as reactive, deliberative, or hybrid, and justify: a spam filter, a chess engine, a self-driving car, a coding agent that edits multiple files.
Extend the reflex thermostat in Section 3.3 with a one-step memory so it avoids rapid on/off “chattering.” Which architecture have you moved toward?
For an LLM agent that failed a task, describe how you would decide whether the fault lay in its deliberative layer, its reactive layer, or its loop.
[1]
R. A. Brooks, “Intelligence without representation,”Artificial Intelligence, vol. 47, no. 1–3, pp. 139–159, 1991.
[2]
S. Russell and P. Norvig, Artificial intelligence: A modern approach, 4th ed. Pearson, 2021.