4 Environments & Rationality
“An ant, viewed as a behaving system, is quite simple. The apparent complexity of its behavior over time is largely a reflection of the complexity of the environment in which it finds itself.”
— Herbert A. Simon, The Sciences of the Artificial
After this chapter you will be able to characterize any task environment along a handful of axes, and reason clearly about what “acting rationally” means inside it — the standard by which every later chapter judges an agent.
4.1 Opening intuition
Chapter 3 gave us the anatomy of an agent — the wiring inside the box. But an agent is only ever half of a story. The other half is the world it acts in, and that world quietly dictates what “smart” even means.
Think about the difference between playing solitaire and playing poker. Solitaire is patient and honest: the whole board is in front of you, nothing moves unless you move it, and the same play always has the same result. Poker is none of those things — cards are hidden, opponents bluff and react, and the “right” move depends on people you cannot see inside. A brilliant solitaire strategy would get you destroyed at a poker table, not because the player got dumber, but because the environment changed underneath them.
That is the theme of this chapter: the environment shapes the agent as much as the agent shapes the environment. Before you can say whether an agent is behaving well, you have to describe the world it lives in. So we need two things — a checklist for describing a task environment, and a clear definition of what it means to act well within one.
4.2 PEAS: a checklist for any task
When engineers sit down to build an agent, the first mistake is to start with the agent. The better starting point is the task. A simple checklist from classical AI, PEAS, forces you to pin down the task before you touch the machine [1]. PEAS stands for:
- Performance measure — how will you know the agent did well?
- Environment — what is the world it operates in?
- Actuators — what can it do to that world?
- Sensors — what can it perceive of that world?
Take a self-driving taxi as the classic example, laid out in Figure 4.1, and walk through the four letters one at a time. Its performance measure is not a single number but a blend of things we care about all at once — getting there safely, obeying the law, keeping the ride smooth and comfortable, and doing it reasonably quickly — and those goals sometimes pull against each other, which is exactly why naming them up front matters. Its environment is the messy real world of roads, other drivers, darting pedestrians, cyclists, and weather that can turn on a dime. Its actuators are the handful of things it can actually do to that world: turn the steering wheel, press the throttle, apply the brakes, flick the turn signals. And its sensors are the instruments through which it perceives that world: cameras, radar, GPS, and a speedometer, each offering a different, partial view of what’s out there. Four questions, and you’ve pinned the task down before writing a line of code.
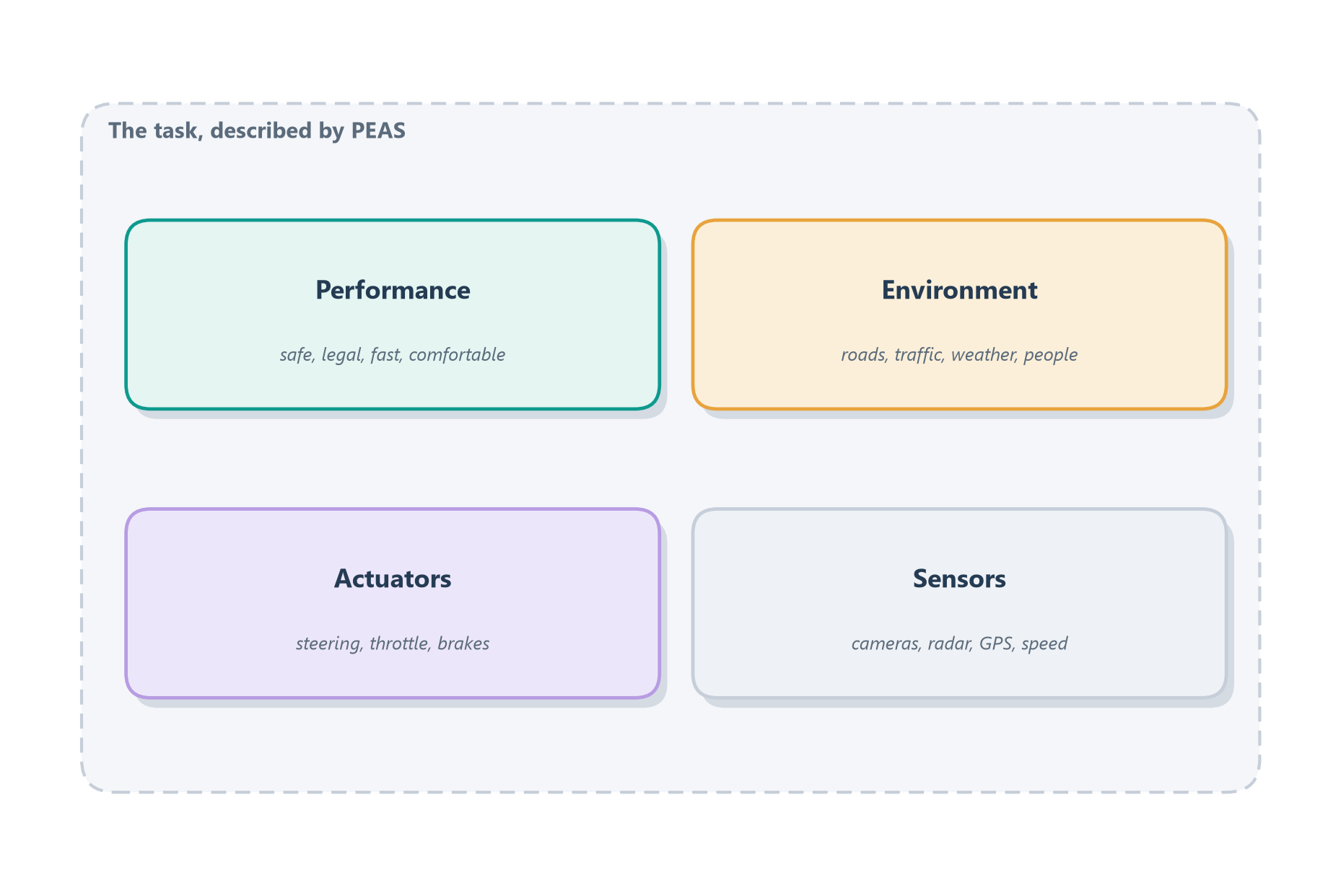
The same checklist works for a software agent — it just trades the physical world for a digital one. Take a coding agent whose job is to fix failing tests. Its performance measure is concrete and checkable: the failing tests should pass, and — just as importantly — nothing that used to work should break in the process. Its environment is a code repository and the test suite that runs against it. Its actuators are the actions it can take on that repository: editing files and running shell commands. And its sensors are how it perceives the state of things: reading the files, and watching the output that comes back when it runs a command. Notice that this is the identical four-part structure as the taxi — only the particular sensors and actuators have changed. That is the whole point of PEAS: one checklist, every task.
Vague agents almost always trace back to a vague performance measure. “Be helpful” is not something you can optimize or evaluate. “Resolve the ticket in one reply without escalation, and don’t invent policy” is. Nail the P in PEAS first; much of Part IV (evaluation) is really about taking that letter seriously.
4.3 The shape of an environment
Once you have named the task, you can describe the kind of world it happens in. A handful of axes, drawn from the classical framework [1], capture most of what makes one environment harder than another. Each axis is a spectrum, not a switch, but the endpoints are what you need to feel.
Fully observable ↔︎ partially observable. Can the agent see the whole relevant state at once, or only a peephole? Solitaire is fully observable; poker is partially observable. Peepholes force the agent to remember and guess.
Deterministic ↔︎ stochastic. Does the same action in the same state always produce the same result? Chess is deterministic; rolling dice or driving on ice is stochastic. Randomness means the agent must plan for outcomes it cannot control.
Static ↔︎ dynamic. Does the world sit still while the agent thinks? A crossword puzzle waits patiently; a video game does not. In a dynamic world, thinking too long is itself a mistake — the situation has moved on by the time you decide.
Discrete ↔︎ continuous. Does the world come in clean steps, or a smooth flow? Board games have discrete turns and moves; steering a car through traffic is continuous in time, space, and speed.
Single-agent ↔︎ multi-agent. Are there other agents whose choices affect yours — and who react to you? Solitaire is single-agent; poker, negotiation, and driving are multi-agent, which adds the endless hall of mirrors of “what do they think I’ll do?”
Figure 4.2 gathers the axes onto a single “difficulty dial.” The far-left end of every axis is the easy, tidy world; the far-right end is the messy, realistic one.
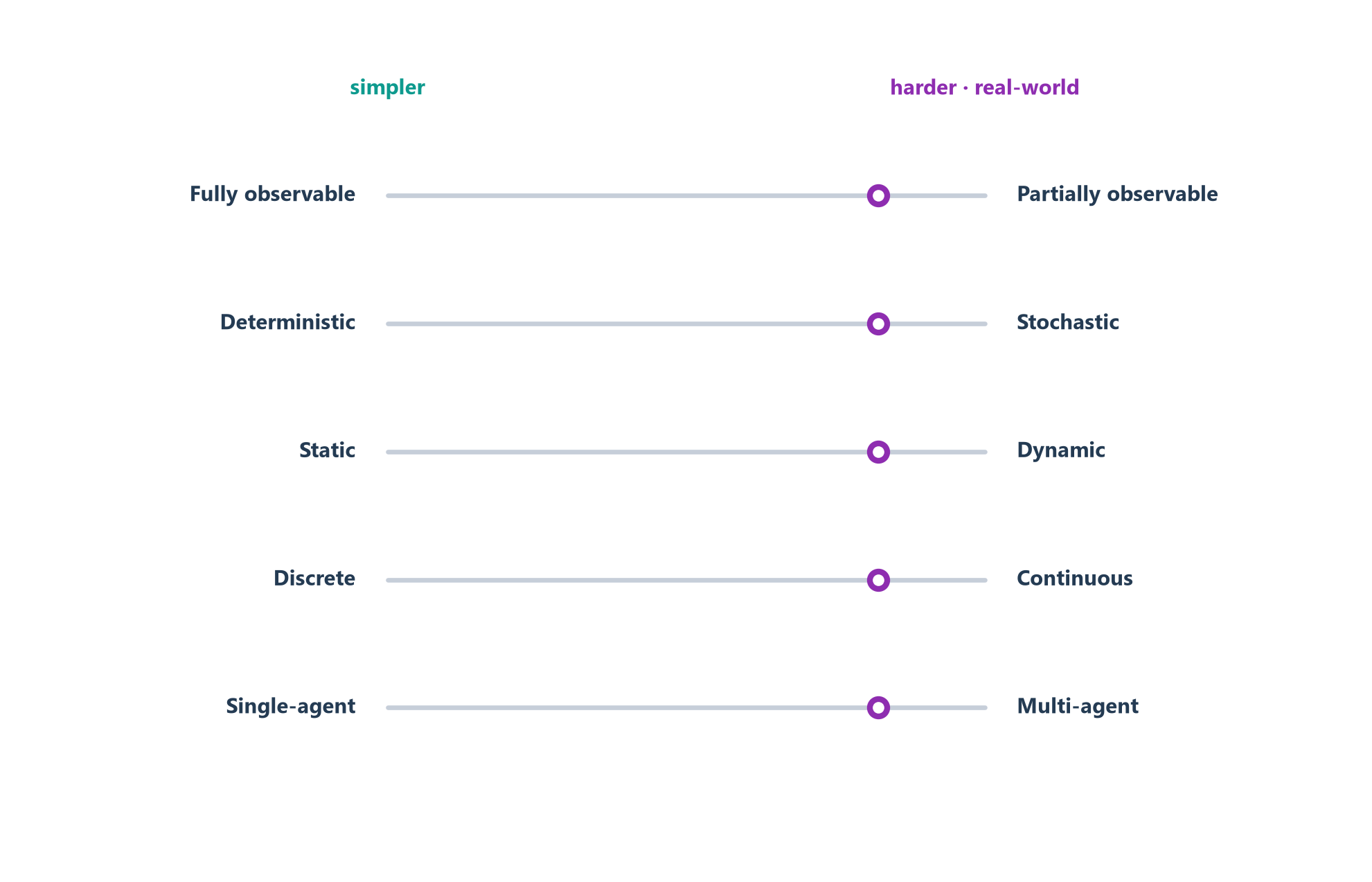
The punchline is simple and a little humbling: the interesting tasks all live on the right. Partially observable, stochastic, dynamic, continuous, multi-agent environments are exactly the ones worth automating — and exactly the ones a rigid script cannot survive. That is the deepest reason agents exist at all. It is the same lesson from Section 1.4, now stated in the language of environments: you reach for autonomy precisely when the world is too messy to script.
4.4 What “rational” really means
We can finally say what it means for an agent to act well. A rational agent is one that chooses the action expected to do best on its performance measure, given what it has perceived so far and what it knows [1]. Read that sentence slowly, because two phrases in it do all the work.
“Given what it has perceived” is a reminder that rationality is judged against available information, not against the truth of the world. If a poker player pushes all-in with the best possible odds and still loses to a lucky river card, they played rationally and lost. Rationality is about the quality of the decision, not the luck of the outcome. This distinction will save you endless grief when evaluating agents: an agent that made the sensible call with the information it had is not broken just because the world threw it a bad card.
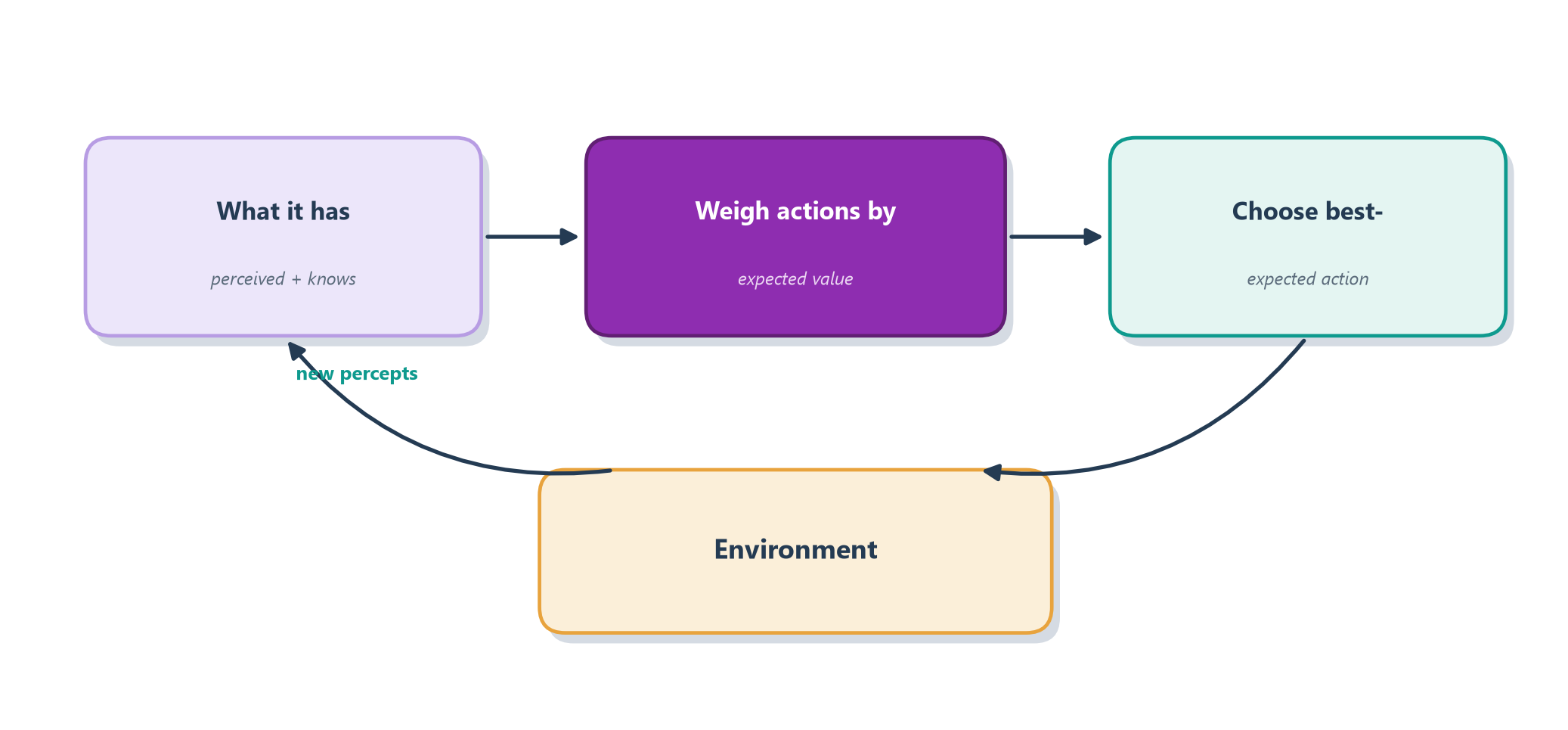
“Expected to do best” points at the idea of utility. When outcomes are uncertain, a rational agent doesn’t chase the single best-case result; it weighs each possible outcome by how likely it is and how much it’s worth, and picks the action with the best average. Figure 4.3 captures the loop: perceive, weigh the options against the performance measure, act, and learn from what comes back.
An agent is never rational in the abstract — only relative to its performance measure, its prior knowledge, the actions available to it, and its percept history so far [1]. Change any of the four and the “rational” action can flip. This is why arguing about whether an agent is “smart” in a vacuum is a waste of breath: without the PEAS, the question has no answer.
4.5 Why this matters for LLM agents
Every abstraction in this chapter shows up, concretely, the moment you build an LLM agent — usually as a source of bugs.
LLM agents live in partially observable worlds. An agent poking at a large codebase or the open web sees only what its last tool call returned — a peephole, not the whole state. Like the poker player, it must act on incomplete information and update as it learns. This is the real reason capable agents interleave acting and observing rather than planning everything up front (Section 3.6): each tool result widens the peephole a little [2].
Their environments are stochastic and dynamic. The web changes, APIs return errors, and the model itself is a bit random from run to run. An agent that assumes the world will hold still — that plans once and never re-checks — is brittle in exactly the way Section 2.2 warned about. Re-grounding after each step is not paranoia; it is rationality in a dynamic world [3].
“Rational” reframes how we judge them. Because rationality is about the decision, not the outcome, a fair evaluation cannot stop at “did it get the right answer once?” It has to ask “did it make sensible choices given what it could see?” — and it has to average over many tries, because the environment is stochastic. That is precisely why serious agent benchmarks run tasks in realistic, controlled environments and score across many trials rather than cherry-picking a single lucky run [4], [5]. We build directly on this idea in Chapter 15.
4.6 Case study: the Ledgerly support agent
Where we left off, Section 1.8 framed Ledgerly’s support as a hybrid: mostly workflow, with an agent reserved for the messy tickets. Before we build anything, this chapter’s discipline says to pin down the task, not the machine, so let us write the PEAS for the agent that will handle those messy tickets.
| PEAS | The Ledgerly support agent |
|---|---|
| Performance | Resolve the customer’s issue correctly in as few replies as possible, without inventing policy, without over-refunding, and without escalating what it could have handled itself. |
| Environment | The customer’s conversation, plus Ledgerly’s systems: the billing database, the invoice and subscription records, and the written refund policy. |
| Actuators | Look up an invoice, read a subscription, issue a refund, change a plan, post a reply, and escalate to a human. |
| Sensors | The incoming message text, the records its lookups return, and the result (success or error) of each action it takes. |
Naming the performance measure first does the heavy lifting, exactly as the In practice note above warned. “Be helpful” would give us nothing to build or evaluate against, whereas “resolve correctly, in few replies, without inventing policy or over-refunding” is a target we can design toward and, in Part IV, actually measure.
The axes from Section 4.3 tell us what kind of world this agent lives in, and every one of them lands on the hard side. It is partially observable, because the agent sees only what its last lookup returned, never the whole customer history at once, so it must remember and sometimes guess. It is stochastic and dynamic, because a refund API can fail, a plan can change mid-conversation, and the model itself varies from run to run. And it is quietly multi-agent, because a frustrated customer reacts to whatever the agent says. This is precisely the messy, right-hand-side world that a rigid script cannot survive, which is why the hard tickets earn an agent at all.
With the task specified and its world understood, Section 6.7 gives the agent the three faculties it needs to act in that world: tools, retrieval, and memory.
4.7 Summary
- An agent is only half the story; the environment it acts in decides what good behavior even looks like — solitaire strategy fails at a poker table.
- PEAS (Performance, Environment, Actuators, Sensors) is a checklist for pinning down a task before you design the agent; a vague performance measure is the root of most vague agents [1].
- Environments vary along a few axes — observable, deterministic, static, discrete, single-agent and their harder opposites. The tasks worth automating cluster on the hard end.
- A rational agent picks the action with the best expected value given what it has perceived and knows — judged on the decision, not the lucky or unlucky outcome [1].
- LLM agents live in partially observable, stochastic, dynamic worlds, which is why they must observe-and-adapt in a loop, and why we evaluate them across many trials.
That closes Part I. You can now define an agent, trace its intellectual lineage, recognize its internal architecture, and describe the world it acts in and the standard it is held to. Part II turns to the engine at the center of every modern agent: the large language model. Chapter 5 asks the question the rest of the book depends on — what makes an LLM good enough to reason inside that loop, and where its limits quietly become risks.
4.8 Exercises
- Write the full PEAS description for an agent that manages your email inbox. Be specific about the performance measure — what would count as it doing well, and what would count as it overstepping?
- Place three environments on the five axes of Figure 4.2: a chess engine, a thermostat, and a customer-support agent. Which axis makes the support agent hardest, and why?
- An agent books a flight at the best available price, but the airline cancels the route the next day. Was the agent irrational? Use the decision-versus-outcome distinction from Section 4.4 to argue your answer.
- Give one concrete example of partial observability that a web-browsing agent faces, and describe how interleaving action and observation helps it cope.