“Those who cannot remember the past are condemned to repeat it.”
— George Santayana, The Life of Reason
After this chapter you will understand the intellectual lineage of today’s agents and the core theoretical models that still shape how we build them.
2.1 Opening intuition
Chapter 1 defined an agent as something that senses, decides, and acts in a loop. That definition is young; the ideas inside it are not. When an LLM agent plans a task, second-guesses itself, and tries again, it can feel like something brand new. It isn’t. Almost every idea inside a modern agent — planning toward a goal, reacting to the world, holding beliefs and intentions, learning from reward — was worked out, often decades ago, by researchers who had no transformers at all. Today’s agents are the newest layer on a long stack.
Knowing that history is not nostalgia. Each earlier tradition discovered a specific strength and a specific failure mode, and modern agents inherit both. If you can see which tradition a design belongs to, you can predict how it will break. Recent surveys of LLM agents make the same point by tracing the idea all the way back through AI to its philosophical roots before arriving at today’s systems [1] — the lineage is real, and worth knowing.
This chapter walks four traditions — symbolic/deliberative, reactive, BDI, and reinforcement learning — and ends with the synthesis that frames the rest of the book.
2.2 Symbolic AI and the deliberative tradition
The first paradigm treated intelligence as symbol manipulation: represent the world as symbols, and produce intelligent behavior by searching over those symbols for a sequence of actions that reaches a goal. Newell and Simon called this the physical symbol system hypothesis — the claim that symbol manipulation is sufficient for general intelligent action [2].
A deliberative agent in this tradition keeps an explicit model of the world, and plans: it searches forward through possible actions to find a path from the current state to a goal state [3].
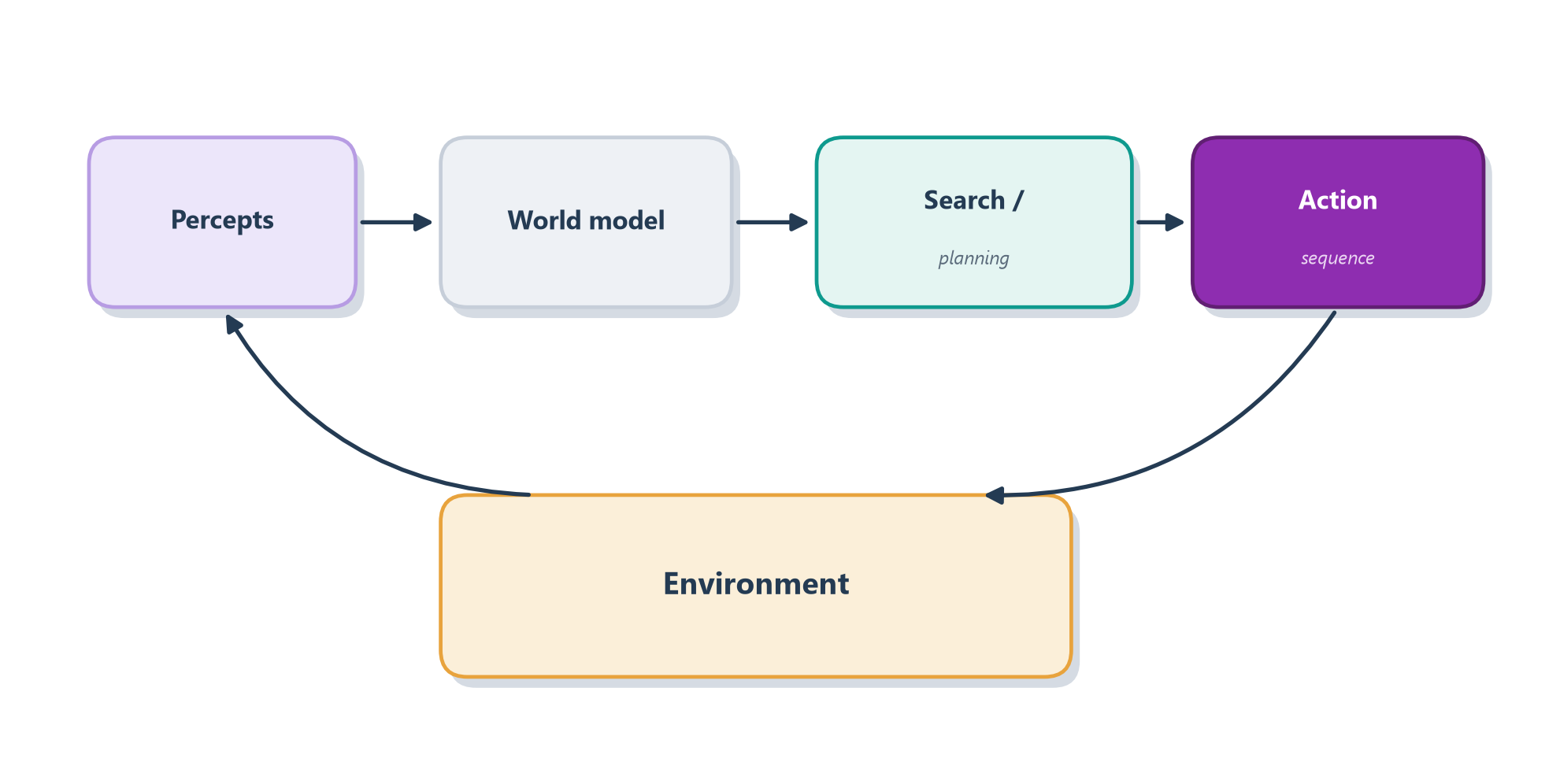
Think of planning a road trip with a paper map spread across the kitchen table. You haven’t started the car; you haven’t even put your shoes on. And yet you are already travelling — in your head. Your finger traces one route, then backs up and tries another, comparing them: this one is shorter but goes through the mountains, that one is longer but avoids the toll road. You weigh the options, settle on a plan, and only then pick up the keys. That whole process — exploring possible futures on a model of the world before committing to a single action in the real one — is deliberation in a nutshell. The agent builds a little model of the world (in your case, on the table) and searches it for a good plan, exactly as Figure 2.1 shows.
Figure 2.1: A deliberative agent builds a world model from percepts, searches it for a plan, and acts — then senses again.
What it’s good at. When the model is accurate and the world behaves itself, deliberation is genuinely powerful — and, just as importantly, it is explainable. Because the agent has literally laid out a plan, you can read that plan, check it, and understand exactly why it intends to do what it’s about to do. For a whole class of problems — proving a theorem, solving a logistics puzzle, playing a board game — thinking before acting is precisely what you want.
Where it falls apart. The trouble is that deliberation is brittle. Building and maintaining a correct symbolic model of a messy, changing world turns out to be enormously hard, and the search for a plan can explode into more possibilities than any computer could ever sift through. Worse, a plan is only as good as the model it was built on. The moment reality drifts away from that model, the plan quietly becomes wrong — like confidently following your paper map straight into a road that was closed for construction last month.
Note🧠 Deep dive: why this matters for LLM agents
When you ask an LLM to “make a plan, then execute it,” you are reinventing deliberative AI — and you inherit its brittleness. The plan is only as good as the model’s (implicit) picture of the world, which may be hallucinated. This is exactly why modern agents re-plan continuously and re-ground themselves in tool results at each step, rather than committing to one long plan up front [4].
2.3 The reactive turn
By the late 1980s, the brittleness of grand symbolic models provoked a rebellion. Rodney Brooks argued, provocatively, for intelligence without representation: robust behavior can emerge from tight couplings between perception and action, with no central world model at all [5]. In his subsumption architecture, simple behaviors (“avoid obstacles,” “wander,” “explore”) run in parallel and layer over one another, and competent overall behavior emerges from their interaction.
A reactive agent maps situations directly to actions — condition → action — without deliberating about the future.
The everyday version is pulling your hand off a hot stove. Think about what does not happen in that moment: you don’t consult a mental map of the kitchen, you don’t weigh the pros and cons of moving your arm, and you certainly don’t plan a sequence of steps. The heat simply triggers the withdrawal, directly and almost instantly — in fact your spinal cord fires the reflex before the signal even reaches your brain. That is a pure condition → action mapping, and it is fast precisely because it skips all the thinking. A great deal of a housefly’s competence works this way too. It has almost no capacity to plan, yet it is maddeningly hard to swat, because its escape behavior is wired as a set of tight, lightning-quick reflexes from its eyes straight to its wings. No deliberation, no model of you and your rolled-up newspaper — just reaction, and it works beautifully.
What it’s good at. Reactive agents are fast, robust, and cheap. There is no model to build, no plan to compute, and therefore nothing that can go stale. In a world that changes faster than you could ever plan for, that immediacy is a genuine superpower — it is why your reflexes, not your deliberations, are what keep you from touching the hot stove.
Where it falls apart. The price of all that speed is a complete lack of foresight. A purely reactive agent lives entirely in the present moment, so it simply cannot pursue a goal that requires thinking several steps ahead. And because it has no memory of what it just did, it can happily get stuck repeating the same action forever, never noticing that it is going in circles.
The lasting lesson from this clash of traditions is a spectrum rather than a winner: reaction is fast but shallow, while deliberation is deep but slow and brittle. Real agents almost always need a bit of both — a tension we finally resolve in Chapter 3.
2.4 BDI: Belief–Desire–Intention
The Belief–Desire–Intention model gave agents a principled internal structure grounded in a theory of practical reasoning [6]. It names three things going on inside an agent at once. Its beliefs are what it takes to be true about the world — its running picture of how things currently are, which may be incomplete or even wrong. Its desires are the states of affairs it would like to bring about — the goals it cares about, several of which may quietly conflict. And its intentions are the particular desires it has actually committed to pursuing right now, the ones it has stopped merely wishing for and started acting on.
The key insight is commitment. An agent that reconsiders everything at every instant never gets anything done; one that never reconsiders is blind to change. BDI is about balancing persistence toward chosen goals against responsiveness to new information.
You live this every day, and the gym is the perfect illustration. Suppose you desire two things that quietly pull against each other: to be healthy, and to relax and enjoy yourself. This morning you resolved the tension by forming an intention — you committed to going to the gym after work. Now watch what that commitment does for you. On the way there, a friend calls with a tempting offer to grab a drink instead. Here is the whole drama of BDI in one moment. If you abandon the gym at the very first whiff of something more fun, you will never get fit, because you’ll re-decide your entire life every five minutes and finish nothing — that’s too little commitment. But if you would march grimly past a car accident, ignoring someone who needs help, just to hit your workout on schedule, something has gone badly wrong in the other direction — that’s too much commitment. Acting sensibly means holding your intention firmly enough that you actually make progress toward your goals, yet loosely enough that you can drop it when the world genuinely changes. That delicate balancing act — persistence on one side, responsiveness on the other — is exactly what the BDI model sets out to formalize.
Tip🛠️ In practice
The BDI vocabulary maps cleanly onto agent design decisions you will make in Part III. “Beliefs” become the agent’s memory and retrieved context; “desires” become the task and success criteria; “intentions” become the current plan or the active sub-goal on the stack. When your agent thrashes — abandoning tasks halfway or looping — you usually have a commitment problem, not a model problem.
2.5 Reinforcement learning
A fourth tradition asks a different question: rather than program the right behavior, can an agent learn it from experience? In reinforcement learning (RL), an agent interacts with an environment, takes actions, receives a scalar reward, and learns a policy — a mapping from states to actions — that maximizes cumulative reward over time [7].
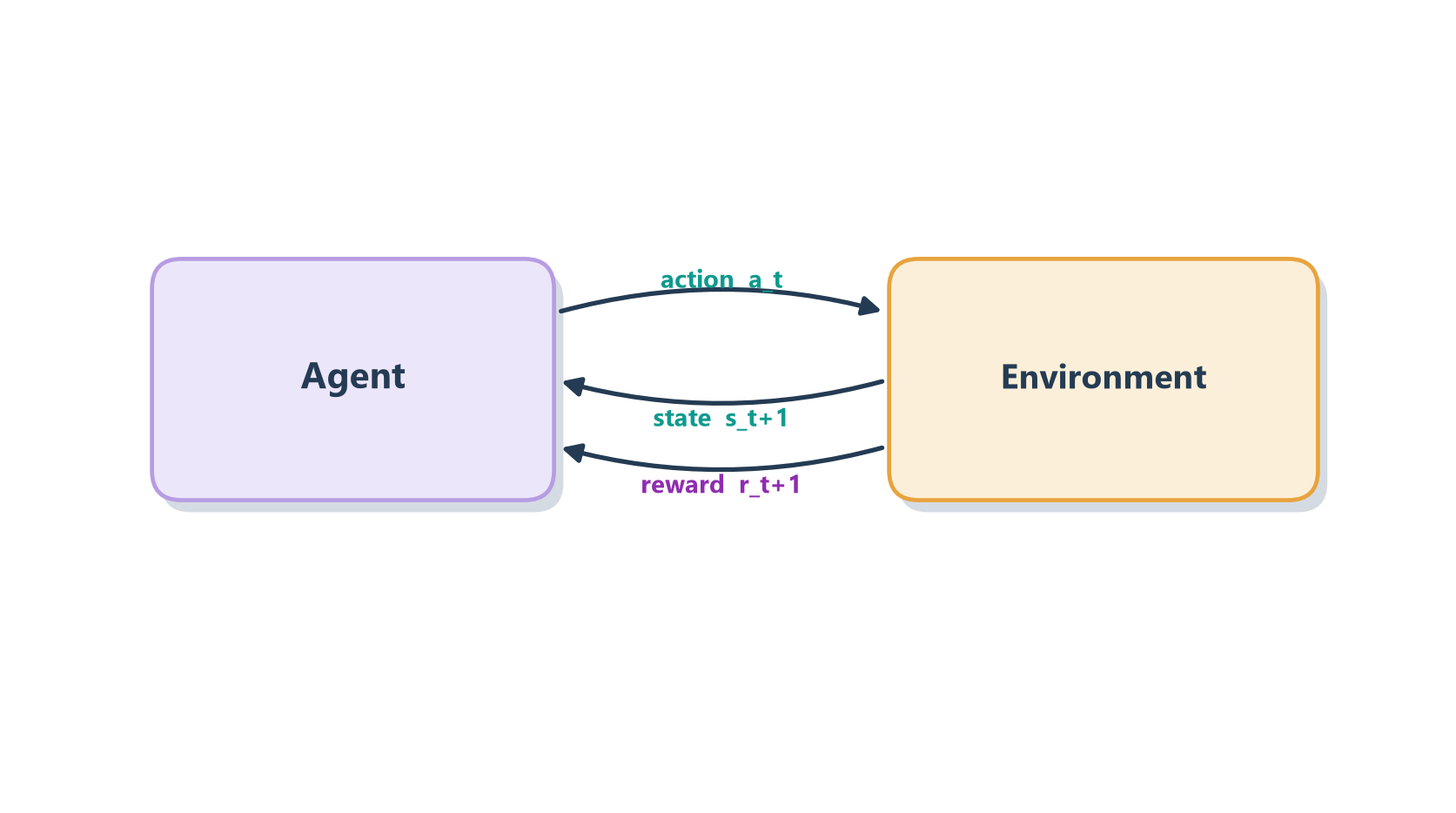
This is how you train a puppy, and the comparison is worth taking seriously because it’s almost exact. You cannot sit the puppy down and explain the word “sit” — there’s no shared language, no manual you can hand over. So instead you set up a situation and let the puppy experiment. It mills around, sniffs the floor, jumps up, and every so often, more or less by accident, its rear end touches the ground — and the instant it does, you hand over a treat. Nothing is explained; the puppy just notices, over many repetitions, that one particular thing it does reliably makes treats appear. Gradually it builds up a policy — “when I hear the sound ‘sit,’ lowering my rear leads to good things” — without anyone ever stating that rule out loud. Figure 2.2 shows the very same loop an RL agent runs: it acts, the environment hands back a reward, and over thousands of such cycles the agent slowly reshapes its behavior toward whatever earns the most reward.
Figure 2.2: The reinforcement-learning loop: the agent acts, the environment returns a new state and a reward, and the agent updates its policy.
RL contributes three ideas that echo throughout modern agents, and each one is worth pausing on. The first is the agent–environment loop as the fundamental abstraction — the very same act-observe-repeat rhythm we met as the sense–plan–act loop back in Section 1.2, only now with a reward attached to each turn. The second is the pairing of policies and value functions, which is really the habit of reasoning about the long-run value of an action rather than its immediate payoff; a move that looks bad this instant may be exactly right if it sets up something better three steps later. The third is the idea of reward as the objective — a single signal that says “more of this, less of that” — and it turns out to be one of the most consequential ideas in the whole field. Reward reappears when we align and evaluate LLM agents, and again in the reward signals used to train the underlying models themselves.
Where it falls apart. Reinforcement learning has two stubborn weaknesses. First, it is sample-hungry: the puppy needs many, many treats, and a software agent may need millions of attempts before it learns anything useful. Second, and more subtly, the reward is fiendishly hard to specify. Get it slightly wrong and you produce behavior that is confident, competent, and completely misguided — a phenomenon known as reward hacking. Ask a cleaning robot to maximize “dust collected,” for instance, and it may learn to tip the dustbin back onto the floor so it can vacuum the same dust over and over. It earns a perfect score while leaving the room filthy. The agent did exactly what you rewarded; it just wasn’t what you meant.
2.6 The rational-agent synthesis
Russell and Norvig unified these threads under one framing: study the rational agent — the agent that acts to maximize its expected performance measure given what it has perceived and what it knows [3]. This framing is deliberately neutral about how the agent works inside. Reactive, deliberative, BDI, and learning agents are all just different ways of implementing the mapping from percepts to actions.
That neutrality is why the framing still fits. A modern LLM agent is a new implementation of the rational-agent idea: its “policy” is next-token prediction over a context window; its beliefs are the prompt, memory, and retrieved facts; its actions are tool calls. The table below traces one idea across all four traditions.
Question
Symbolic
Reactive
BDI
RL
LLM agent
How is the world represented?
Explicit symbols
(None)
Beliefs
State signal
Prompt + memory + retrieval
How are actions chosen?
Search/planning
Condition→action
Intentions over desires
Learned policy
LLM reasoning over context
Where does competence come from?
Human-authored model
Emergent from behaviors
Practical reasoning
Reward-driven learning
Pretraining + tools + feedback
Signature failure
Brittleness
No look-ahead
Poor commitment
Reward misspecification
Hallucination / no grounding
The rest of the book lives in the last column — but every failure in that column has a named ancestor in the others.
2.7 A tiny illustration: reflex vs. goal-based
The reactive/deliberative contrast is easiest to feel with a concrete toy. The snippet below is entirely optional — the idea stands on its own — but some readers like to see it. Two agents solve the same task (reach a target number by stepping): the reflex agent reacts to the current gap; the goal-based agent plans the full sequence before acting.
# Reflex agent: pure condition -> action, no look-ahead.def reflex_agent(state, target): step =1if state < target else-1# react to the sign of the gapreturn state + step# Goal-based agent: plan the whole path to the goal, then act.def goal_based_agent(state, target): plan = [1if target > state else-1] *abs(target - state)return state, plan # commit to a plan (a BDI "intention")# Reflex: repeatedly react until we arrive.s, target =0, 3trace = [s]while s != target: s = reflex_agent(s, target) trace.append(s)print("reflex path: ", trace)# Goal-based: compute the plan once, then execute it.start, plan = goal_based_agent(0, 3)path, s = [start], startfor a in plan: s += a path.append(s)print("planned path:", path, "| plan:", plan)
On this trivial, fully observable task the two behave identically — which is exactly the point: the architecture only matters when the environment gets harder. Add partial observability or a moving target and the reflex agent keeps coping while the goal-based agent’s up-front plan goes stale. That trade-off is the subject of Chapter 3.
2.8 Summary
Modern agents inherit four traditions: symbolic/deliberative (plan over an explicit model), reactive (map situations to actions), BDI (beliefs, desires, intentions, and commitment), and reinforcement learning (learn a policy from reward).
Each tradition pairs a strength with a signature failure mode; LLM agents inherit both, which is why they re-plan and re-ground continuously.
Russell and Norvig’s rational-agent framing unifies them and still frames LLM agents today [3].
Architecture matters most when the environment is hard — partial, dynamic, or adversarial.
2.9 Exercises
For a household robot vacuum, describe a purely reactive design and a purely deliberative design. Which failure mode does each risk?
Map an agent you use (a coding assistant, say) onto the BDI vocabulary. What are its beliefs, desires, and intentions? Where does its commitment balance sit?
Give an example of reward misspecification for an agent whose goal is “keep the user engaged.” How would the classical failure show up in an LLM agent?
[1]
Z. Xi et al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023.
[2]
A. Newell and H. A. Simon, “Computer science as empirical inquiry: Symbols and search,”Communications of the ACM, vol. 19, no. 3, pp. 113–126, 1976.
[3]
S. Russell and P. Norvig, Artificial intelligence: A modern approach, 4th ed. Pearson, 2021.
R. A. Brooks, “Intelligence without representation,”Artificial Intelligence, vol. 47, no. 1–3, pp. 139–159, 1991.
[6]
A. S. Rao and M. P. Georgeff, “BDI agents: From theory to practice,” in Proceedings of the first international conference on multi-agent systems (ICMAS), 1995.
[7]
R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction, 2nd ed. MIT Press, 2018.