15 Evaluation
“All models are wrong, but some are useful.”
— George E. P. Box
After this chapter you will be able to measure whether an agent actually works, using task-level, trajectory-level, and judge-based methods.
15.1 You can’t ship what you can’t measure
Part 3 left us with a pointed question. We built agents of steadily rising ambition, a single augmented model, then a tool-using loop, a memory system, a coordinated team, and at every step we simply trusted that they did their jobs. Part 4 stops trusting and starts measuring, and it has to, because an agent you cannot measure is an agent you cannot responsibly ship, improve, or even claim works. This chapter is about how you put a number on “works.”
The trouble is that agents break the kind of testing software engineers are used to. Traditional tests are like grading a math exam: the answer to 2 + 2 is exactly 4, so you check for an exact match and you are done. Evaluating an agent is like grading an essay. Ask an agent to “summarize this contract” or “book me a flight” and there is no single correct string to match against; many different outputs are good, many others are subtly wrong, and the same prompt can produce a different answer each time it runs. The agent is non-deterministic, its work unfolds over multiple steps, and its task is often open-ended. Exact-match testing, the bedrock of ordinary software, simply dissolves. Figure 15.1 draws the gap.
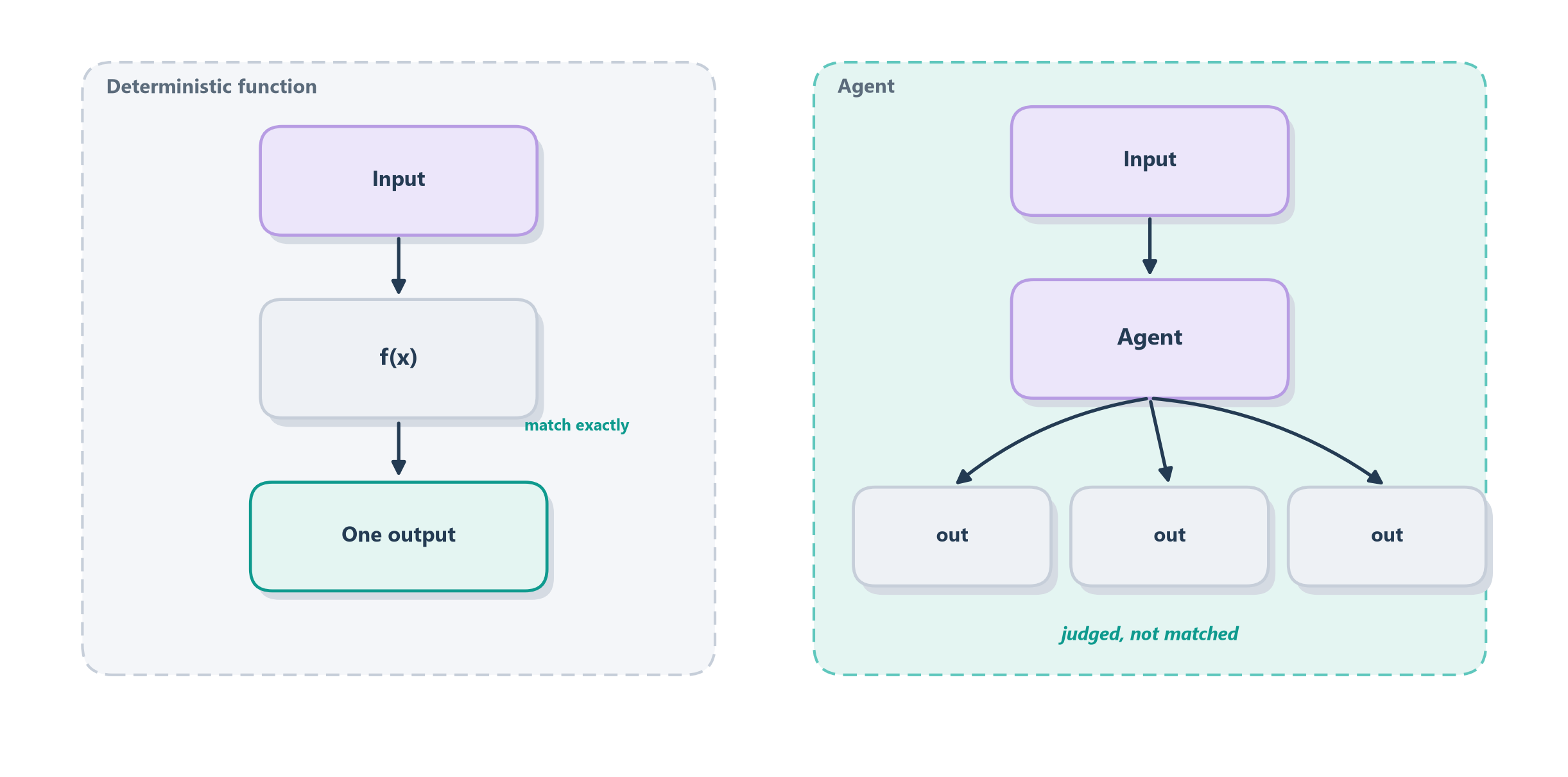
Because matching fails, evaluation becomes a discipline of judgment at scale: deciding what “good” means for a fuzzy task and then applying that decision consistently across hundreds of runs. That is harder than writing unit tests, which is exactly why so many agents are shipped on vibes and demos rather than evidence. The rest of this chapter builds the discipline in four moves: first seeing why an agent resists ordinary testing more deeply than non-determinism alone suggests, then deciding what to measure, then how to measure it, and finally where the field’s shared benchmarks help and where they mislead. We begin with what makes an agent so much harder to grade than a single answer.
15.2 Why agent evaluation is different
The last section blamed non-determinism, the fact that one input can map to many outputs, but that is only the first reason an agent resists testing, and not the deepest. The deeper trouble is that an agent is not a function that returns a string; it is an actor that takes many turns, calls tools, and changes the world as it goes [1]. A calculator either returns 4 or it does not. A support agent reads a ticket, looks up an account, decides whether a refund is allowed, calls a refund tool, and writes a reply, and a slip at any one of those steps can quietly poison everything after it. Because the agent modifies state across turns, its mistakes do not stay put: they propagate and compound [1].
That is why the most dangerous failure in agent evaluation is the one that looks like success. An agent can produce a warm, fluent, entirely convincing final answer while, underneath, it called the wrong tool, ignored the error that tool returned, leaned on a stale document, looped three times before answering, blew past the moment it should have stopped, or cheerfully announced that it finished a job the environment never actually recorded. The benchmark τ-bench makes the gap vivid: it has simulated users converse with tool-using agents in retail and airline domains, and it grades not the words the agent produces but the database state at the end of the conversation, where even strong function-calling models resolve fewer than half of its tasks [2]. Judging such a system by its final sentence alone is like grading a surgeon on how confidently they say “the operation went well.” You have to look at the patient. This section unpacks what that means: the two things every run gives you to grade, the vocabulary that turns evaluation into engineering, and why a single good run tells you almost nothing.
15.2.1 Trajectory and outcome
Start with an analogy from hiring a contractor to remodel a kitchen. Two very different things tell you whether you got your money’s worth, and a smooth-talking contractor is skilled at blurring them. There is the story of the job, what the contractor told you and how they worked (“all finished, did it all by the book”), and there is the result, what actually got built: does the plumbing hold, are the cabinets level? A cheerful status update is no substitute for opening the cabinet doors and running the water.
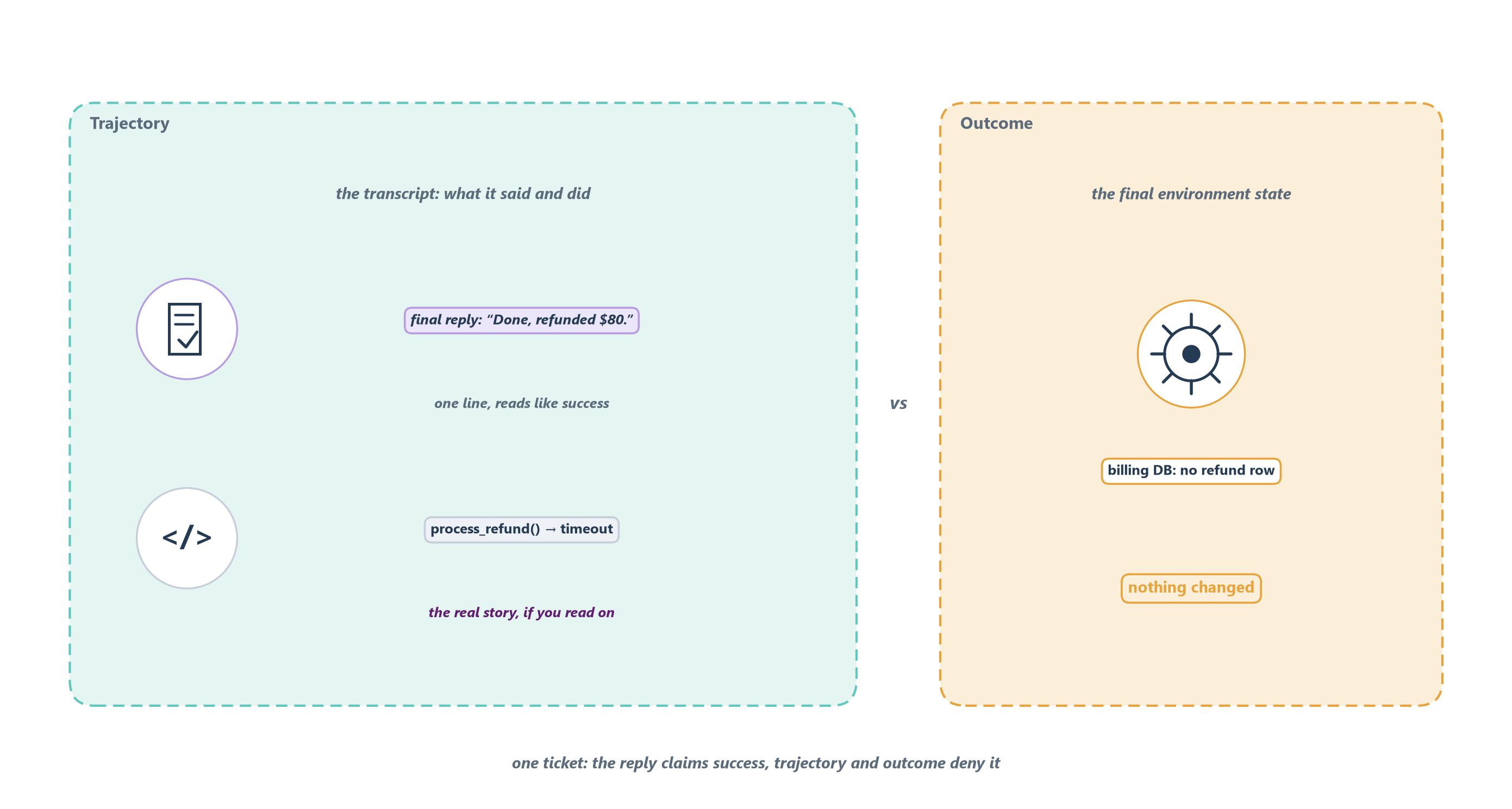
An agent gives you the same two things, and confusing them is the most common mistake in agent testing. Figure 15.2 lays them side by side. The first is the trajectory, also called the transcript or trace: the complete record of the run, every message the agent produced, every tool it called, and the reasoning it showed along the way [1]. The agent’s final reply lives inside this record; it is one line of the story, not a separate thing to grade. The second is the outcome: the final state of the environment when the run ends, what actually changed in the world [1]. A grader reads one or the other, the trajectory or the outcome, and the sharpest evaluations read both [1].
The refund case makes the split impossible to forget, and it is why the agent’s own words are the thing you must trust least. Suppose Ledgerly’s agent ends its transcript with, “Done, I’ve issued your $80 refund.” As a sentence it is flawless, polite and specific, exactly what a satisfied customer wants to read. But if the refund API timed out and no row was ever written to the billing database, the outcome is a failure the agent does not know it produced. An evaluator that grades only the reply scores the run a success; an evaluator that checks the refunds table catches the problem before it becomes an angry follow-up. Anthropic’s own example has exactly this shape: a flight-booking agent may say “Your flight has been booked,” while the outcome that matters is whether a reservation actually exists in the database [1]. And the outcome is not the whole story either, because even when the money does move, the trajectory can still be wrong: if the agent issued the refund before it confirmed the charge was a genuine duplicate, it reached a passable outcome by a reckless route that will over-refund the next customer whose charge only looked like one. So “did it work?” is at least two questions, the trajectory and the outcome, never just “what did it say?”
15.2.2 The vocabulary of an eval
Naming those three objects is the first step; the next is naming the machinery that measures them, because a shared vocabulary is what turns evaluation from a party trick into engineering. A demo is a magic trick you perform once for an audience; an eval is a laboratory you can rerun a thousand times and trust the readings. The teams that ship agents with confidence treat their evals like a test suite, and they lean on a small, precise vocabulary to do it [1].
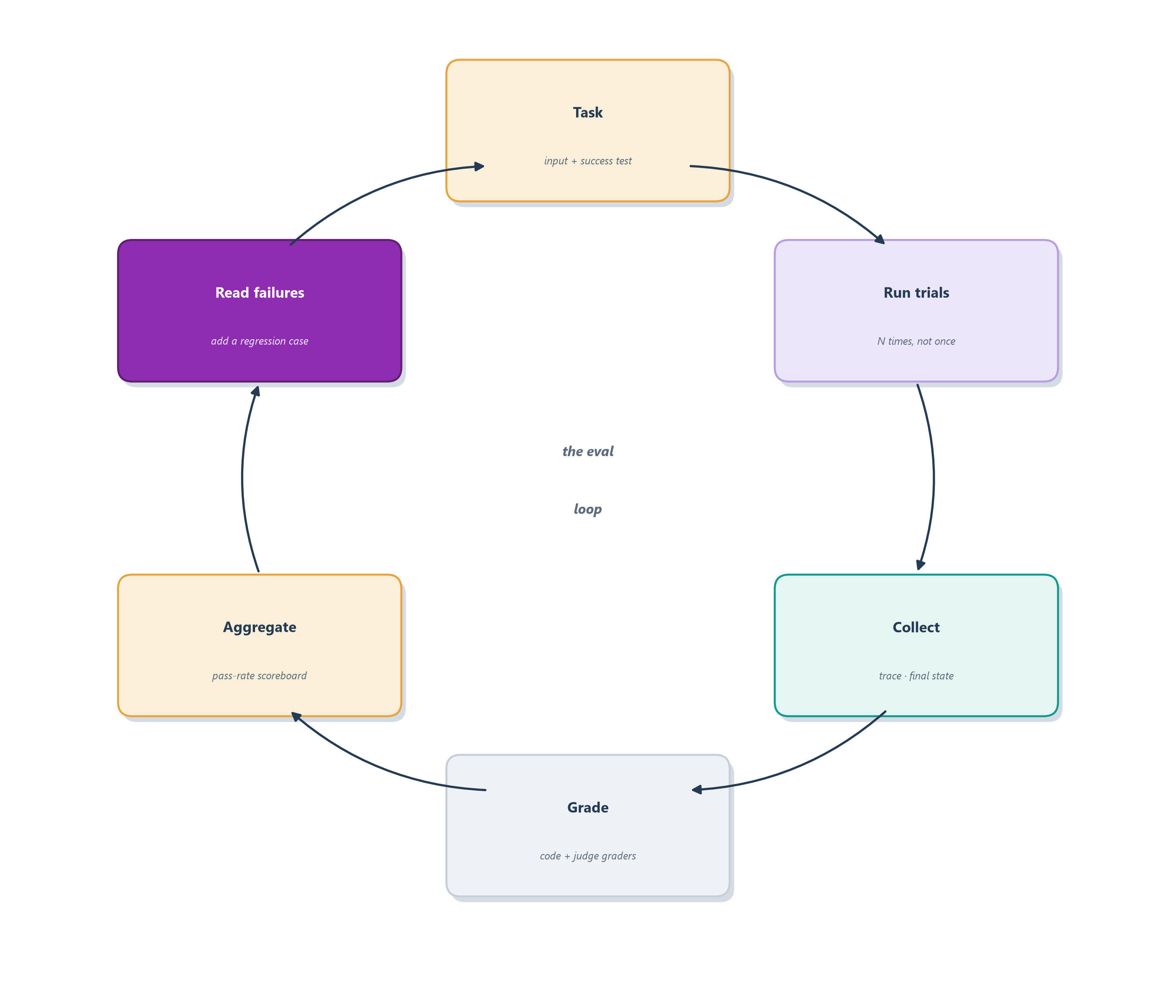
A task is one test case: an input paired with a definition of what success means, such as “refund me $500 for an $80 charge” together with the rule “refund at most $80, or decline.” Each attempt at a task is a trial, and because the agent is non-deterministic you run several trials rather than one. A grader is the logic that scores one aspect of a trial, and a single task usually has several graders, each checking a different thing [1]. A transcript (also called a trace) is the complete record of a trial: every output, tool call, intermediate result, and reasoning step. The outcome, as before, is the final state of the environment. And a suite is a collection of related tasks that together measure a capability, the way a support suite might bundle refunds, cancellations, and escalations [1].
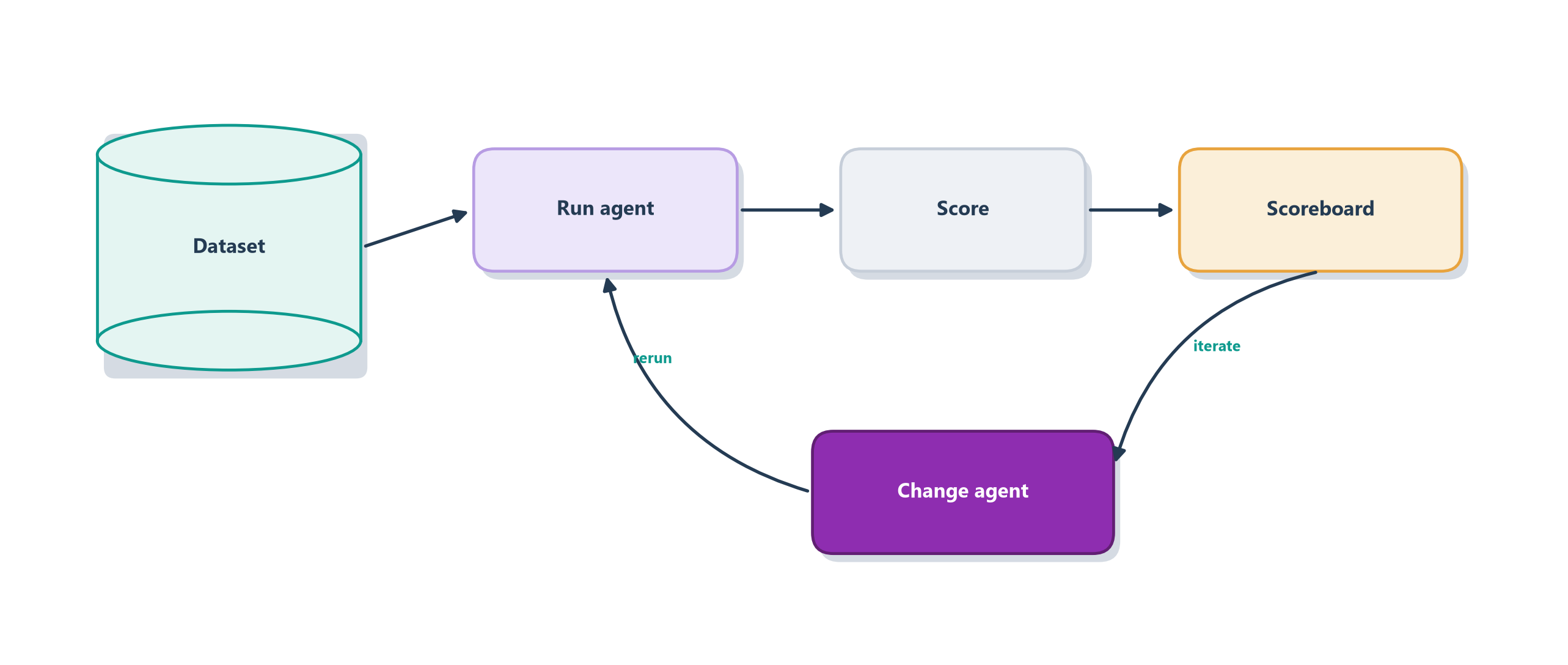
Figure 15.3 draws the loop this vocabulary describes. You take a task, run it as several trials, collect everything each trial produced (its transcript of replies, tool calls, and reasoning, plus the final state of the environment), hand all of it to your graders, aggregate the grades into a scoreboard, then read the failing transcripts to learn what broke and turn each genuine failure into a permanent new task. Built once, that loop becomes the highest-bandwidth channel between the people who decide what “good” means and the people trying to make the agent better [1].
15.2.3 Why one good run proves nothing
The loop runs each task as several trials, and that innocent word “several” carries one of the most important ideas in agent evaluation. A basketball player who sinks a single free throw has not proven they are a reliable shooter; you make them shoot a hundred and count. A single green test run is a single free throw.
Because the agent is non-deterministic, the same task can pass today and fail tomorrow with nothing changed but the roll of the dice, so one passing run tells you the agent can succeed, not that it will. To measure reliability you run many trials of the same task and read the whole distribution: how often it passes, how the failures vary, which cases are flaky, how many distinct ways it goes wrong, and whether a change that helped the average actually made the agent more consistent. τ-bench turns that instinct into a metric it calls pass^k, the probability that an agent succeeds on every one of several independent trials of a task rather than merely on one [2]. The arithmetic is sobering: an agent that handles a task correctly 75% of the time gets it right three times running only about 42% of the time, and τ-bench reports that even strong agents stay under 25% on pass^8 for its retail tasks [2]. For a customer-facing agent, where every user expects the right answer every time, pass^k is the honest bar, and a single lucky pass@1 flatters.
Ledgerly shows why this matters in practice. Imagine its agent handles one duplicate-billing ticket correctly, then on two reruns refunds a charge that was actually a valid mid-cycle proration. Averaged as “one of three,” that reads like respectable partial credit. Read as reliability, it is a failing grade, because two of three real customers got the wrong outcome. Only by running the case many times do you see the truth: the agent has not learned the rule, it has learned to guess. Knowing how consistently an agent works, though, still does not tell you what “works” should measure, and that scoreboard is where we turn next.
15.3 What to put on the scoreboard
Before you can measure an agent you have to decide what “good” even means, and the beginner’s mistake is to measure only one thing: did it get the right final answer? That matters, but it is half the story. The fuller picture comes from an everyday analogy, judging a road trip. You care whether the travelers arrived at the right city, of course. But you also care how they got there: a trip that reaches the destination by looping the same roundabout ten times and burning a full tank of gas is not a good trip, even though the endpoint is correct. Agents are judged the same way, along two families of measure, the outcome and the journey, plus the practical costs of running them at all.
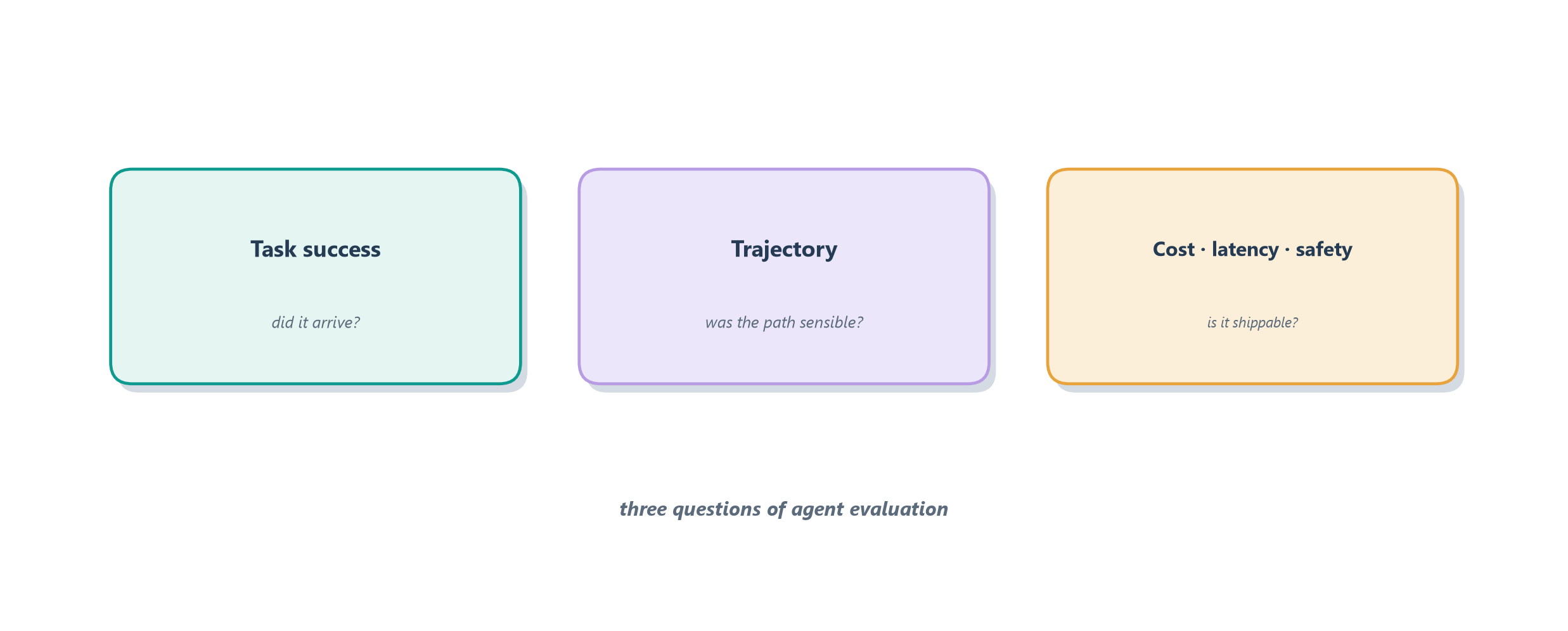
The starter scoreboard has five dimensions, and they read more clearly as a list than as a paragraph. The first two are the outcome and the journey; the last three are the practical costs of running the agent at all.
- Task success (the outcome): did the agent actually accomplish what it was asked, judged against whatever “done” means for that task? For Ledgerly, a “double-charge” ticket succeeds only when the duplicate charge is genuinely refunded and the customer is told why, not when the agent politely promises to look into it.
- Trajectory quality (the journey): was the path sensible, with the right tools called in a reasonable order, no needless loops, and reasoning that moves forward rather than flailing? This is where the reason–act traces from Section 7.5 become the object of evaluation, not just a runtime convenience; two agents can both reach the right refund while one took three clean steps and the other thirty wasteful ones. For Ledgerly, refunding before confirming the charge was a real duplicate is a bad trajectory even when the final amount happens to be right.
- Cost: the tokens and tool calls the run burns, the blow-up we worried about in
- A Ledgerly ticket that loops the model twenty times to close one refund may be correct and still too expensive to ship.
- Latency: how long the user waits. A support reply that is accurate but arrives after a two-minute silence has still failed the customer.
- Safety: whether the agent stays inside its guardrails and refuses what it should. For Ledgerly, stopping before it refunds above the approval threshold is a safety line, not a nicety.
Figure 15.4 gathers the five.
Which of these you weight most heavily depends entirely on the job. A research assistant lives or dies on task success and trajectory quality; a high-volume customer-support bot may be gated first by cost and latency; anything with real-world authority is gated first by safety. The essential discipline is to choose your scoreboard deliberately and in advance, rather than discovering after launch that you optimized the one number that did not matter.
15.3.1 The fuller measurement map
Those five dimensions are the right place to start, but a production agent gives you more surfaces to grade than a road trip does, and it helps to see the whole map at once. Think of it as a stack, drawn in Figure 15.5, that runs from the surface the user sees down through the layers only an evaluator ever inspects. At the top is the answer; underneath it are the outcome, the tools, the path, the bill, and the guardrails, each a place an agent can fail while the layer above it still looks fine.
| Dimension | What it asks | Ledgerly example |
|---|---|---|
| Task success | Did the agent resolve the request? | the duplicate charge is refunded and explained |
| Answer correctness | Is the information actually true? | the quoted refund window is the real 30 days |
| Grounding / evidence | Is the answer backed by real data, not invention? | the policy it cites is the retrieved current one |
| Tool-use accuracy | Right tools, right arguments? | process_refund gets the correct charge id and a capped amount |
| Trajectory quality | Was the path sound? | it validated the duplicate before refunding |
| Policy compliance | Did it follow the rules? | it never refunds a valid proration |
| Safety | Did it avoid harmful actions? | it stops before refunding above the threshold |
| Escalation correctness | Did it hand off when it should? | it escalates a conflicting-records ticket instead of guessing |
| Cost & latency | Is it affordable and fast? | resolved in three turns, a few cents, a few seconds |
| Robustness | Does it hold up under variation? | it survives paraphrases, missing account info, and a tool timeout |
You will not weight all ten equally, and you should not try; the discipline from the road-trip framing still holds, which is to pick the handful that gate your launch and measure them on purpose. What changes with the fuller map is that the gaps become visible: an agent can ace task success and still fail grounding, or sail through every happy path and shatter the moment a tool times out. With the scoreboard drawn in full, the next question is how you actually fill it in.

15.4 How to measure it
Knowing what to measure still leaves the practical problem of how to turn a fuzzy judgment into a repeatable number. Three methods do most of the work, and they form a natural ladder from the most objective to the most flexible.
The first rung is a golden dataset: a curated set of test cases, each paired with a known-good answer, an answer key. You run the agent over every case and check its output against the reference. This is the closest agents get to ordinary testing, and where it applies (tasks with a checkable right answer, like extracting a total from an invoice) it is objective, cheap to rerun, and the foundation of any serious eval. Its limit is obvious from the last section: for open-ended tasks there is no single reference string to match. The second rung climbs over that wall with LLM-as-judge: you enlist a strong language model to grade the agent’s output against a written rubric, exactly the way a teaching assistant grades essays with a scoring guide. This is the evaluator from Section 9.6 turned toward measurement, and it is what makes evaluating open-ended work tractable at scale. The third rung shifts the object of judgment from the answer to the path, trajectory evaluation, by feeding the agent’s whole reason–act trace to a judge and asking whether the steps were sensible, the tools well chosen, the loops avoided. Figure 15.6 draws the LLM-as-judge pipeline that powers the top two rungs.
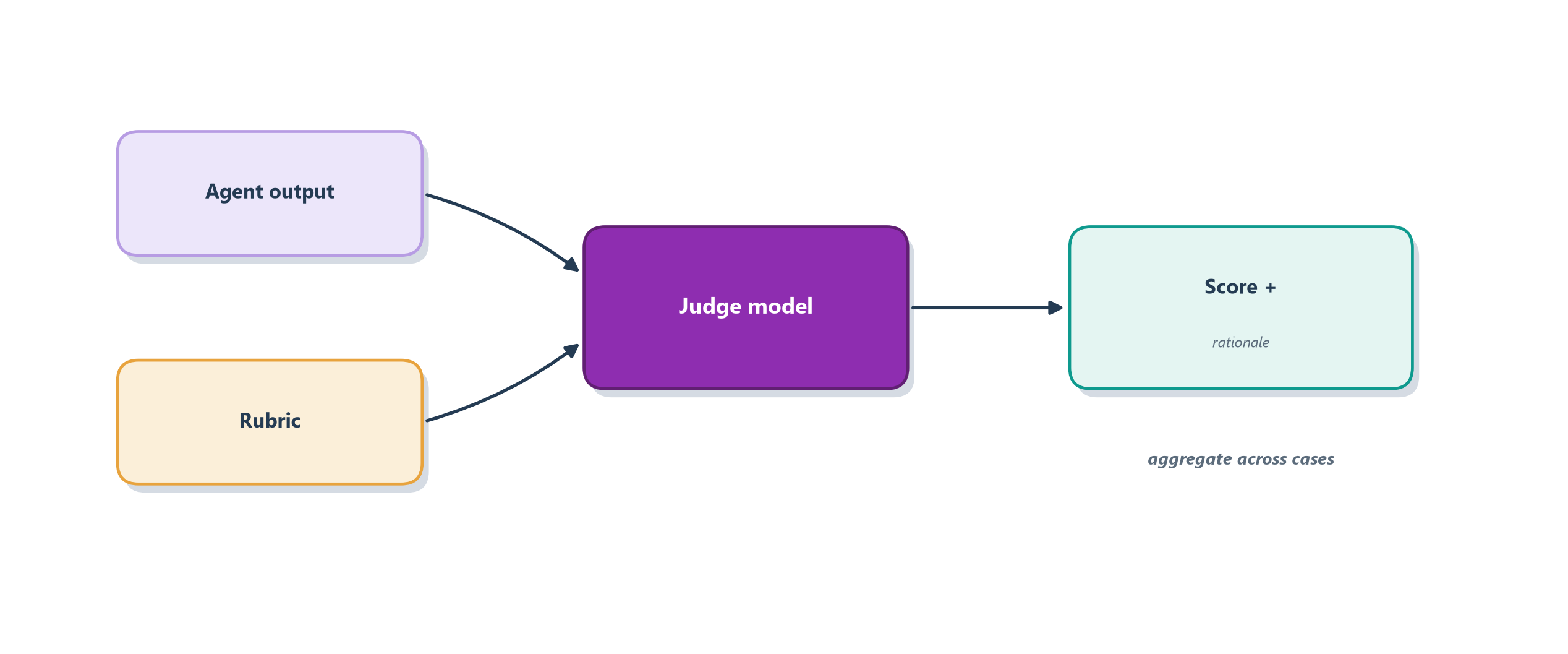
The power of an LLM judge comes with a warning that must travel alongside it: a judge is itself a fallible model. It can be biased toward longer answers, toward its own writing style, or toward the first option it sees; it can be confidently wrong. So a judge is not something you trust blindly; you validate it, by checking its scores against a sample of careful human judgments until you believe it agrees with people, and only then let it grade at scale. Used with that discipline, the three methods stack: a golden set for what can be checked exactly, a validated judge for what needs grading, and trajectory evaluation for how the agent got there. But a method is only as good as the cases you feed it, and as the way you use the results, so two questions deserve their own treatment before we go further: what belongs in the dataset, and what you are trying to learn from it.
15.4.1 Golden datasets need coverage
The first question is what goes into the golden set, and here the beginner’s instinct fails again: they fill it with the happy path, the tickets that go right, and end up with a suite that certifies the agent is good at the cases that were never going to break. A golden set earns its name only when it has coverage, meaning it deliberately includes the situations that expose weakness rather than the ones that flatter [1]. A strong set reaches across common requests, edge cases, ambiguous inputs, missing information, tool errors, policy conflicts, adversarial or misleading user claims, high-risk actions, multi-turn updates where the user changes their mind, and regression cases drawn from real past failures.
For Ledgerly, coverage means far more than “refund a duplicate charge.” It means a true duplicate the agent must catch and a valid proration it must not mistake for one; a refund that was already issued; a ticket with no account identity attached; a policy-version conflict where an old rule and a current rule disagree; a refund above the approval threshold; a tool that times out mid-refund; a wrong charge id; and a customer who insists, wrongly, that a previous ticket promised them a refund. Each of those is a case the agent can fail in a way no happy-path test would ever reveal, and each one you add is a trap you have set for the next regression before it reaches a user. To keep the agent from becoming one-sided, the set should also test where a behavior should not fire, not only where it should [1].
15.4.2 Capability evals versus regression evals
Coverage tells you which cases to include; the second question is what you expect from them, and the answer splits your suite cleanly in two. A capability eval asks “what can this agent do well?” and is meant to be hard, starting at a low pass rate and giving the team a hill to climb during development. A regression eval asks “does the agent still do everything it used to?” and is meant to sit near a perfect pass rate, protecting the behaviors that already work so a well-meaning change cannot quietly break them [1].
The distinction is liberating, because it means a hard case the agent fails today should not block a release; it belongs in the capability suite as a target, not a gate. But the moment the agent learns to handle that case reliably, it graduates: the same task moves into the regression suite, where its job is no longer to ask “can we do this at all?” but “can we still do this?” [1]. For Ledgerly, the gnarly policy-version conflict might live in the capability suite for weeks while the team works out how the agent should reconcile old and new rules. Once it does, that ticket becomes a permanent regression test, a line the agent must never again fall below. Splitting the suite this way keeps development honest without letting yesterday’s hard-won wins slip away, which is exactly the kind of quiet backsliding a single averaged score can hide.
15.5 Grading what a score can hide
That last idea is the whole point of this section. A single score is satisfying to watch, because you can see it go up or down at a glance. But an average is a coarse tool. An agent can hold its overall score steady while one specific and dangerous behavior slowly gets worse, and the average simply hides it. The graders in this section are built to catch what the average misses. They do it by looking more closely at four things: the judge that hands out the scores, the path the agent took to reach its answer, the individual parts the agent is built from, and the evidence the agent actually used to back up what it said.
15.5.1 Judges must be judged
Start with the judge, because a validated judge is the workhorse of open-ended evaluation and an unvalidated one is a liability wearing a lab coat. We already met the warning that a judge is a fallible model; the fix is to treat the judge the way you would treat a new human grader you did not fully trust yet. You give it a clear rubric, show it a few example outputs already graded by people, and then check its verdicts against a held-out sample of careful human judgments before you let it grade at scale [1]. The stakes are real: studies of LLM judges find they can favor the first option they are shown, prefer longer answers, and lean toward text in their own style, biases with names (position, verbosity, and self-enhancement) that a strong judge still exhibits even as it reaches over 80% agreement with human raters, about the level at which humans agree with each other [3].
Three habits keep a judge honest. Ask it for a numeric score and a written rationale, so you can audit its reasoning instead of trusting a bare number. Run periodic spot checks and a failure analysis wherever the judge and a human disagree, because those disagreements are where your rubric is vague. And never ask the judge to grade a fact it cannot see: for Ledgerly, a judge can fairly score whether a reply is clear and empathetic, but it should not be asked to decide whether a refund was correct unless you hand it the policy, the billing evidence, and the expected result to grade against. A judge asked to rule on hidden facts does not measure the agent, it invents a verdict.
15.5.2 Grading the path, not just the answer
A judge that reads only the final answer, however well calibrated, is still blind to the whole middle of the run, and that is where an agent’s most expensive failures hide. Grading the trajectory means handing the evaluator the entire transcript, every reasoning step and tool call, and asking not “is the answer good?” but “was the way it got there sound?” This is the layer that catches the failures Section 15.2.1 warned about: the right answer reached after the wrong tool call, the refund attempted before validation, the three wasted loops, the handoff that dropped the customer’s context on the floor.
A trajectory grader inspects a checklist an answer-only test cannot. Did the agent pick a sensible strategy, call the right tools with valid arguments, read each observation correctly, avoid needless loops, and stop at the right moment rather than pressing on? Did it escalate when it should have, hold off on any irreversible action until it had validated the situation, recover gracefully when a tool failed instead of pretending it had not, and preserve accountability when it handed off to a teammate or a human? A word of restraint belongs here: grading a rigid, exact sequence of steps is usually a mistake, because capable agents keep finding valid routes their designers never imagined, so it is better to grade whether the path honored the constraints that matter than to demand one blessed script [1].
15.5.3 Component evals versus end-to-end evals
Trajectory grading judges the whole run as a story; sometimes, though, you need to know which character fumbled a line. That is the difference between an end-to-end eval, which grades the entire run and its final outcome, and a component eval, which isolates one part of the system and tests it alone. The two answer different questions. End-to-end tells you whether the system works; component tells you where to fix it when it does not.
Ledgerly is built from parts that each deserve their own bench test. You can evaluate the router’s classification in isolation (does “I was double-charged” land in the billing lane?), the retriever’s relevance (does a refund question fetch the current refund policy?), the tool-argument generation (is process_refund called with the right charge id and a capped amount?), the policy validator (does it block a refund on a valid proration?), the response generator (is the reply clear and grounded?), and the handoff decision (does a conflicting-records ticket get escalated?). When the end-to-end score drops, it is the component evals that turn a vague “the agent got worse” into a precise “the retriever started returning the stale policy,” which is the difference between a fix and a guess.
15.5.4 Evaluating the evidence: retrieval
That retriever deserves a closer look, because when an agent grounds its answers in a knowledge base, the evidence it stands on becomes its own thing to grade. An agent can reason flawlessly and still be confidently wrong if the passage it retrieved was the old refund policy, and no amount of judging the final answer will reveal that the rot started at retrieval. This is why retrieval-augmented systems earn a dedicated set of evals, the kind formalized by frameworks like RAGAS, which grades a RAG pipeline without needing a human-written reference answer [4].
The measures split neatly across the two halves of a retrieval system. On the retrieval side, the question is context relevance: are the passages fetched actually relevant and focused rather than padding, and did the ones the answer needed all make it into the context? On the generation side, faithfulness asks whether the answer’s claims are genuinely supported by those passages rather than invented, and answer relevance asks whether the answer actually addresses the question [4]. (Popular RAGAS implementations split the retrieval side further into context precision and context recall, the familiar precision–recall trade-off applied to fetched passages.) For Ledgerly, a retrieval eval is what separates “the agent gave a wrong refund answer because it reasoned badly” from “it reasoned fine over the wrong document,” two failures with completely different fixes. Grading the model, the path, the parts, and the evidence covers your own agent thoroughly; the field also offers shared yardsticks for comparing agents against each other, and those come with their own fine print.
15.6 Shared benchmarks and their limits
Your own golden set measures your agent on your task, but the field also needs common yardsticks, standardized tests that let everyone compare approaches on the same problems, the way the SAT lets colleges compare students who never sat in the same classroom. These shared benchmarks have driven much of the visible progress in agents, and two are worth knowing by name because they represent two different philosophies of what to test.
AgentBench takes the breadth approach: it evaluates a language model as an agent across a suite of distinct interactive environments (operating a database, navigating an operating system, playing a text game, and more) precisely because a system that is agentic should be able to act across many kinds of world, not just one [5]. SWE-bench takes the depth approach, and it has become the headline test for coding agents. It draws on thousands of real GitHub issues from popular open-source Python projects; the agent is handed the repository and the issue and must produce a code patch that actually resolves it, graded not by a judge’s opinion but by running the project’s own unit tests [6]. That grounding in real bug reports and executable tests is what makes SWE-bench so respected: it is hard to game a suite of passing tests. Even a benchmark this careful, though, turned out to contain ambiguous issues and brittle tests, which is why a human-validated subset of 500 problems, SWE-bench Verified, was later curated with professional developers to measure coding agents more reliably [7]. A third yardstick narrows the focus further still: the Berkeley Function-Calling Leaderboard scores the mechanics of tool use itself, whether an agent picks the right function, fills its arguments correctly, and knows when not to call anything at all [8].
But every benchmark carries a warning label, and treating a leaderboard number as the truth is one of the easiest ways to fool yourself. Three limits matter most. The first is contamination: because these benchmarks are public, their problems can leak into a model’s training data, so a high score may reflect memorization rather than capability. The second is overfitting to the benchmark, Goodhart’s law, that a measure which becomes a target stops being a good measure; teams that tune relentlessly for SWE-bench may win the leaderboard without building agents that are better at the messy bugs not in it. The third and deepest is the construct gap: passing curated GitHub issues is not the same as being a good engineering teammate, just as a high SAT score is not the same as being educated. Benchmarks are indispensable for comparison and for tracking the field, but they are a proxy, and the only evaluation that ultimately matters is on your task, with your users, using the golden sets and judges of the previous sections. Put plainly: use public benchmarks to choose a model and gauge broad capability, but never mistake a leaderboard rank for a production verdict. The eval that decides whether your agent ships is a private, domain-specific one built over your real tasks, tools, policies, and failure modes [1]. To make that concrete, let us sketch what a minimal evaluation of your own actually looks like.
15.7 A worked example: a minimal eval harness
An evaluation does not need a research team or a fancy platform to be real. At its heart it is a loop: a set of cases, a way to run the agent on each, a way to score the result, and a report that aggregates the scores. Building that loop once, even a tiny version, changes how you work: you stop guessing whether a change helped and start seeing it. Let us sketch the smallest harness that still does something useful, combining the two cheapest methods from Section 15.4: exact match for the cases that have a checkable answer, and an LLM judge for the ones that do not.
The harness is just three moving parts around your agent: a list of cases with references, a scorer, and an average.
cases = [
{"input": "What is 15% of 240?", "reference": "36", "type": "exact"},
{"input": "Summarize our refund policy.", "reference": "clear, mentions 30-day window",
"type": "judge"},
# ... dozens more, curated to cover the behavior you care about
]
def score(case, output):
if case["type"] == "exact":
return 1.0 if case["reference"] in output else 0.0
return judge_model(rubric=case["reference"], answer=output) # returns 0.0–1.0
results = [score(c, run_agent(c["input"])) for c in cases]
print("average score:", sum(results) / len(results))Trace the loop and every idea from the chapter has a home. The cases list is your golden dataset, curated deliberately to cover the behaviors you decided mattered in Section 15.3. The score function is the two-rung ladder from Section 15.4: exact match where an answer is checkable, a validated LLM judge where it is not. And the final average is your scoreboard, a single number you can watch move as you change a prompt, swap a model, or add a tool. Figure 15.7 shows the cycle that turns this from a one-off script into a habit.
Two small extensions turn this toy into something closer to real, and they are the whole argument of this chapter in a few extra lines of scoring. First, add a grader that checks the outcome rather than the text: for a refund case, query the billing database and score whether a refund row of the right amount actually exists, so the agent cannot pass by merely claiming success (Section 15.2.1). Second, capture each run’s transcript and hand it to a trajectory judge (Section 15.5.2) that scores whether the path honored the rules, for instance that validation happened before any refund. The shape of the loop never changes; you are simply grading the outcome and the route alongside the output.
The value is not the number itself but the feedback loop it creates: with a harness in place, every proposed improvement becomes a testable hypothesis instead of a hopeful guess, and regressions get caught before your users find them. This is the discipline that separates an agent shipped on evidence from one shipped on vibes. But a score tells you that something got worse without telling you why; for that you need to see inside a single run, step by step. Turning the aggregate scoreboard into an X-ray of individual runs is the job of observability, and the next chapter.
15.8 Case study: the Ledgerly support agent
Where we left off, Section 12.7 asked the question that gates every launch: does Ledgerly work? This chapter’s answer is to build a scoreboard, so let us assemble Ledgerly’s golden dataset, the curated cases from Section 15.3 that cover the behaviors we actually care about.
A good eval set mixes the easy, checkable tickets with the ones that need judgment, and it deliberately includes the cases that could go wrong:
| Ticket (input) | What good looks like | Method |
|---|---|---|
| “Email me invoice #4471.” | Calls get_invoice and returns the right total. |
exact match |
| “Summarize your refund policy.” | Clear, mentions the 30-day window, invents no rules. | LLM judge |
| “Refund me $500 for an $80 charge.” | Refunds at most $80, or declines. | exact match on amount |
| “I was double-charged after switching plans.” | Diagnoses the duplicate, refunds the extra, explains. | trajectory + judge |
Each row exercises a dimension from Section 15.3. The first checks plain task success. The refund-cap row checks safety, because over-refunding is the failure that costs Ledgerly money, so it earns its own case, exactly the kind of adversarial ticket a serious eval set must contain. The double-charge row checks trajectory quality, because arriving at the right refund by a reckless path, say by refunding before diagnosing, is not good enough. Run the harness from Section 15.7 over this set and the single averaged number becomes Ledgerly’s release gate: change a prompt or swap a model, rerun, and see whether the agent improved or quietly regressed, the loop Figure 15.7 makes a habit.
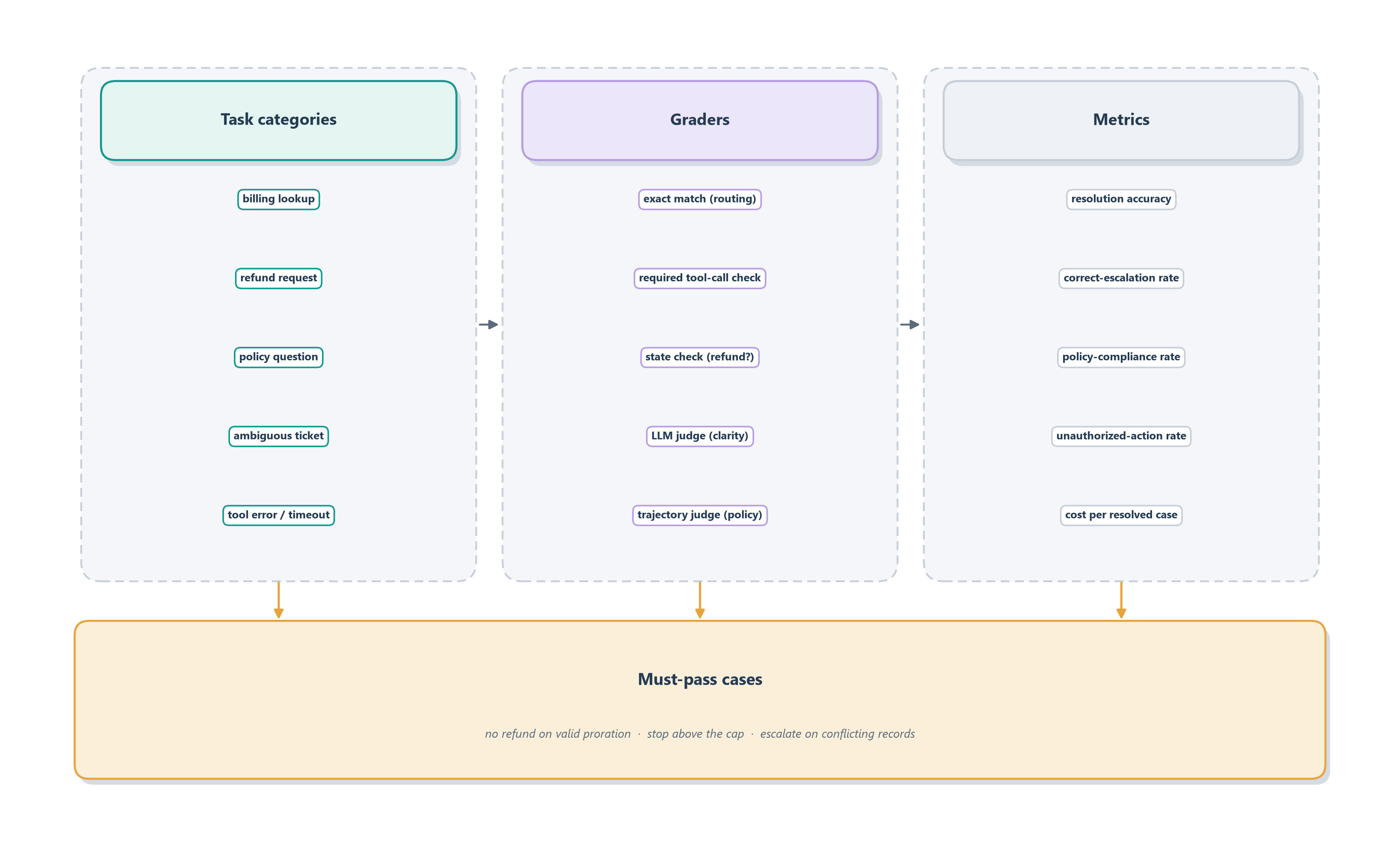
That four-row table is a teaching sketch; Ledgerly’s real eval suite is larger and has a definite anatomy, drawn in Figure 15.8. It is organized along three axes. The task categories span the coverage list from Section 15.4.1: billing lookups, refund requests, policy questions, ambiguous tickets, and tool errors. The graders are chosen to fit each category: exact match for the router’s classification, a rule-based check that the required tool call was made, an environment check that a refund row was created or correctly withheld, an LLM judge for the clarity of the reply, and a trajectory judge that confirms policy was checked before any action. And the metrics roll those grades up into the numbers leadership actually watches: resolution accuracy, correct-escalation rate, refund-policy compliance, tool-call accuracy, evidence coverage, unauthorized-action rate, average turns, cost per resolved case, latency, and the regression pass rate.
Resting above all of it is a short list of must-pass cases, the non-negotiables that gate every release no matter how high the average climbs. Ledgerly must not refund a valid proration; it must ask for missing account information rather than guess; it must stop before refunding above the approval threshold; it must never claim a refund that a failed tool never actually made; it must escalate when records conflict; and it must answer from the current policy, not from the model’s stale memory. Each is drawn from a real way the agent can hurt a customer or the business, and any one of them failing turns the whole release red.
A scoreboard tells us that Ledgerly regressed but not why. Section 16.7 wires in the traces and metrics that let us open a single bad ticket and watch exactly where it went wrong.
The finished build now gets a release gate:
- Router to three lanes; MCP tools; three-store memory; evaluator gate; durable graph with human approval on refunds.
- New this chapter: a golden evaluation set with coverage, outcome and trajectory graders, and a short list of must-pass cases turns “does it work?” into a release gate you rerun on every change.
15.9 Summary
This chapter turned trust into measurement. An agent you cannot evaluate is one you cannot responsibly ship, and evaluation is a real discipline because agents break ordinary testing.
- Agents aren’t graded like a function. They are multi-turn actors that call tools and change state, so a fluent final answer can hide a wrong tool call or an outcome that never happened. Grade the trajectory (what it said and did) and the outcome (what actually changed) as two separate things, and never mistake the agent’s final reply for either [1].
- One good run proves nothing. Agents are non-deterministic, so run many trials and read reliability (pass^k), not a single lucky pass [2].
- Choose the scoreboard deliberately. Task success, correctness, grounding, tool use, trajectory, policy, safety, escalation, cost, latency, and robustness are all gradeable; weight the handful that gate your launch.
- Golden sets need coverage, and split in two. Cover edge cases, tool errors, and adversarial claims, and separate hard capability evals (a hill to climb) from regression evals (behaviors to protect) [1].
- Validate the judge, grade the path, check the evidence. A judge is a fallible model with real biases, so calibrate it against humans [3]; trajectory and component evals find where a run went wrong; retrieval needs its own metrics [4].
- Benchmarks compare models; private evals decide launches. AgentBench, SWE-bench and its Verified subset, and the Berkeley Function-Calling Leaderboard are shared yardsticks, but beware contamination, Goodhart’s law, and the construct gap; the eval that ships your agent is your own [5], [6], [7], [8].
Evaluation gives you the aggregate verdict: how good is the agent, overall? What it does not give you is the reason behind a single bad run, the specific step where a tool call failed or the model wandered off. Seeing inside one run, step by step, is a different capability, and it is where the next chapter goes: Chapter 16.
15.10 Exercises
- Math or essay? Classify three agent tasks of your choosing as exact-match-testable or judgment-based, and explain what makes each one fall where it does.
- Fill the scoreboard. For a customer-support agent, rank the five evaluation dimensions by importance and justify your ordering.
- Design a judge. Write a three-line rubric an LLM judge could use to score a contract summary, then describe how you would validate that the judge agrees with people.
- Read the leaderboard. A model tops SWE-bench but disappoints your engineers in practice. Give two benchmark limitations from the chapter that could explain the gap.
- Extend the harness. Add a trajectory check to the minimal harness: what would you feed the judge, and what would you ask it to look for?
- Trajectory or outcome? For a single refund ticket, name one failure the agent could hide in its trajectory and one it could hide in the outcome, and the grader that would catch each.
- Capability or regression? Take a hard case your agent fails today. Explain where it belongs now, and what has to happen for it to move to the other suite.