12 Orchestration with LangGraph
“The conductor of an orchestra doesn’t make a sound. He depends, for his power, on his ability to make other people powerful.”
— Benjamin Zander, The Art of Possibility
After this chapter you will be able to build stateful, controllable agents as graphs with LangGraph, including checkpoints and human-in-the-loop.
12.1 Opening intuition
Look back over the last several chapters and you will notice we have been drawing the same kind of picture again and again: the decision guide in Section 8.7, the five patterns in Chapter 9, the reason–act loop in Section 7.5. Every one was a diagram of boxes and arrows, the steps and the paths between them. Those diagrams were meant as explanations, but here is the idea that opens this chapter: what if the diagram were the program? What if, instead of translating a flowchart into a tangle of if statements and while loops by hand, you could hand the flowchart itself to the computer and say “run this”? That is precisely what a graph orchestration framework lets you do, and LangGraph is the one we will use to make it concrete [1].
The durable concept underneath, the part worth remembering long after any particular framework fades, is that an agent is naturally a graph of steps operating over shared state. Picture a board game. There is a board with spaces connected by paths (that is the graph), a game piece sitting on one space at a time (that is where control currently is), and a shared scoreboard every move reads from and writes to (that is the state). A turn consists of doing what the current space says, updating the scoreboard, and following an arrow to the next space, sometimes a fixed arrow, sometimes a choice that depends on the scoreboard. An agent is exactly this: nodes that do work, a shared state they all read and update, and edges that decide where to go next. Modeling it this way is old and battle-tested; engineers call it a state machine, and it has run everything from traffic lights to spacecraft.
Why reach for a framework at all, when we hand-rolled a perfectly good while loop back in Section 6.6? Because that loop was the simplest possible agent, and real systems outgrow it fast. Once you need branching, retries, loops that can pause and resume, human approvals, and state that survives a crash, a hand-written control flow curdles into a knot that is hard to follow and harder to debug. A graph framework gives you that structure explicitly: the shape of the agent becomes a thing you can see, inspect, and reason about, rather than behavior buried in nested conditionals. That clarity is the payoff, though, as we will keep in mind, a framework is a tool with costs as well as benefits. Let’s start by laying out the board: the handful of core concepts from which every LangGraph agent is built.
12.2 Core concepts
LangGraph builds every agent from four ideas, and they line up one-to-one with the board-game picture, so you already have the intuition for all of them [1]. The first is state: a single shared object, in Python usually a typed dictionary, that holds everything the agent knows right now. It is the scoreboard, and for a chat agent it typically carries at least the running list of messages. Every step reads from it and writes back to it; the state is the agent’s working memory made explicit.
The second idea is nodes, which are simply the spaces on the board where work happens. A node is an ordinary function that receives the current state and returns an update to it. One node might call the LLM; another might run a tool; another might query the vector store from Chapter 11. Nodes are deliberately dumb about the big picture; each just does its one job and reports what changed. The third idea, edges, is what wires the nodes together and decides what runs next. Some edges are fixed, after node A always go to node B, and some are conditional: instead of a fixed destination, a small routing function looks at the current state and chooses the next node. Conditional edges are where the intelligence of the control flow lives; they are the board-game rule “if your score is over 20, take the shortcut.” Figure 12.1 assembles the four pieces.
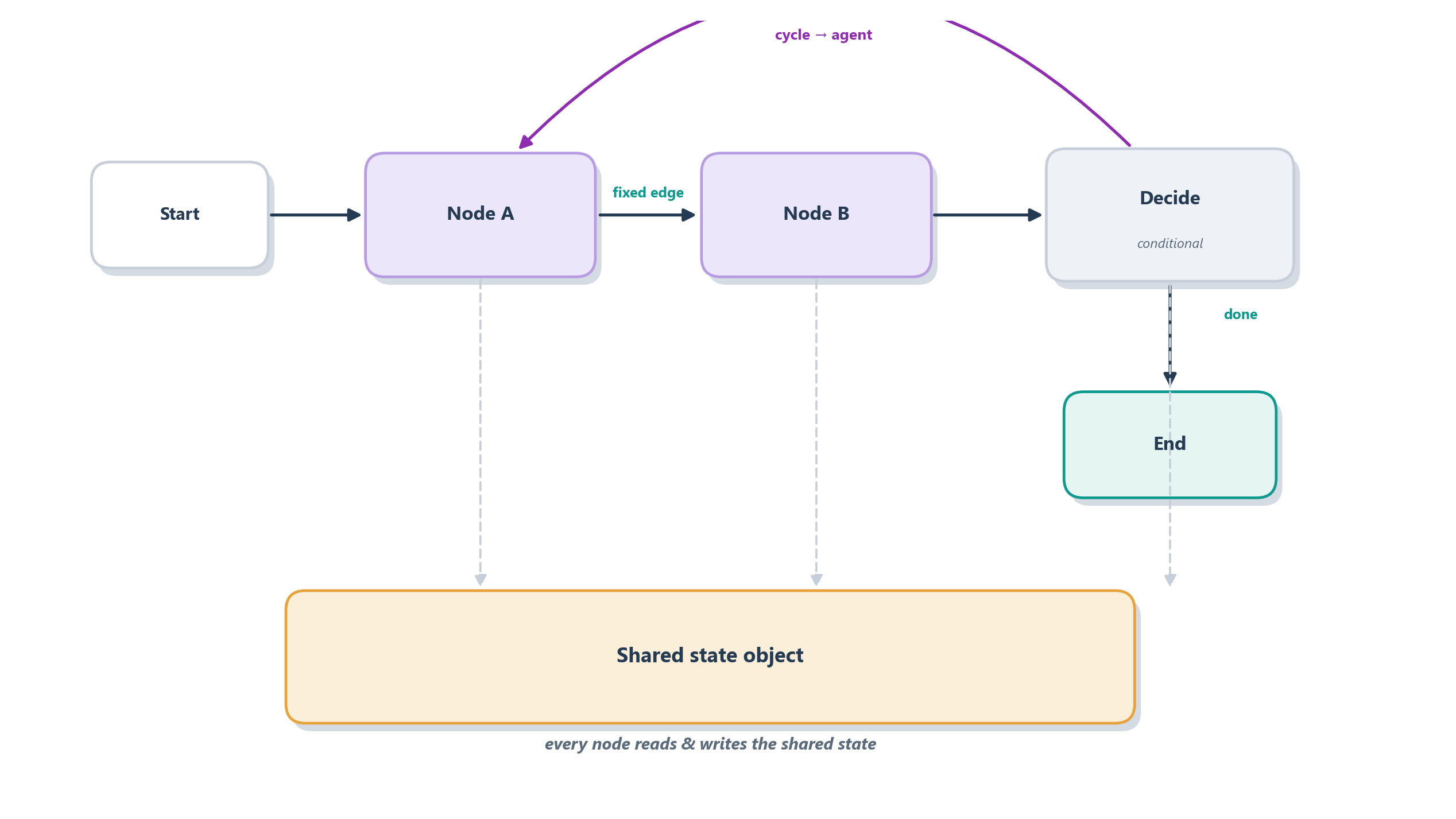
That loop from the tool node back to the model node is the fourth and most important idea: cycles. A plain data pipeline is a one-way street, a directed acyclic graph, steps flowing forward and never back. But an agent is not a pipeline; it is a loop that thinks, acts, observes, and thinks again, exactly the shape we drew for ReAct in Section 7.5. LangGraph’s defining feature is that its edges are allowed to cycle, so the graph can send control back to an earlier node and go around as many times as the task demands. That is what makes it a framework for agents rather than merely for workflows. Everything else, persistence and human oversight, is built on top of this small, sturdy foundation of state, nodes, edges, and cycles.
Knowing the four pieces is not the same as designing them well, and this is where most graph agents are quietly won or lost. Each piece carries a design rule worth stating plainly, so the next four subsections take them one at a time: state as a contract, nodes as small units of work, edges as control policy, and cycles as loops that must be bounded.
12.2.1 State is the contract
It is tempting to treat state as a junk drawer, a bag of variables that nodes reach into as needed. In a real agent, state is something far more important: it is the contract between every node in the system. Each node reads the current state, does one piece of work, and returns an update. If the state is clear, the graph is clear. If the state is a muddle of raw messages and half-named scratch values, every node becomes a guessing game, and debugging turns into archaeology.
The discipline that keeps state legible is to separate the kinds of information the agent is carrying rather than piling them together. The conversation belongs in one place, tool and retrieval output in another, the agent’s current interpretation in a third, its failures in a fourth, the human-approval status in a fifth, and the final user-visible answer in its own field. Keeping these apart is what makes the graph testable, debuggable, and safe to pause and resume, because any node, and any human reading a checkpoint, can see at a glance what is known and what is still open. Figure 12.2 shows the shape.
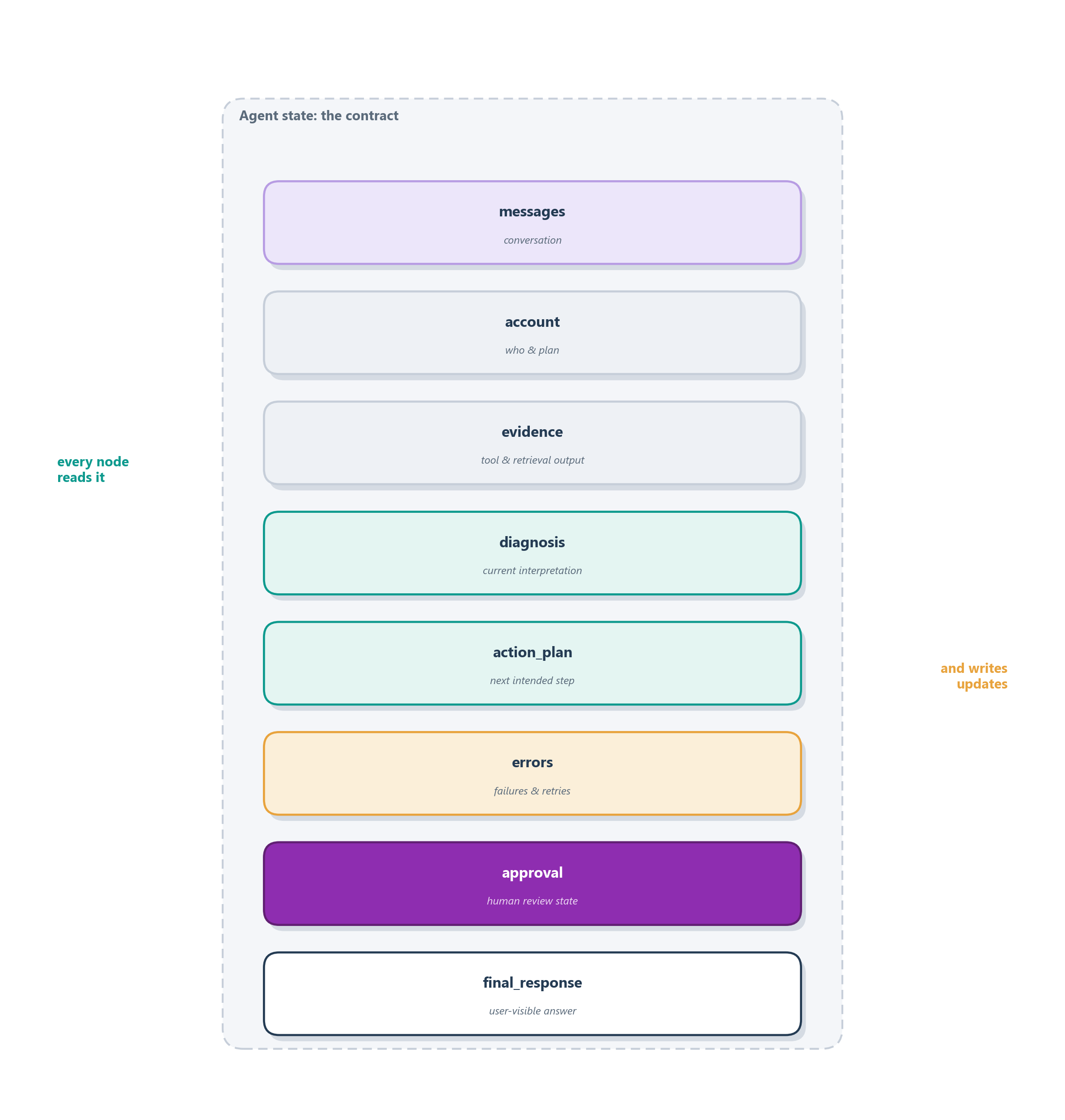
For Ledgerly, this separation is the difference between a graph you can reason about and one you cannot. A billing-support graph should not force every node to reread the whole conversation and re-infer what happened. The charge-lookup node writes structured charges; the policy-retrieval node writes the relevant refund_policy passage; the diagnosis node writes whether the issue looks like duplicate billing, proration, or something unresolved; the approval node writes whether a refund is pending, approved, edited, or rejected. Then the graph can route on state, not on vibes. Table 12.1 lays out a state schema for exactly that.
| State field | Purpose | Ledgerly example |
|---|---|---|
messages |
conversation context | the complaint and the agent’s replies |
account |
structured customer context | account ID, plan, billing period |
evidence |
tool and retrieval output | charges, plan history, refund-policy passage |
diagnosis |
current interpretation | duplicate charge, valid proration, or unresolved |
action_plan |
next intended step | validate policy, draft reply, request approval |
errors |
failures and retries | billing API timed out twice |
approval |
human-review state | refund pending, approved, edited, or rejected |
final_response |
user-visible output | the support reply that gets sent |
12.2.2 Nodes stay small and single-purpose
If state is the contract, nodes are the parties that honor it, and the rule for a good node is the plainest one in this chapter: a node should do one job. Classify the issue. Retrieve the billing record. Retrieve the policy. Validate the action. Draft the reply. Ask for approval. Execute the tool. Each is a single, nameable step that reads some of the state and writes a clean update to it.
The temptation, especially when a single prompt feels capable of doing everything, is to write one giant node that classifies, retrieves, reasons, validates, and acts all at once. Resist it. A giant node erases the entire benefit of graph orchestration, because there is nothing left to inspect, test, reroute, or checkpoint between its start and its end. When that node misbehaves, you are back to staring at a black box, which is exactly the situation the graph was supposed to rescue you from. Small nodes keep the seams visible, and visible seams are where debugging, evaluation, and human oversight get their grip.
12.2.3 Edges are where control policy lives
Nodes do work; edges decide what happens next. That sounds like a small distinction, but it is the heart of the graph. A fixed edge says the next step is always known. A conditional edge says the graph must inspect the state before it moves, which makes conditional edges the place where control policy becomes explicit rather than buried inside a prompt.
Read a few of Ledgerly’s edges as policy and the point lands. If the account is missing, route to ask for more information. If the policy check fails, route to an explanation instead of a refund. If the refund is above the approval threshold, route to human review. If the billing tool has failed twice, route to escalation. If the model has requested another tool, route back to the tool node. Each of these could be a line tangled inside a large prompt, invisible and untestable. Put it on an edge instead and it becomes something you can see, test, and review. That is the real value of graph orchestration: it does not take judgment away from the model, it puts a visible, governable structure around that judgment.
12.2.4 Cycles need limits
Cycles are what make a graph an agent, but a cycle without a brake is a liability. A loop that can return to an earlier node can also return forever: retrying a tool that will never succeed, re-reasoning over the same evidence, burning tokens and money without converging. The same feature that gives an agent its persistence gives it the capacity to spin.
So every cycle needs stopping rules, and they are worth deciding on purpose rather than discovering in production. A maximum iteration count caps how many times the loop may go around. A retry limit stops it from hammering a failing tool. Budget and time ceilings bound cost and latency. A progress check breaks the loop when the state stops changing in a meaningful way, and an escalation rule hands off after repeated failure instead of trying again. For Ledgerly, the concrete version is simple: if a billing lookup fails twice, do not keep retrying; route to ask_user or escalate. Bounded cycles are what let you trust an agent to loop without fearing it will loop away your afternoon and your API bill.
With the four pieces designed rather than merely named, the foundation is solid. And the first thing that solid foundation makes almost free is something our hand-rolled loop could never do easily: remember where it was.
12.3 Persistence & checkpoints
Because the entire state of a LangGraph agent lives in that one shared object, something powerful becomes almost trivial: you can save it. Attach a checkpointer when you build the graph, and LangGraph automatically writes a snapshot of the state after every step [1]. Think of the save points in a video game. At each checkpoint the game records exactly where you are and what you have; if the power cuts out, you reload the last save and continue as if nothing happened, rather than starting the whole game over. A checkpointer does this for your agent, and it quietly solves three problems at once.
The first is durability. A long-running agent that crashes halfway, a network blip or a server restart, does not have to redo everything. Its state was checkpointed, so it resumes from the last save point, mid-task, with its work intact. The second is memory across sessions, which ties directly back to Chapter 11. Checkpoints are grouped by a thread, an identifier for a single conversation. Give a returning user the same thread, and the agent reloads their entire prior state and picks up exactly where you left off; this is how the durable-memory idea of the last chapter becomes concrete plumbing rather than something you hand-build. The third, and most striking, is time travel: because every past checkpoint is saved, you can rewind to an earlier one to inspect what the agent knew at that moment, or even resume from the past along a different path, an extraordinary gift when you are debugging why an agent went wrong three steps ago.
Persistence is what separates a toy agent from a production one. A demo that runs start-to-finish in a single process can get away with holding state in memory and losing it at the end. A real system must survive restarts, span multiple user sessions, and let you inspect what happened after the fact, and all three fall out of checkpointing state you were already keeping. Design for durable state early; retrofitting it later is painful.
12.3.1 Checkpoints are not long-term memory
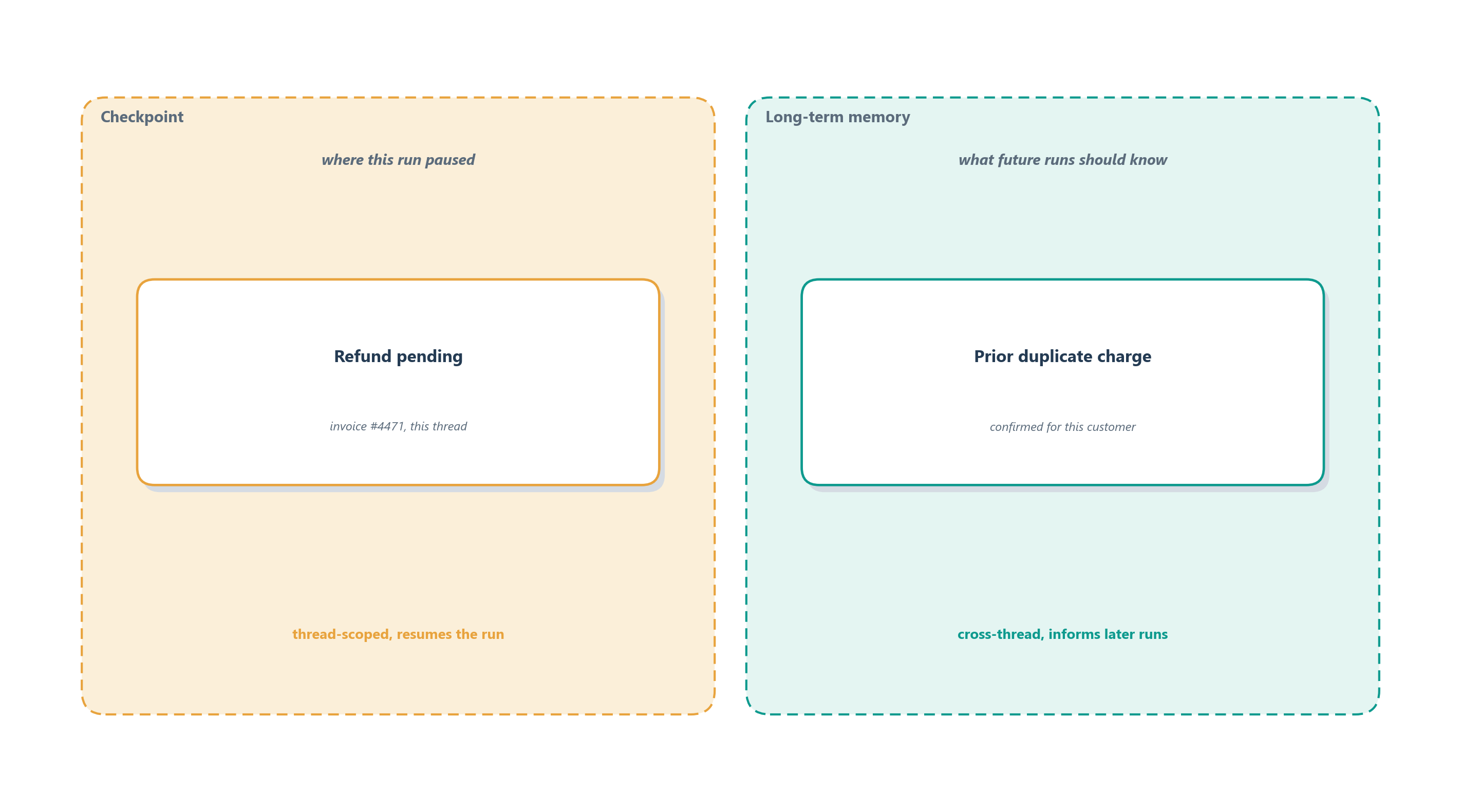
Because both a checkpoint and a memory “remember” something, it is easy to blur them, and the blur causes real bugs. They answer two different questions. A checkpoint answers where was this run when it paused? It is a thread-scoped snapshot of the graph’s execution state, the machinery that lets a single conversation resume mid-task. Long-term memory answers a different question: what should future runs know? It is durable, application-defined knowledge that outlives any one thread. LangGraph draws exactly this line, separating checkpointers that persist thread-scoped state snapshots from stores that persist knowledge across threads [2].
Ledgerly needs both, and needs them kept apart. A pending refund approval on invoice #4471 belongs in checkpointed graph state: it is about this run, and it exists so the conversation can pause for a human and resume. The fact that this customer had a confirmed duplicate-charge problem last quarter belongs in long-term memory: it is a durable pattern that should inform future tickets, on new threads the current run knows nothing about. Store the pending approval in memory and you leak run mechanics into permanent knowledge; store the durable pattern only in a checkpoint and it vanishes the moment the thread ends. Figure 12.3 keeps the two straight.
There is one more thing checkpoints unlock, and it is important enough to deserve its own section. If the agent can pause and its state is safely saved, then a human can step in during a run, inspecting what the agent is about to do, approving it, editing it, or stopping it, and the agent can resume from exactly that spot. That capability, human-in-the-loop control, is where we turn next.
12.4 Human-in-the-loop
We have argued more than once, first in Section 5.6, again when weighing agent autonomy in Chapter 8, that some actions are too consequential to let an agent take unsupervised. Sending money, deleting records, emailing a customer: for these you want a human to glance at the plan and say “yes, go” before anything irreversible happens. The trouble, with a plain while loop, is that there is no natural place to stop. Checkpointing changes that completely. Because the agent’s state is saved at every step and can be reloaded at will, LangGraph can interrupt a run at a chosen point, hand control to a person, and later resume from the exact same spot as if the pause had never happened [1].
The pattern is easiest to feel through an example. Imagine an agent that drafts and sends refunds. You place an interrupt right before the “issue refund” node, so the graph runs up to that point, looking up the order, deciding an amount, preparing the action, and then halts, its state frozen at the checkpoint, surfacing to a human: “About to refund $80 to order #1234. Approve?” A person reviews it and responds. If they approve, the graph resumes and the refund node fires; if they reject or edit the amount, that decision is written into the state and the agent continues accordingly. Figure 12.4 shows the pause-and-resume.
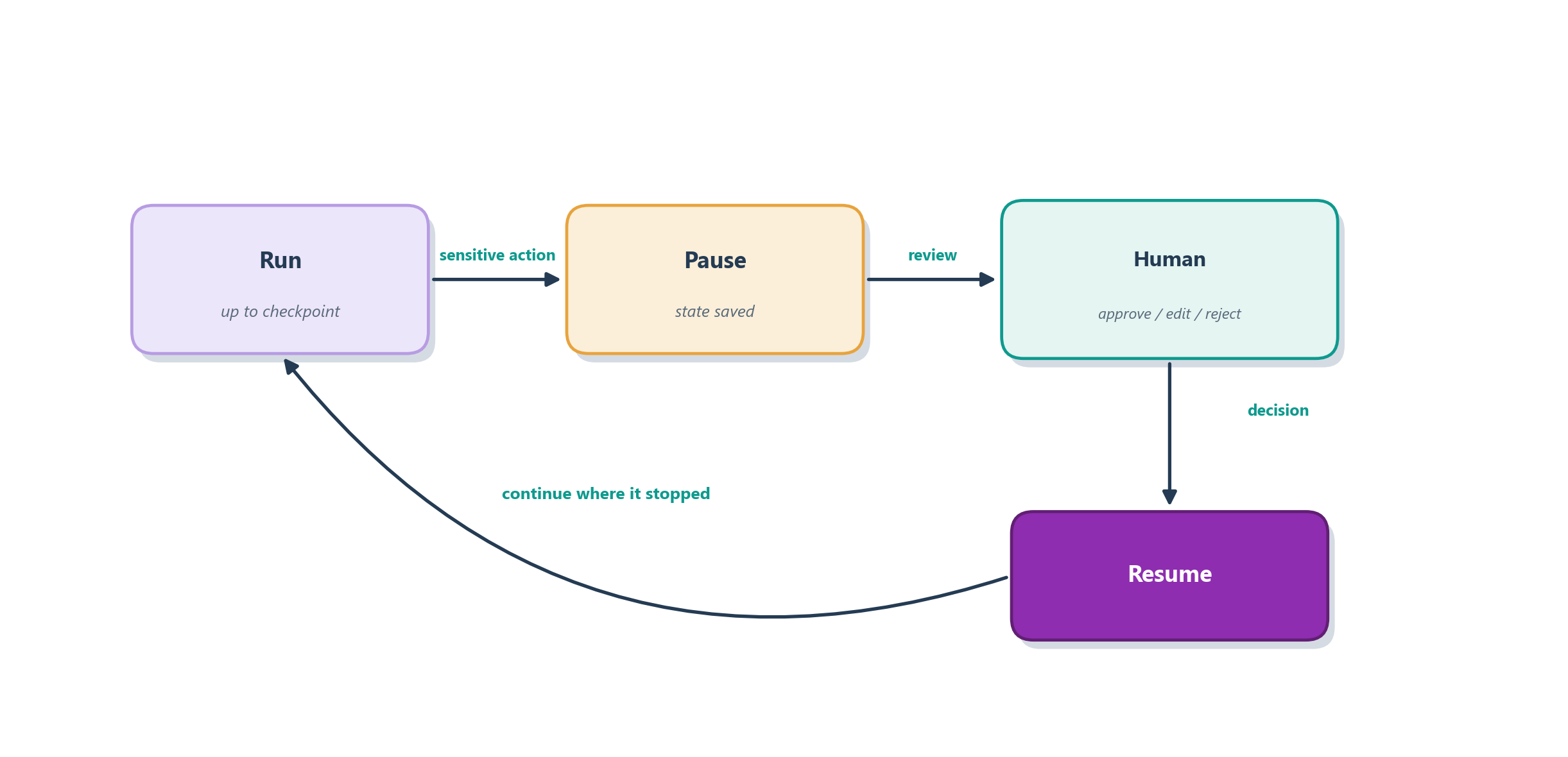
This is a genuinely different safety posture from “hope the agent behaves.” Instead of trusting an autonomous system with an irreversible action, you insert a deliberate gate at exactly the risky step, and the human’s judgment becomes part of the control flow rather than an afterthought bolted on outside it. It is the ground-and-verify instinct from Chapter 5 and the guardrails caution from Chapter 8, now realized as a concrete mechanism you get almost for free once state is durable. We will treat guardrails and oversight in full in Chapter 17; for now the point is that the graph model makes human oversight a first-class feature.
12.4.1 Interrupt before side effects
Where you place the interrupt matters as much as having one, and the rule is short: put the human review before the side effect, never after it. A review that fires after the refund has already been issued is an audit trail, not a control. The money has moved; the email has gone; the record is already deleted. All the human can do at that point is discover the mistake, not prevent it.
So the interrupt belongs immediately upstream of any node that touches the world irreversibly: sending an email, issuing a refund, changing an account plan, deleting data, escalating to an outside party, modifying a record, or creating a commitment that cannot be quietly undone. For Ledgerly the placement is unambiguous: interrupt before issue_refund, so the graph runs right up to the edge of paying out and then pauses. Put the same gate after the refund and you have built an expensive way to apologize.
12.4.2 Four decisions: approve, edit, reject, respond
An interrupt is not a vague “someone should look at this later.” It is a controlled pause that waits for a specific decision, and it helps to name the decisions on offer. LangChain’s human-in-the-loop middleware settles on four [3]. Approve lets the action run exactly as the model proposed it. Edit changes the arguments first, so a reviewer can trim an $80 refund to $40 before it executes. Reject blocks the action and hands feedback back to the agent, which then has to find another path. Respond covers the case where the agent paused to ask rather than to act, letting a human supply the missing answer so the run can continue.
The practical discipline is to have each sensitive tool declare which of these decisions it allows. For Ledgerly, lookup_charge and draft_refund_response are read-only and can run automatically with no interrupt at all. issue_refund must interrupt for approval once the amount crosses a threshold. send_customer_email may require approval depending on policy. And delete_customer_data is either fully human-gated or simply not exposed to the agent. Matching the decision type to the risk of the tool is how oversight stays proportionate: automatic where it is safe, gated where it is not.
We have covered a lot of machinery, state, nodes, edges, cycles, checkpoints, and interrupts, so let’s assemble it all into one small, complete agent and watch the concepts work together.
12.5 A worked example: the ReAct loop as a graph
The best way to see the pieces lock together is to build the agent we have been describing since Chapter 7, the reason–act loop, as an actual LangGraph. What was an abstract diagram in Section 7.5 becomes a runnable program here, and the mapping is almost one-to-one, which is the whole point of the graph model. We need just three ingredients: a state, two nodes, and one conditional edge.
The state is the shared scoreboard, and for a tool-using chat agent it is delightfully small, essentially the running list of messages. New messages are appended rather than overwritten, which LangGraph expresses with a small annotation on the state field. The two nodes are the two things the agent alternates between: a call_model node that sends the current messages to the LLM and appends its reply, and a run_tools node that executes any tool the model asked for and appends the result as an observation. The one conditional edge is the agent’s entire control logic: after the model speaks, look at its last message. If it requested a tool, route to run_tools; if not, the agent is done, so route to END. In the listing below, llm_with_tools and execute_last_tool_call() are simplified stand-ins for the model call and tool execution we built in earlier chapters, kept short here so the graph structure stays in focus rather than copied verbatim as real API calls.
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
def call_model(state): # node: the model thinks/acts
return {"messages": [llm_with_tools.invoke(state["messages"])]}
def run_tools(state): # node: execute the requested tool (pseudocode helper)
return {"messages": [execute_last_tool_call(state["messages"])]}
def should_continue(state): # conditional edge: loop or stop?
return "run_tools" if state["messages"][-1].tool_calls else END
graph = StateGraph(AgentState)
graph.add_node("call_model", call_model)
graph.add_node("run_tools", run_tools)
graph.add_edge(START, "call_model")
graph.add_conditional_edges("call_model", should_continue)
graph.add_edge("run_tools", "call_model") # the cycle
agent = graph.compile(checkpointer=MemorySaver())Read the wiring at the bottom and the earlier sections come alive. add_edge(START, "call_model") says every run begins by thinking. add_conditional_edges("call_model", should_continue) is the branch, act or finish. And add_edge("run_tools", "call_model") is the cycle, the loop back from acting to thinking that makes this an agent rather than a pipeline; it is the same arrow we drew in Figure 12.1. Compiling with a MemorySaver checkpointer means the whole thing is persistent for free: run it with a thread id and the conversation survives across calls, exactly the memory-across-sessions we described. To add the human approval from the last section, you would drop an interrupt before a sensitive tool, no restructuring required, because the graph already knows how to pause and resume.
Step back and notice what the framework did for us. We described the agent as a picture, nodes, edges, a loop, and that picture is the program, with durability and human oversight available as switches rather than rewrites. That is the case for a framework like LangGraph. The case for restraint is the one Anthropic pressed in Chapter 10: frameworks add layers of abstraction that can hide what the model actually sees, and they make it tempting to reach for machinery a simpler design would not need. The honest guidance is to understand the plain while loop underneath first, which you now do, and adopt a framework when its structure, persistence, and oversight genuinely earn their keep. Used with that judgment, the graph model is a powerful way to give a single agent shape. Making it run is only half the job, though: before a graph like this is trusted with real customers, it has to be observable, testable, and safe to resume, and it has to be worth its abstraction in the first place. Those are the questions we take up next.
12.6 Designing graphs for production
A graph that runs on your laptop and a graph you would put in front of paying customers are not the same artifact. The gap between them is a handful of production concerns that the graph model happens to make unusually tractable: you can watch it, test it, resume it safely, and decide honestly whether it earns its keep. Each deserves a short, practical treatment.
12.6.1 Observability: the trace is the recorded run
If the graph is the program, then a trace is the recorded execution of that program. This turns out to be the single most useful thing you can have when an agent misbehaves, because agent behavior is nondeterministic and a failure may never reproduce on demand. Observability lets you open a specific bad run and watch it unfold step by step, turning an opaque answer into an inspectable workflow: how the prompt became a plan, which tools were invoked, what intermediate results came back, and how the final response was composed.
The graph gives you natural seams to instrument. Each node should be traceable, each edge decision logged, each tool call recorded with its inputs, outputs, latency, and errors, and each interrupt stamped with the proposed action and the human’s decision. Conveniently, graph structure and trace structure line up almost one to one: a node maps to a span, a model call to a model span, a tool call to a tool span, and a whole run to a trace. The ecosystem is standardizing exactly this shape through OpenTelemetry’s GenAI semantic conventions, so you can lean on a common format rather than inventing a private one [4]. For Ledgerly, this is what makes a wrong refund debuggable after the fact: the team can open the run and see which node classified the issue, which edge routed the flow, which documents were retrieved, whether the payout paused for approval, and what the state held at the checkpoint just before the decision. We give observability its own full chapter in Chapter 16; here the point is simply that the graph model makes it natural.
12.6.2 Test the graph, not just the nodes
It is tempting to test a graph the way you test ordinary code, one function at a time, and node-level tests are indeed worth writing. But they miss the failures that only appear at the level of the whole graph, which is where the interesting bugs live. The questions worth testing are about behavior in motion: does the graph reliably terminate, or can it spin? Does the right edge fire for each shape of state? Does a failed tool route to a retry or an escalation rather than a dead end? Does a high-risk action actually trigger the interrupt? Does a resumed run pick up at the correct node? Does a human edit really change the action before it executes, and does the state stay valid after every node writes to it? None of these can be answered by inspecting a single node in isolation, because each is a property of how the pieces move together. Testing the graph means asserting on those properties, not just on individual outputs.
12.6.3 Idempotency for resumed actions
The most subtle of these behaviors deserves its own note, because it is easy to miss until it costs a customer money. When a graph resumes, after a crash or after a human approval, it must not accidentally repeat a side effect it already performed. Picture a refund that succeeded, then a server restart, then a resume from a checkpoint taken just before the payout: without a guard, the graph happily issues the refund a second time. The fix is idempotency. Give each side-effecting action a stable key, an action ID carried in the state, so a resumed run can recognize “this already happened” and skip it rather than redo it. For Ledgerly, issue_refund should carry such a key and check it, so that resuming from a stale checkpoint reconciles to the refund that already fired instead of paying the customer twice. This is a design recommendation rather than a framework feature: the graph makes resume easy, and idempotency is what makes resume safe.
12.6.4 When LangGraph is overkill
All of this machinery is worth something only when the problem calls for it, and the honest answer is that plenty of problems do not. Reach for LangGraph when the shape of the work genuinely needs it: when there is real branching, when there are cycles, when a human must approve an action, when state has to survive across sessions, when there are retries and failure paths to route, when you need to pause and resume, or when you want time-travel debugging over an explicit control flow. Those are the conditions its structure, persistence, and oversight were built to serve.
Skip it, just as deliberately, when none of that is in play. If a single LLM call answers the request, make the call. If a fixed, linear workflow does the job, write the workflow. When there is no branching, no persistence, and no oversight to manage, a graph framework adds abstraction that hides more than it reveals, which is the opposite of what this chapter has been praising it for. The rule that has run through the whole book holds here too: reach for the simplest thing that works, and let the problem, not the framework’s ambition, decide when to climb. Ledgerly’s refund flow clears that bar on nearly every count, which makes it the ideal place to watch the entire chapter operate at once.
12.7 Case study: the Ledgerly support agent
Where we left off, Section 11.9 gave Ledgerly memory but left its agentic lane as a loop improvised turn by turn. This chapter’s graph model gives that loop a durable skeleton. The complex lane from Section 9.10 is precisely the reason–act loop we just built in Section 12.5: a call_model node that decides, a run_tools node that runs the billing tools from Section 10.9, and the cycle between them. Ledgerly’s whole agentic lane is that graph.
Two of this chapter’s features matter most for a system that touches money. Checkpointing makes the conversation durable and gives it memory across sessions for free (Section 12.3), so a customer who replies a day later resumes exactly where they left off instead of starting over. And human-in-the-loop is the safeguard the refund example in Section 12.4 was written for: we drop an interrupt immediately before the issue_refund node, so the graph runs right up to the point of paying out and then pauses, surfacing “About to refund $80 to invoice #4471. Approve?” to a human. If they approve, the graph resumes and the refund fires; if not, it takes a different branch. Oversight becomes a switch in the graph rather than a rewrite.
Spelled out as an explicit graph, the refund flow is this whole chapter on a single page. Figure 12.5 draws it. Control enters at classify_request and load_account, fans out to three parallel fetches, fetch_charges, retrieve_policy, and fetch_plan_history, that join at diagnose_billing_issue, and arrives at validate_refund, the conditional edge that decides everything downstream. Every node reads and writes the state schema from Table 12.1, so no node has to re-infer context from raw messages; the diagnosis node writes a diagnosis, the validator reads it, and the approval node writes an approval.
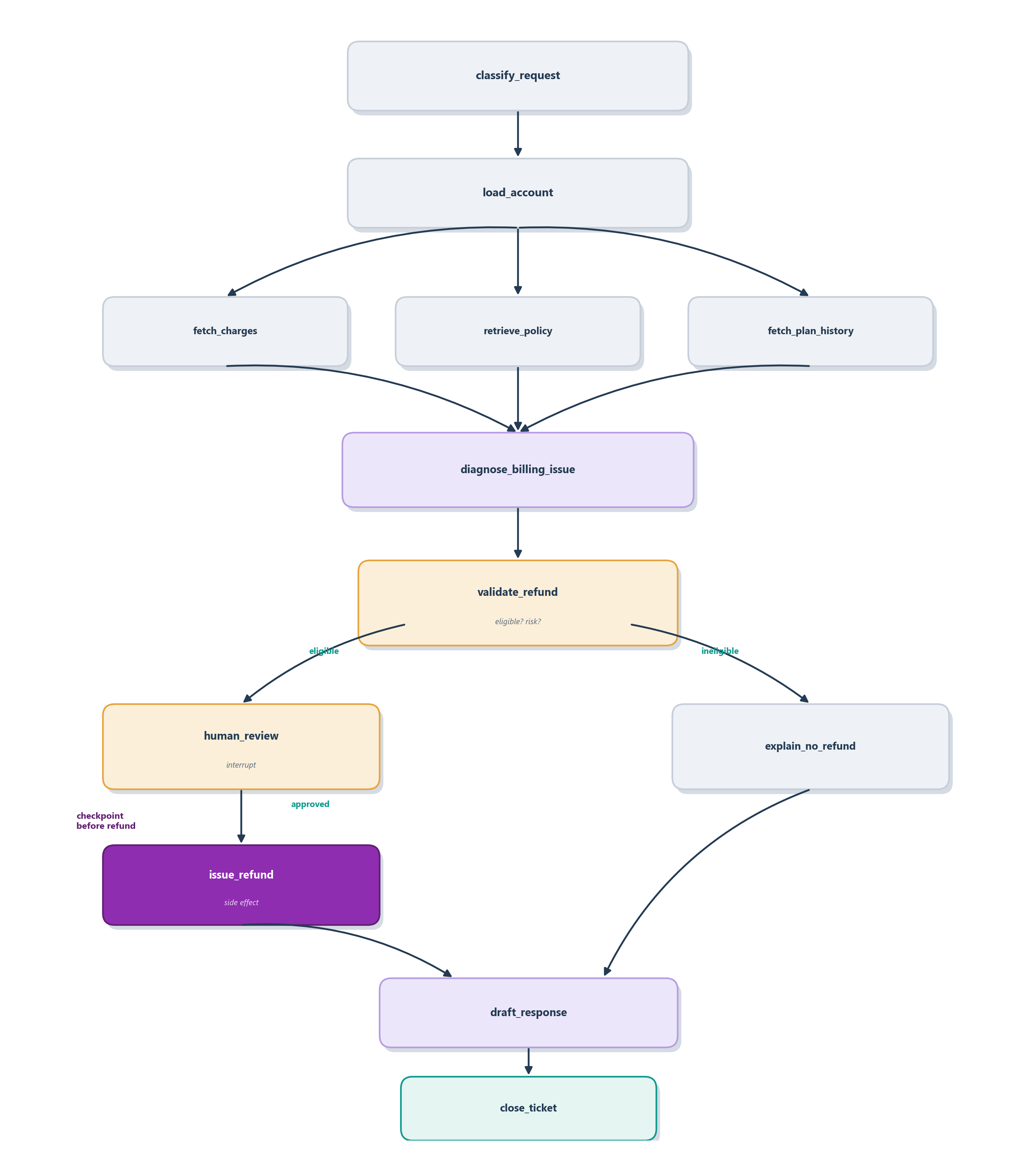
validate_refund edge routes the flow to human review, an explanation, or an escalation; a human interrupt fences the one irreversible node (issue_refund); and both branches converge on a drafted response. State is the contract every node signs.
The edges are where the policy lives. If the refund is eligible, validate_refund routes to human_review, the interrupt placed before the payout; if it is ineligible, it routes to explain_no_refund; if the records conflict, it escalates. Only a human approval passes control on to issue_refund, the single side-effecting node, which carries an idempotency key so a resumed run can never pay twice. Both branches then converge on draft_response and close_ticket. Meanwhile the approval field lives in checkpointed graph state, because it is about this run, while a durable pattern such as a customer’s history of duplicate charges belongs in long-term memory that informs future tickets, exactly the split we drew in Section 12.3.1.
This is the “expensive freedom” from Section 1.8 spent carefully: the agent plans and acts on its own, but the single irreversible action is fenced behind a checkpoint and a person. We build that fence out fully when we reach guardrails in Section 17.6.
The same agent can be expressed in a lighter-weight framework, too. The next chapter’s triage-and-handoff example (Section 13.5) is Ledgerly again: a triage agent that hands billing questions to a specialist, the very routing from Section 9.10 wearing the OpenAI Agents SDK’s clothes. Either way, before Ledgerly ships we have to answer a harder question than “does it run?”, namely “does it work?”. Section 15.8 builds the evaluation set that decides.
The improvised loop gets a durable skeleton:
- Router to three lanes; MCP tools; episodic/semantic/procedural memory; evaluator gate.
- New this chapter: the complex lane is now a durable graph (reason–act with checkpoints), and a human-approval step fences every refund before it pays out.
12.8 Summary
This chapter turned the flowcharts we had been drawing for explanation into flowcharts you can actually run, using LangGraph as a concrete instance of a durable idea.
- An agent is a graph of steps over shared state, a state machine. The diagrams we drew for explanation can be the program, instead of being hand-translated into tangled control flow.
- Four core concepts build any LangGraph agent: a shared state object, nodes that do work and update it, edges (fixed or conditional) that decide what runs next, and, crucially, cycles, the loops that make it an agent rather than a one-way pipeline [1].
- Design the four pieces, do not just name them. State is the contract between nodes, so separate its kinds of information; nodes stay small and single-purpose; edges are where control policy lives; and cycles need limits so a loop cannot run forever.
- Checkpointing state gives you three things at once: durability (resume after a crash), memory across sessions (via threads, realizing Chapter 11), and time travel for debugging.
- A checkpoint is not long-term memory. A checkpoint records where a run paused (thread-scoped); memory records what future runs should know (cross-thread). Serious systems need both, kept apart [2].
- Human-in-the-loop falls out of checkpoints. Interrupt before a side effect, never after, and offer a specific decision: approve, edit, reject, or respond [3].
- Design graphs for production. Make each node and edge traceable so a bad run is inspectable [4], test graph behavior rather than only node outputs, and give side-effecting actions an idempotency key so a resumed run never repeats them.
- A framework is a tool with costs. Understand the plain loop underneath first; adopt LangGraph when branching, cycles, persistence, and oversight genuinely earn their keep, and skip it when the simplest thing works.
We have now given a single agent real shape and staying power. But the same graph-and-state thinking scales to a different question: what if one agent is not enough, and a problem is best solved by several specialized agents cooperating? Before we get there, the next chapter looks at a second, lighter-weight way to build agents, the OpenAI Agents SDK, which trades some of LangGraph’s explicit control for a simpler surface: Chapter 13.
12.9 Exercises
- Map the board game. In your own words, match each board-game part (the board, the game piece, the scoreboard, and the rule “if your score is over 20, take the shortcut”) to a LangGraph concept.
- Design the state. For a support agent of your choosing, list the state fields you would define and what each one holds. Then explain what breaks if you instead let every node reread the raw message history and re-infer context for itself.
- Edges as policy. Take three control decisions an agent must make (for example “is the evidence sufficient?” or “does this need approval?”) and show how each becomes a conditional edge rather than a line buried inside a prompt.
- Bound the loop. Name three stopping rules you would put on a cycle, and give a concrete situation for each in which it prevents a runaway loop that burns tokens or money.
- Checkpoint or memory? For each item, say whether it belongs in a checkpoint or in long-term memory, and why: a pending refund approval, a customer’s language preference, the current step index, and a known duplicate-charge pattern for a returning customer.
- Place the interrupt. For an agent that can search the web, draft an email, and send it, where would you put a human-in-the-loop interrupt, why there rather than elsewhere, and which decision (approve, edit, reject, or respond) should each sensitive tool allow?
- Resume safely. Describe how a graph that resumes from a stale checkpoint could pay a refund twice, and explain how an idempotency key on the side-effecting node prevents it.
- Framework or not? Give one agent you would build with a bare
whileloop and one you would build with LangGraph, and justify each choice in terms of what the framework’s structure buys you.