14 Multi-Agent Systems
“If you want to go fast, go alone. If you want to go far, go together.”
— African proverb
After this chapter you will be able to design systems of collaborating agents and anticipate their failure modes.
14.1 When one agent isn’t enough
At the end of the last chapter we quietly crossed a line. To answer a single support request we used a triage agent and two specialists, three agents cooperating where before we had built only one. That was our first multi-agent system, and it raises the question this chapter is about: when is a team of agents actually better than a single capable one, and when is it just a more expensive way to get a worse answer?
The honest answer starts with an everyday observation about people. A great home cook can make you dinner alone, moving between chopping, searing, and plating as needed. A restaurant on a busy night cannot work that way, so a professional kitchen splits into a brigade: one cook works the grill, another the sauces, another plating, and an expediter at the pass calls out tickets and assembles the final dish. The brigade wins because the work genuinely decomposes into parts that can run in parallel and reward specialization. But push the same idea onto a task that does not decompose (ask ten people to jointly write a single sentence) and the coordination overhead swamps any benefit; the committee is slower and worse than one good writer. Multi-agent systems live on exactly that knife’s edge. Figure 14.1 draws the two shapes side by side.
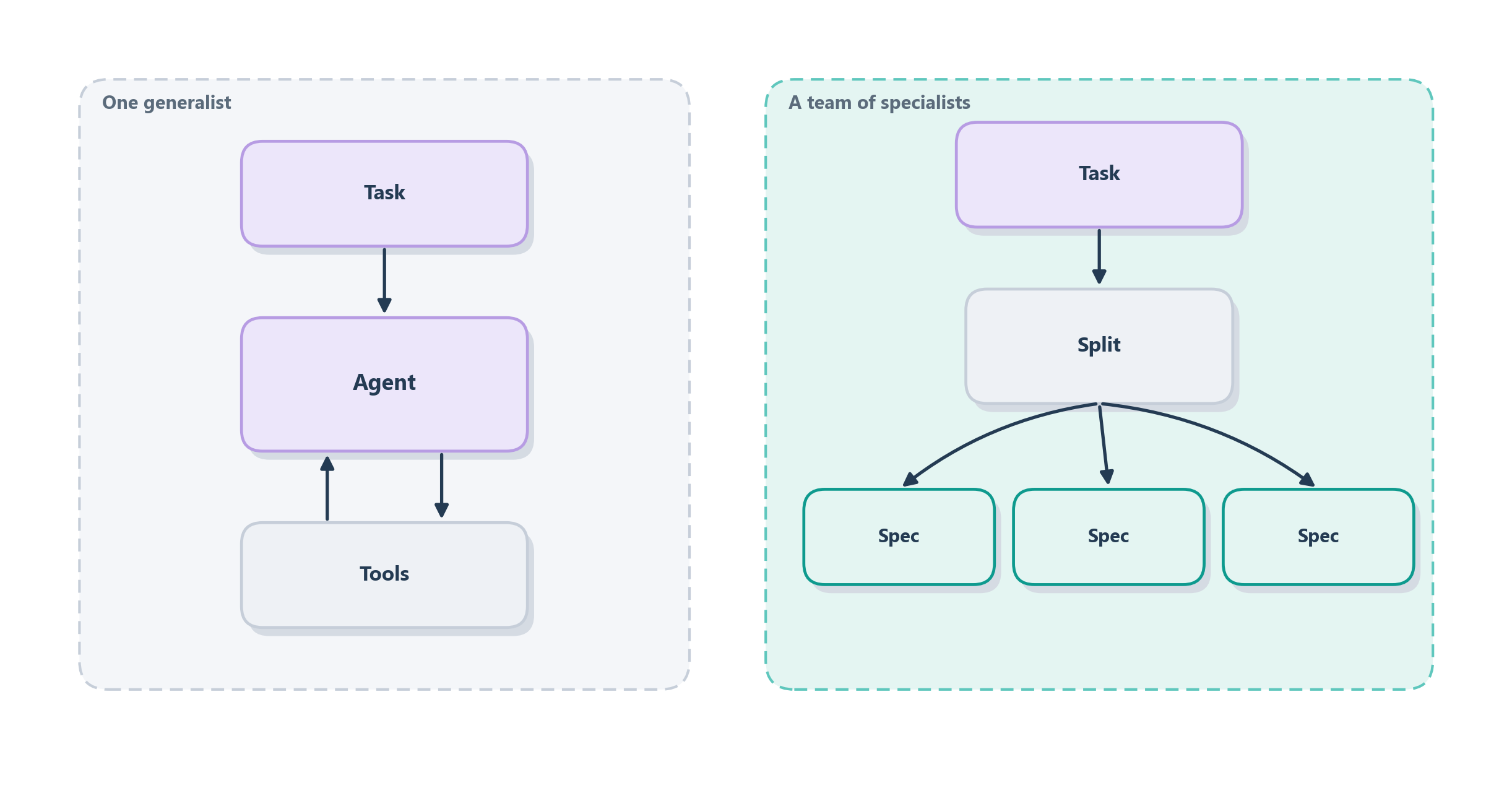
So the guiding principle mirrors the “simplest thing that works” rule from Chapter 8, raised one level: reach for multiple agents only when a single agent, even a well-equipped one, genuinely struggles: because the task splits into independent parts, because it benefits from distinct perspectives that a single context would blur together, or because different sub-jobs need genuinely different tools and instructions [1]. When those conditions hold, a team can outrun any soloist. When they do not, you have simply bought yourself more latency, more cost, and more ways to fail. The rest of the chapter is about building teams for the cases where they win.
How much can a team actually win by, and how much does it cost? A candid field report from Anthropic puts numbers on both. Building a research system in which a lead agent spawns several subagents that search in parallel, each with its own context window, they found the multi-agent version outperformed a strong single agent by 90.2 percent on their internal research evaluation [2]. The reason was almost mechanical: on a hard browsing benchmark, sheer token budget explained about 80 percent of the variance in performance, and a multi-agent system is a way to spend far more tokens on a problem by giving each agent a fresh context to fill. When a task is broad and its parts can be explored independently, more parallel effort simply buys better coverage.
That power is not free, and the same report is the first to say so. Agents already burn roughly four times the tokens of an ordinary chat, and a multi-agent system burns about fifteen times as many [2]. A team only makes economic sense when the task is valuable enough to justify that bill, which is why the pattern shines for open-ended research and rarely for routine questions. A prominent counter-camp argues the danger runs deeper than cost. Engineers at Cognition, reflecting on long-running coding agents, concluded that parallel subagents are still too fragile to trust in production, because the pieces cannot share enough context to stay consistent with one another [3]. Their advice is blunt: prefer a single-threaded agent that keeps one continuous thread of context, and add extra agents only when you truly must.
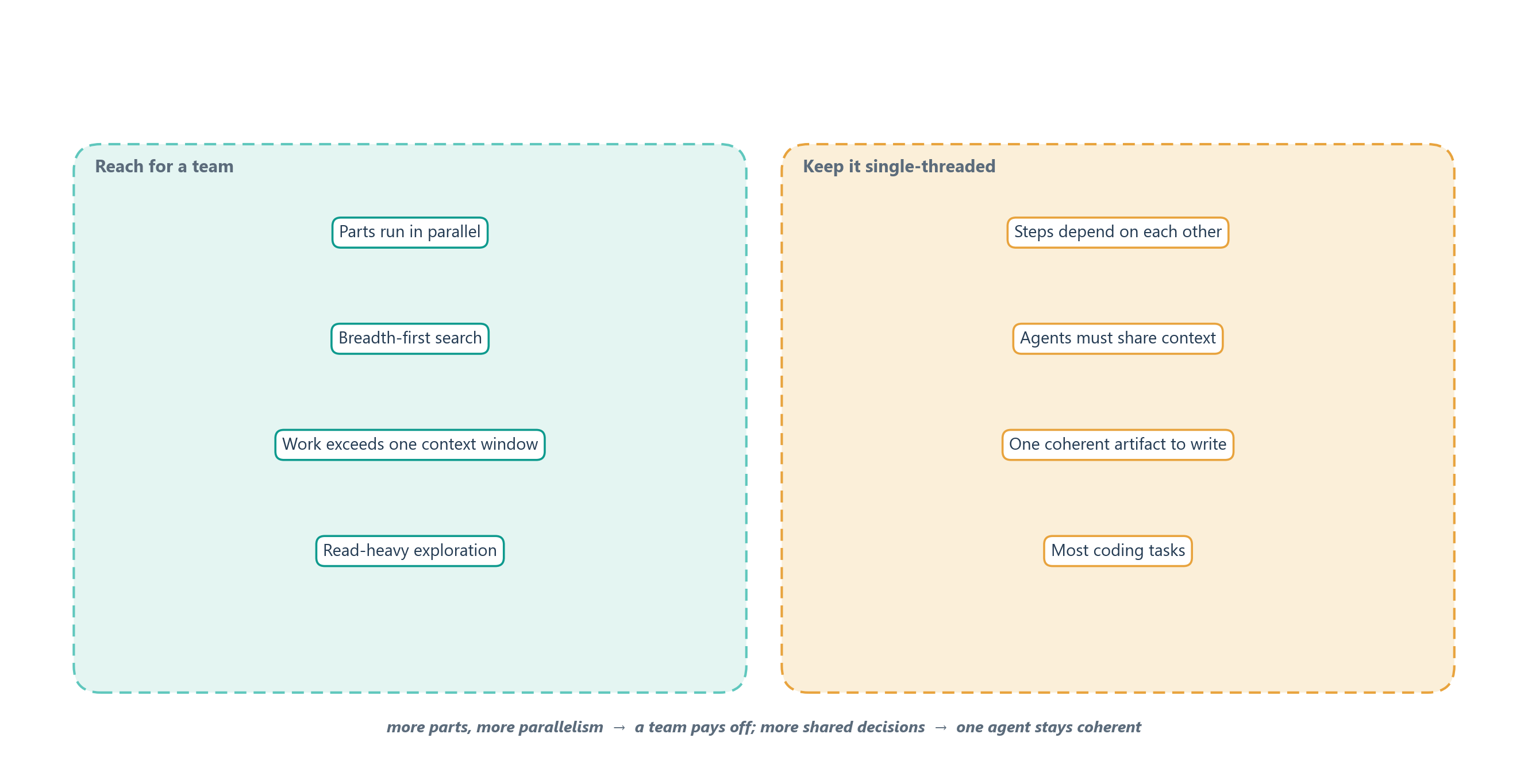
Read together, the two reports are less a contradiction than a map. A team pays off when the work breaks into parts that can run in parallel, when breadth matters more than tight coordination, and when the job is large enough to overflow a single context window. A single agent stays the wiser choice when the steps depend on one another, when the agents would need to share a great deal of context to agree, or when the output is one coherent artifact, such as a body of code, that many hands would render inconsistent. Figure 14.2 lays the two cases side by side; the rest of this chapter builds the machinery for the left column while respecting the warnings from the right.
14.2 How to arrange the team
Once you have decided a task deserves a team, the next decision is shape: how the agents are wired to one another. This is the multi-agent version of the org chart, and, as in a company, the shape you choose determines how work flows, who decides what, and where things jam up. Three shapes cover the great majority of real systems, and each has a familiar human counterpart.
The first is the supervisor–workers shape, the direct descendant of the orchestrator-workers pattern from Section 9.5. One agent acts as a manager: it holds the overall goal, breaks it into subtasks, hands each to a worker agent, and assembles their results. The workers do not talk to each other; they report up. This is the org chart of a project manager with a team, and it is the most common and most predictable shape because control stays in one place. The second is the handoff shape we just built in Section 13.5, a chain of custody rather than a hierarchy. Control passes from one agent to another like a customer walking from the front desk to the right department; whoever holds the conversation owns it until they pass it on. The third is the peer network, a set of agents that talk to one another as equals, debating, critiquing, or negotiating toward an answer with no single boss. This is a roundtable of experts, and it is the most powerful and the least predictable of the three. Figure 14.3 places the three side by side.
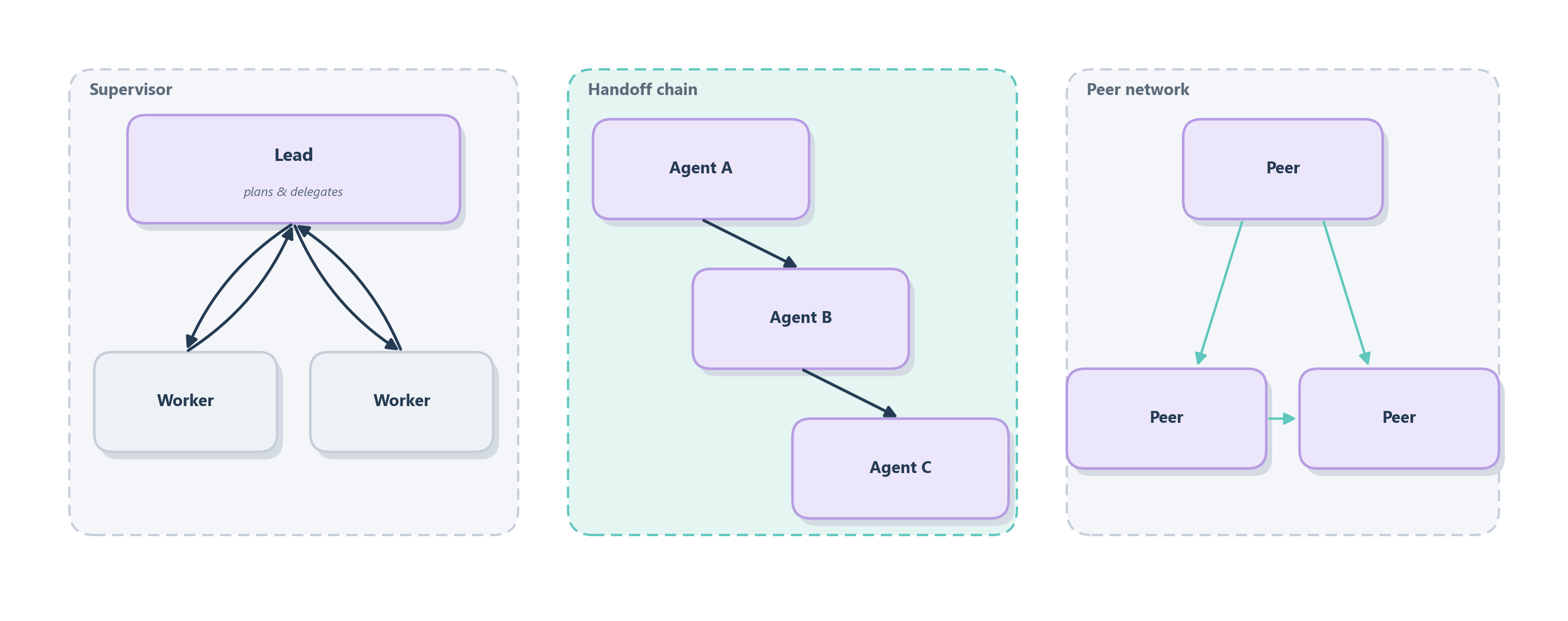
The right choice follows the same instinct we have applied all book long: prefer the most constrained shape that still solves the problem. A supervisor is the safest default because a single agent stays accountable for the outcome and the flow is easy to trace. Handoffs suit problems that move through clear stages, where each stage has a natural owner. A peer network earns its keep only when the value genuinely comes from interaction (agents catching each other’s mistakes or combining viewpoints) and you are willing to pay for the unpredictability that open conversation brings. Table 14.1 gathers those trade-offs in one view.
| Topology | Who controls the flow | Best when | Main risk |
|---|---|---|---|
| Supervisor–workers | One lead agent delegates and recombines | Work splits into independent subtasks with a clear owner of the result | Lead becomes a bottleneck; workers duplicate effort if briefed vaguely |
| Handoff chain | Control passes from one agent to the next | The task moves through ordered stages, each with a natural owner | Context is lost at each handoff; an earlier stage is hard to revisit |
| Peer network | Shared, with no single boss | The value comes from interaction: debate, critique, cross-checking | Least predictable; highest token cost; can loop without converging |
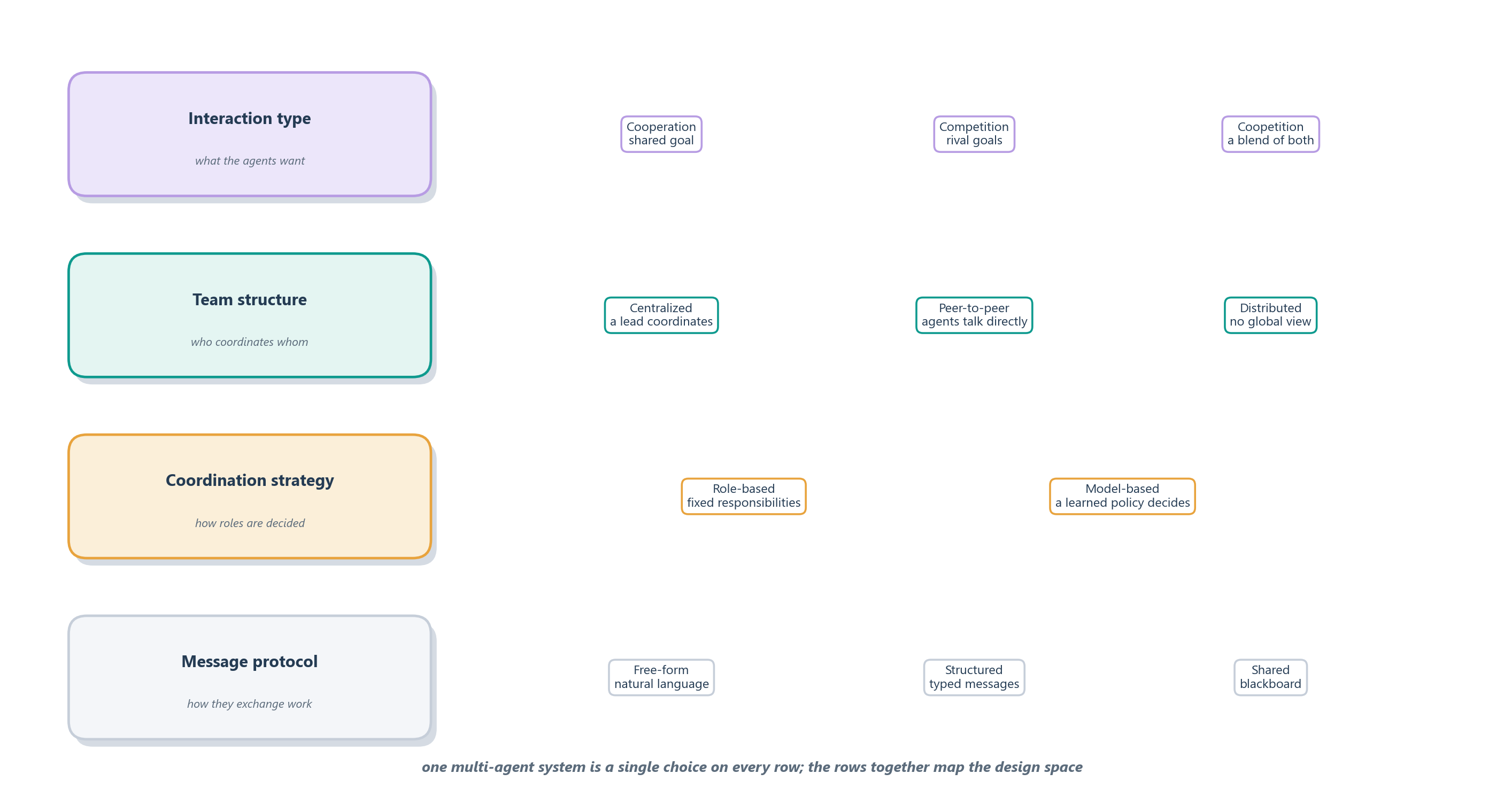
These three shapes are the ones you will reach for most, but they are points in a much larger space. A recent survey of multi-agent LLM systems maps that space along a handful of dials [4]: what the agents want (do they cooperate toward a shared goal, compete, or do a bit of both), how the team is structured (a central lead, direct peer-to-peer links, or a fully distributed group with no global view), how roles are decided (fixed in advance or chosen by a learned policy), and what protocol governs their messages. Figure 14.4 lays out those dials. Reading the design space this way is useful because it turns a vague question (“should this be multi-agent?”) into a set of concrete, separable choices, and it shows that the supervisor, handoff, and peer patterns are just three well-worn combinations among many.
Of the three, the peer network has the most research behind it, and its clearest form is multi-agent debate. Instead of trusting one model’s first answer, you run several copies of a model, let each propose a solution, then have them read one another’s reasoning and revise over a few rounds until they converge. Du and colleagues showed that this “society of minds” measurably improves mathematical and factual accuracy and reduces confident hallucinations, using nothing more than the same model reasoning against itself in parallel [5]. The gain comes from exactly the interaction a peer network is built for: a wrong answer rarely survives contact with two peers who reason differently. The cost is the one a peer network always carries, several models running for several rounds where a soloist would have answered once.
That evidence is real, but it comes with a caveat worth taking to heart: more agents and more rounds do not reliably mean better answers. Smit and colleagues benchmarked a range of debate and prompting strategies across accuracy, cost, and time, and found that multi-agent debate, in its current form, often fails to beat simpler and cheaper baselines such as self-consistency or ensembling, and that its results swing sharply with hyperparameters that are hard to tune [6]. The lesson is not that debate never helps, but that a bigger crowd is a hypothesis to test on your own task, never a guarantee to assume.
Whichever shape you pick, though, the agents now have to exchange information, and how they pass it turns out to matter as much as the org chart itself.
14.3 How the agents talk
An org chart only says who reports to whom; it does not say how information actually moves. In a multi-agent system that second question is where much of the difficulty hides, because agents communicate in natural language, and the same medium that makes them flexible also makes their messages ambiguous, lossy, and easy to misread. There are two broad ways to move information between agents, and they mirror how human teams coordinate.
The first is direct messaging: one agent passes a message straight to another, the way you send a colleague an email. This is simple and easy to trace (every exchange has a clear sender and receiver) and it is exactly what a handoff does under the hood. Its weakness is that information is private to the two parties; a third agent that could have used the same fact never sees it. The second way fixes that with a blackboard (sometimes called shared state or a shared scratchpad), a classic idea from early AI: instead of messaging each other, agents read from and write to a common workspace, like a team gathered around a shared whiteboard in a war room. Anyone can post a finding, and anyone can build on what others have posted. This is the multi-agent extension of the shared state we designed in Chapter 11, now written and read by several agents at once. Figure 14.5 contrasts the two.
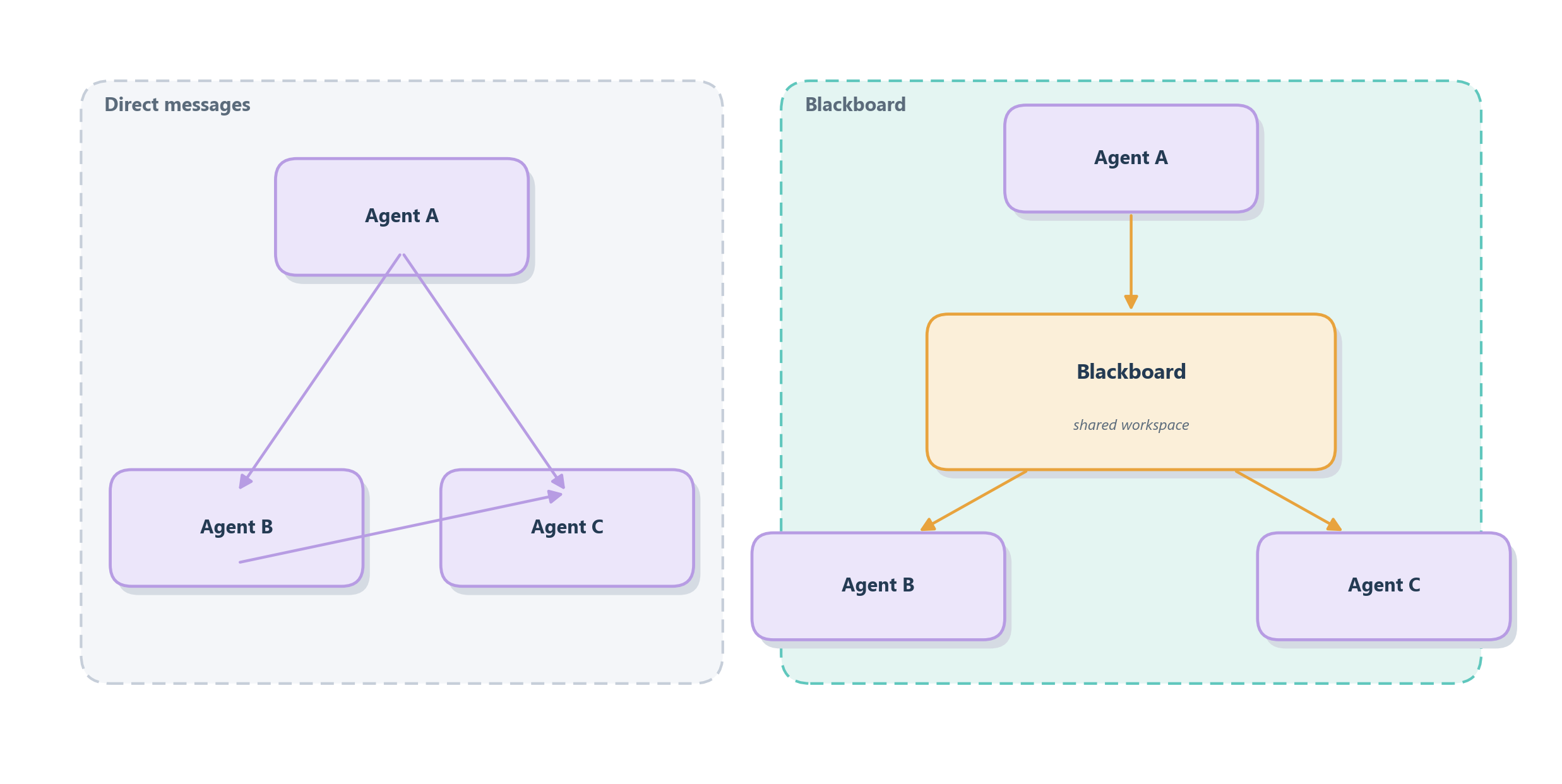
Because the medium is language, the thing that keeps either style from descending into noise is a protocol: an agreed structure for messages, just as engineers agree on the fields of an API request. When an agent’s output must be read by another agent rather than by a person, it pays to constrain that output: a fixed shape (“here is my finding, here is my confidence, here is what I still need”) so the receiver can parse it reliably instead of guessing. Some multi-agent frameworks formalize this with typed messages or even dedicated agent-to-agent protocols; the underlying idea is always the same discipline we met with tool schemas in Chapter 10: turn a free-form conversation into something structured enough to build on.
14.3.1 Conversation or structured workflow?
A protocol settles the shape of a single message, but a team also needs a style for the exchange as a whole, and here two philosophies have emerged, each carried by an influential framework. Figure 14.6 places them side by side.
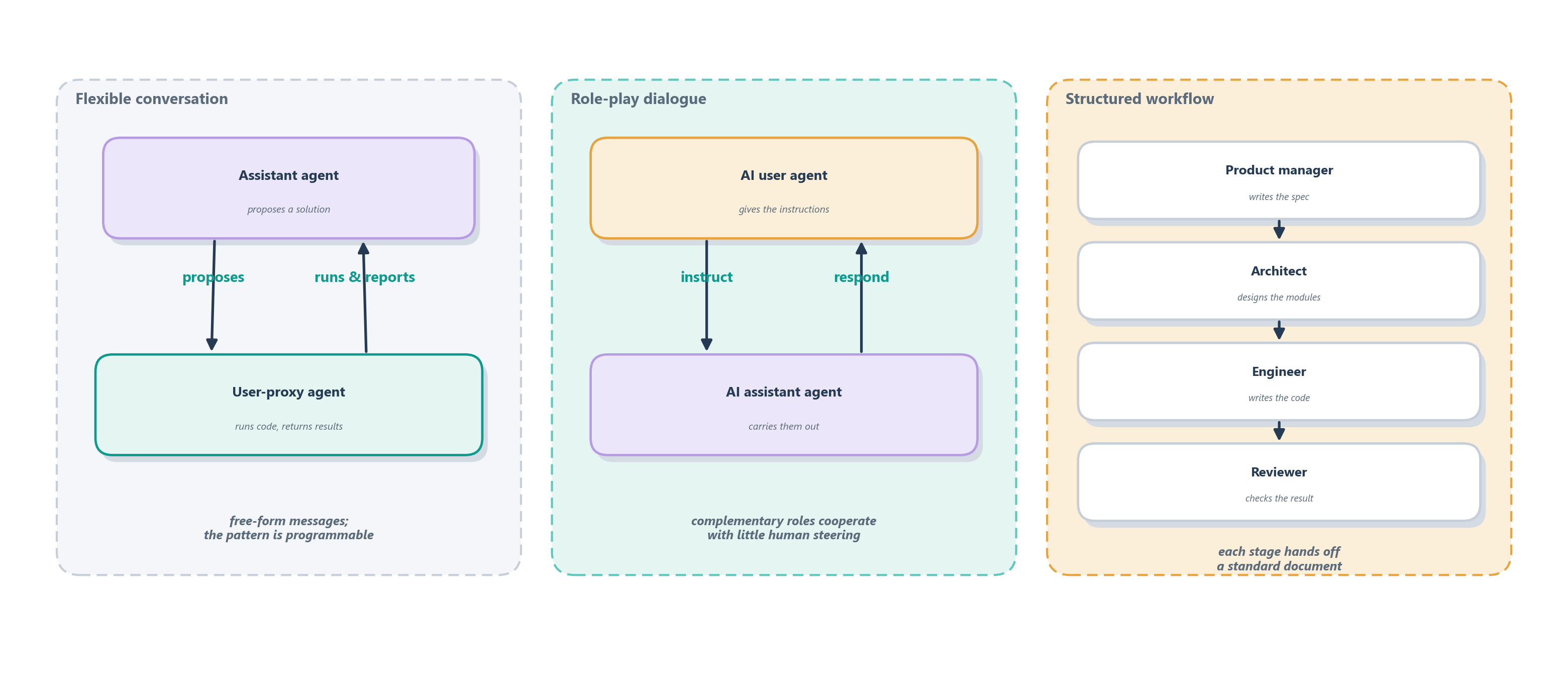
The first treats the interaction as a conversation. AutoGen builds multi-agent applications out of “conversable” agents that send messages back and forth to accomplish a task, freely mixing model calls, tool use, and human input, with the conversation pattern itself written in ordinary code [7]. A common arrangement pairs an assistant agent that proposes solutions with a user-proxy agent that runs the code and reports what happened, looping until the work is done. CAMEL pushes the conversational idea further into role-play: it gives two agents complementary roles (an AI user that issues instructions and an AI assistant that carries them out) and uses a technique its authors call inception prompting to keep them cooperating autonomously, with very little human steering [8]. The appeal of the conversational style is flexibility; its risk is the open-endedness we keep meeting, chatter that wanders or loops without converging.
The second philosophy treats the interaction as a structured workflow. MetaGPT argues that chat alone is too loose for serious engineering, and instead encodes human standard operating procedures into the agents’ prompts: roles such as product manager, architect, and engineer work an assembly line, each producing a standardized artifact (a spec, a design, a module of code) that the next role consumes [9]. Because every hand-off is a checkable document rather than an offhand remark, intermediate results can be verified and mistakes caught before they compound, which is exactly the cascading-hallucination failure that naively chaining language models tends to produce. The trade is rigidity for reliability: you give up some of the conversation’s adaptability in return for outputs that are far easier to trust.
Neither style is universally right. Conversation shines when the path to a solution is unknown and exploration pays for itself; a structured workflow shines when the process is well understood and correctness matters more than creativity. Most production systems borrow from both, wrapping a bounded conversation inside the stages of an otherwise structured pipeline.
14.3.2 Passing context, not just messages
A protocol makes each message well-formed, but it does not guarantee the receiver has enough context to act well, and that gap is where multi-agent systems most often break. The team at Cognition, after building long-running coding agents, distilled the problem into two principles worth memorizing. The first: share context, and share full agent traces, not just individual messages. An agent handed only a one-line summary of a subtask, rather than the history that produced it, will fill the gaps with its own assumptions [3]. Their example is vivid: split “build a Flappy Bird clone” into two subtasks and one subagent may return a Super Mario background while the other returns a bird that moves nothing like the game, each result locally reasonable and jointly useless.
The second principle explains why even sharing context is not always enough: actions carry implicit decisions, and conflicting decisions carry bad results. When two agents each make a defensible choice in isolation, an art style here, a data format there, their outputs can still clash because neither saw the other’s decision. This is the game of telephone that Anthropic’s team named from the other side of the debate: information degrades a little each time it is retold from one agent to the next [2]. Their remedy is a pattern worth stealing. Rather than pass a large result through the conversation, where every hop can distort it, have the subagent write its output to a shared store (a file, a database row, a blackboard entry) and pass only a lightweight reference. The receiver then reads the artifact straight from the source, so nothing is garbled in the retelling. It is the blackboard instinct again, aimed squarely at protecting fidelity across handoffs.
Get the wiring, the protocol, and the context-passing right and something remarkable becomes possible: behavior that no single agent was programmed to produce.
14.4 When the whole exceeds the parts
The most striking thing about a well-connected group is that it can produce behavior none of its members were individually designed for. A single ant follows simple local rules, yet a colony builds bridges and farms fungus; no ant holds the plan. This is emergence, global patterns that arise from local interactions, and multi-agent systems of language models turn out to be a vivid place to watch it happen.
The clearest demonstration is the Generative Agents study, in which researchers populated a small simulated town, “Smallville,” with twenty-five agents, each given a memory of its experiences, the ability to reflect on them, and the freedom to plan its own day [10]. Nobody scripted a plot. Yet when one agent was seeded with the intention to throw a Valentine’s Day party, something lifelike unfolded on its own: the agent invited a few others, those agents told their friends, the invitation spread through the town by word of mouth, some agents asked each other to go as dates, and, most tellingly, a group of them remembered the time and place and actually showed up at the right house at the right hour. The coordination, the information diffusion, and the budding relationships were never programmed; they emerged from many agents each following simple, memory- driven rules while talking to their neighbors. Figure 14.7 sketches that spread.
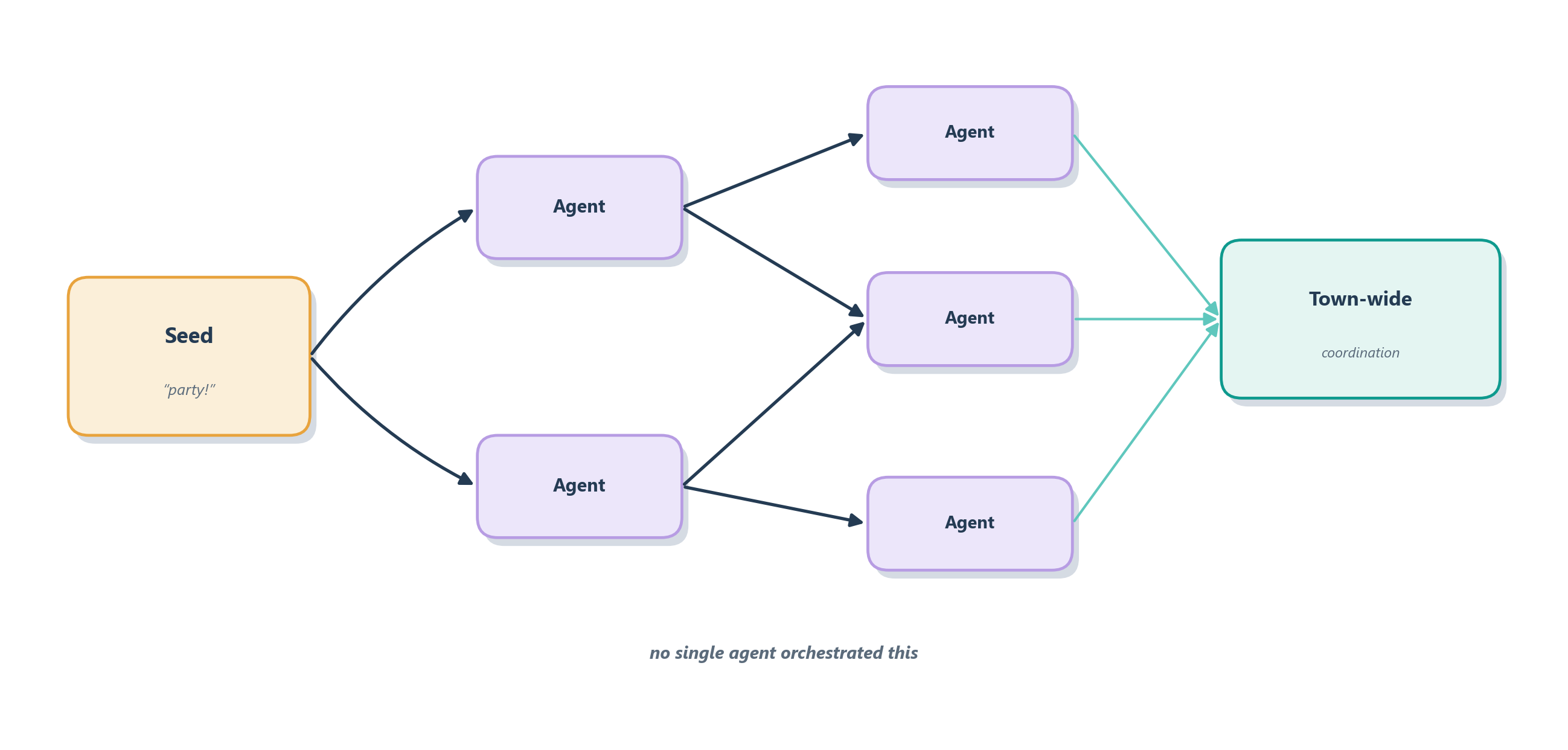
Emergence is a double-edged gift, and holding both edges is the mature way to think about multi-agent systems. On the bright edge, it is the source of their real magic: capabilities and solutions that a single, centrally planned agent would never reach, whether that is a richer simulation of a social world or a research team of agents that collectively covers ground no soloist could. On the dark edge, the same openness that lets good surprises appear lets bad ones appear too: behaviors you did not intend and cannot easily predict from any single agent’s instructions. An emergent party is charming; an emergent failure, where a stray message cascades into every agent chasing the wrong goal, is not. Which is exactly why we now have to look, clear-eyed, at the ways these systems go wrong.
14.5 The ways teams go wrong
Every strength of a multi-agent system has a matching weakness, and a designer who sees only the upside is setting a trap. The same properties that make teams powerful (many agents, much talking, open interaction) are exactly the properties that make them fail in ways a single agent never could. Three failure modes recur often enough to name and guard against.
The first is miscoordination: agents working at cross-purposes because their picture of the goal has drifted apart. It is the group project where two students write the same section and nobody writes the conclusion, each sure someone else had it. Because agents coordinate through fallible natural-language messages, small misunderstandings compound into duplicated work, gaps, or outright deadlock. The second is cost and latency blow-up. A single agent’s run costs one stream of model calls; a team multiplies that by the number of agents and again by every round of conversation between them. A peer network left to debate can burn tokens for many turns to reach an answer a lone agent would have produced in one: you have bought a committee, with a committee’s bills. The third, and most insidious, is error propagation, the compounding-error problem from Chapter 8 raised to the group level: one agent’s mistake becomes another agent’s trusted input, which becomes a third agent’s premise, until a single early slip has poisoned the whole system’s output. Figure 14.8 traces that cascade.
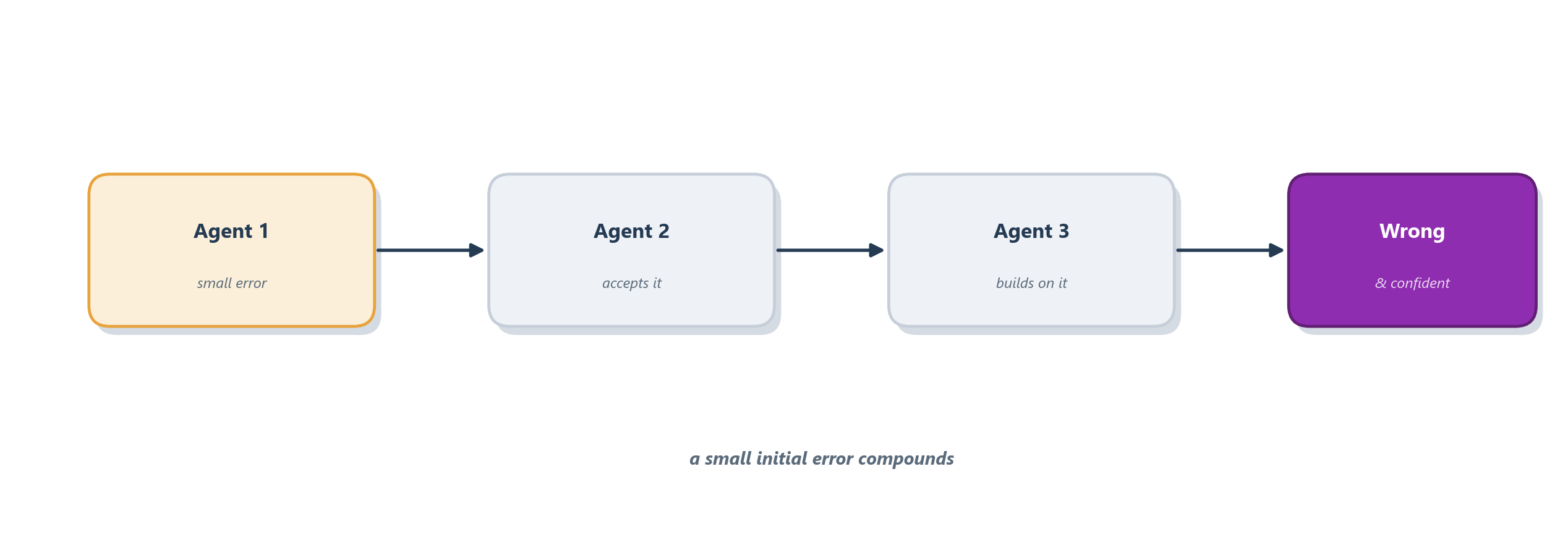
None of these are reasons never to build multi-agent systems; they are reasons to build them deliberately, and they explain why the field’s most experienced practitioners keep returning to the same counsel we have followed all book long: start with the simplest design that works and add agents only when a single one demonstrably cannot cope [11]. The practical defenses are the ones the rest of the book equips you with: keep a single agent accountable where you can (the supervisor shape), give agents structured protocols so messages drift less, cap the rounds of conversation to bound cost, and, above all, instrument the system so you can see these failures when they start, which is the subject of Part 4.
14.5.1 A taxonomy of team failures
Naming three failure modes is a useful start, but how common are they really, and are there more? A 2025 study set out to answer that empirically, collecting more than 1,600 execution traces from seven popular multi-agent frameworks and having expert annotators catalog everything that went wrong [12]. The result, the Multi-Agent System Failure Taxonomy, or MAST, is the closest thing the field has to a field guide of failure. It sorts fourteen distinct failure modes into three families, and those families map cleanly onto the design decisions of this chapter.
| Failure family | What goes wrong | Where it bites in this chapter |
|---|---|---|
| Specification and design | Vague roles, unclear objectives, or a topology that does not fit the task | Choosing the shape (Section 14.2) and briefing each agent |
| Inter-agent misalignment | Agents talk past one another: withheld context, conflicting assumptions, derailed conversations | How the agents talk (Section 14.3) and the telephone problem |
| Task verification | No one checks the work, or the check is too weak to catch the error | Guarding against error propagation, and ultimately evaluation |
Two lessons from that work belong right next to the taxonomy. The first is sobering: across those frameworks, the measured gains of going multi-agent over a single agent were often minimal, a reminder that a team is a cost to justify rather than a default to assume. The second puts a number on that cost. Recall that a multi-agent system can spend on the order of fifteen times the tokens of a single chat [2]; every extra agent and every extra round of debate is real money and real latency, so bounding the conversation is design, not housekeeping. The encouraging news is that most MAST failures yield to the disciplines this book keeps returning to: a clearly specified role for each agent, structured protocols that carry full context, a single accountable owner where possible, and an explicit step that verifies the work before it ships.
With those failure modes mapped and the defenses in hand, we can assemble a small, well-behaved team and watch the pieces work together.
14.6 A worked example: a supervisor and two workers
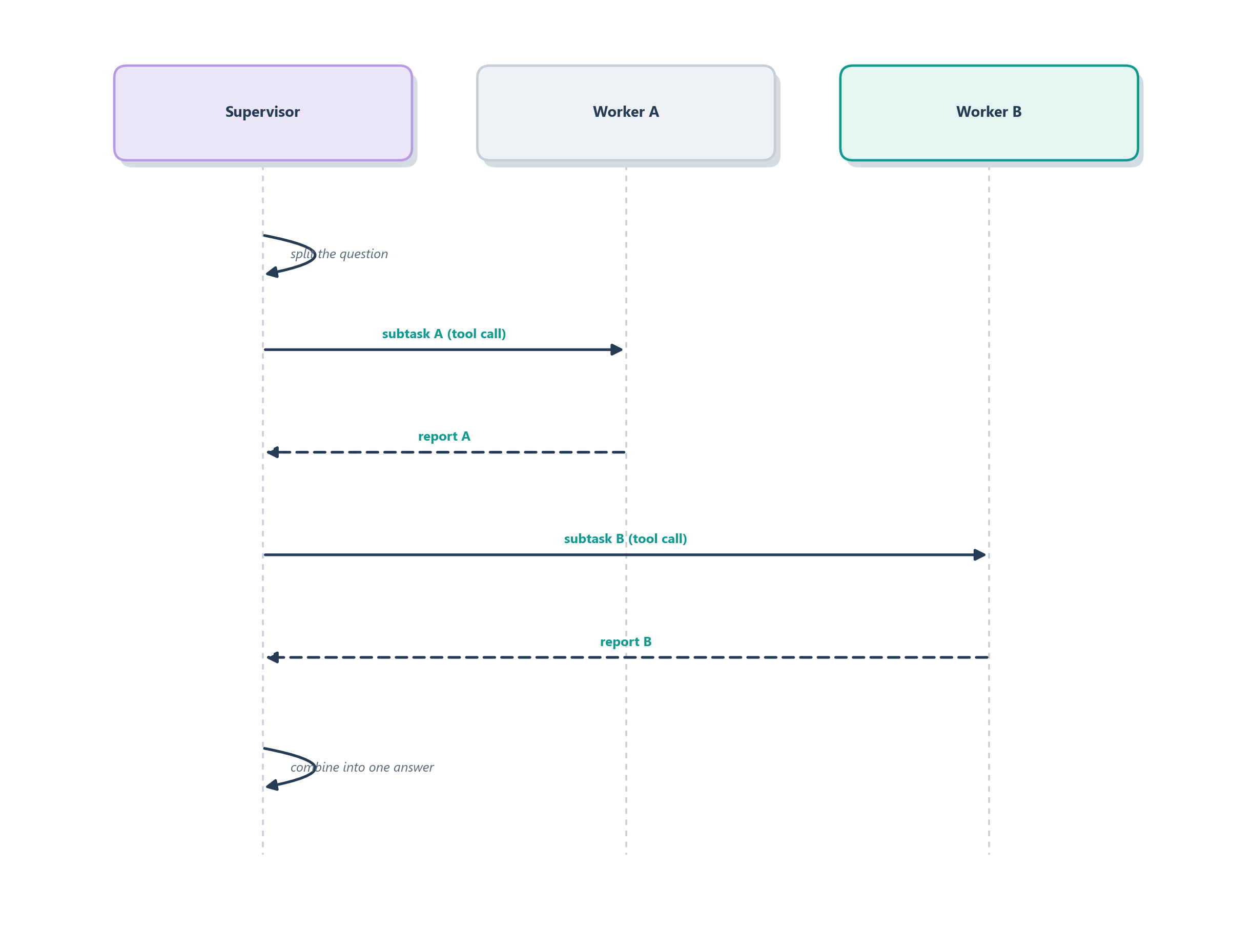
Let us make the safest, most common shape concrete by building a small research assistant as a supervisor with two workers. The job is to answer a question that has two independent halves: say, “How does our product’s pricing compare to competitors, and what are customers saying about it?” One half is a market-research task, the other a review-analysis task, and they do not depend on each other, which is exactly the decomposition that makes a team worthwhile. We give each half its own specialist and put a supervisor in charge of splitting the work and stitching the answers back together.
The cleanest way to keep the supervisor accountable, the lesson from Section 14.5, is to expose each worker to it as a tool rather than handing off control, so the supervisor always regains the floor after a worker reports. This is the orchestrator-workers pattern from Section 9.5 expressed with the SDK primitives from Chapter 13.
from agents import Agent, Runner
market = Agent(name="Market",
instructions="Research competitor pricing and summarize it concisely.")
reviews = Agent(name="Reviews",
instructions="Summarize what customers say, grouping praise and complaints.")
supervisor = Agent(
name="Supervisor",
instructions=(
"Break the question into parts, call the right worker for each, "
"then combine their findings into one answer."),
tools=[ # workers exposed as tools -> supervisor stays in control
market.as_tool(tool_name="research_pricing",
tool_description="Get competitor pricing."),
reviews.as_tool(tool_name="analyze_reviews",
tool_description="Summarize customer sentiment."),
],
)
result = Runner.run_sync(supervisor,
"How does our pricing compare, and what do customers say?")
print(result.final_output)Follow the run and every idea in the chapter appears at once. The supervisor reads the question, recognizes its two independent halves, and calls each worker, potentially in parallel, since neither depends on the other, echoing the parallelization pattern from earlier. Each worker does its narrow job and reports a structured summary back up; the supervisor, holding both results on its own scratchpad, composes the final answer. Figure 14.9 traces the flow. Because control returns to the supervisor after every worker call, one agent stays accountable for the outcome, coordination is easy to follow, and the blast radius of any single worker’s mistake is contained: the disciplined version of a team, rather than a free-for-all.
That small, well-behaved team is a fitting place to close Part 3. We have gone from a single augmented model all the way to a coordinated group of agents, always adding structure only when the problem earned it. But every system we have built so far, from the first tool call to this supervisor, shares an unanswered question: how do we actually know it works? We have been trusting that the agents do their jobs. Part 4 stops trusting and starts measuring, beginning with evaluation.
14.7 Summary
This chapter moved from single agents to teams of them, and the throughline was restraint: a team is a powerful tool that must earn its complexity.
- Use many agents only when one genuinely can’t cope, because the task decomposes into independent parts, benefits from distinct perspectives, or needs different tools per sub-job. When those conditions fail, a team just adds cost, latency, and failure modes [1].
- A team can win big and cost big. In one field report a multi-agent researcher beat a strong soloist by about 90 percent, largely by spending far more tokens, while using roughly fifteen times the tokens of a chat. Reach for a team where breadth and parallelism justify that bill; keep a single-threaded agent where the steps depend on each other [2], [3].
- Three topologies cover most systems: a supervisor delegating to workers (predictable, accountable), a handoff chain that passes control along, and a peer network of equals (powerful but least predictable), whose sharpest form is multi-agent debate. Prefer the most constrained shape that works, and treat more agents as a hypothesis, not a guarantee: debate can help, yet it does not reliably beat simpler baselines like self-consistency [5], [6].
- The three topologies are points in a larger design space. A survey of multi-agent LLM systems frames any team by a few dials: what the agents want (cooperate, compete, or both), how they are structured (centralized, peer-to-peer, or distributed), how roles are set, and what protocol governs their messages [4].
- Agents coordinate by direct messages or a shared blackboard, and a protocol (structured, parseable messages) is what keeps language-based coordination from drifting into noise.
- Coordinate by conversation or by workflow. Conversational frameworks (AutoGen’s conversable agents, CAMEL’s role-play) trade structure for adaptability; structured-workflow frameworks (MetaGPT’s standard-operating-procedure assembly line) trade adaptability for verifiable hand-offs that curb cascading errors [7], [8], [9].
- Pass context, not just messages. Share full traces so agents do not fill gaps with conflicting assumptions, and pass large results by reference to a shared store to avoid the game of telephone [2], [3].
- Well-connected teams show emergence: behavior no single agent was programmed for, as the Smallville simulation’s self-organized party showed. Emergence brings both the magic and the unpredictability [10].
- Guard against the failure modes: miscoordination, cost/latency blow-up, and error propagation. A study of 1,600+ traces (the MAST taxonomy) sorts the observed failures into specification and design, inter-agent misalignment, and verification, and finds multi-agent gains are often minimal, so build a team deliberately [12]. The defenses are a single accountable agent where possible, structured protocols, bounded conversation, and, most of all, observability.
Part 3 has taken us from one augmented model to a coordinated team, always adding structure only when the problem demanded it. What we have never done is measure whether any of it works. That gap, trusting rather than verifying, is where Part 4 begins, with the discipline of evaluating agents: Chapter 15.
14.8 Exercises
- One or many? Give one task you would solve with a single agent and one you would solve with a team, and justify each using the decomposition-and-perspective test from the opening.
- Pick a topology. For a system that drafts, fact-checks, and publishes an article, choose supervisor, handoff, or peer network, and explain why that shape fits.
- Message or blackboard? Describe a situation where a shared blackboard clearly beats direct messaging, and one where the reverse is true.
- Spot the emergence. In the Smallville party, name one behavior that was explicitly programmed and one that emerged, and explain the difference.
- Trace a cascade. Sketch a three-agent chain in which a small early error becomes a confidently wrong final answer, then name one defense that would have caught it.
- Weigh the cost. A multi-agent system can use on the order of fifteen times the tokens of a single chat. Describe one task where that cost is clearly worth paying and one where it clearly is not, and explain what makes the difference.
- Design against MAST. Pick one failure family from the taxonomy (specification and design, inter-agent misalignment, or task verification) and describe a concrete guardrail you would add to the supervisor-and-two-workers example to defend against it.
- Turn dials, not switches. Take a system you would like to build and describe it along the survey’s design-space dials: what the agents want, how the team is structured, how roles are set, and what protocol governs their messages. Which single change would most reduce its risk?
- Conversation or workflow? For a task of your choice, sketch it once as a flexible conversation (AutoGen or CAMEL style) and once as a structured SOP workflow (MetaGPT style), and argue which fits better and why.
- Interrogate the crowd. You are told a five-agent debate “beats” a single model on your task. List three things you would measure before believing it, given that debate does not reliably outperform simpler baselines.