“Memory is the diary that we all carry about with us.”
— Oscar Wilde, The Importance of Being Earnest
After this chapter you will be able to design short- and long-term memory for agents and implement retrieval-backed memory.
11.1 Opening intuition
The previous chapter left our agent with capable hands but a troubling flaw: it acts, and then it forgets. Every tool call, every clever bit of reasoning, every fact the user just told it lives only inside the current conversation and vanishes the moment that conversation ends. We flagged this gap once already, when we introduced memory as one of the augmented LLM’s three augmentations in Section 6.5. Now we make good on that promise and give the agent a past.
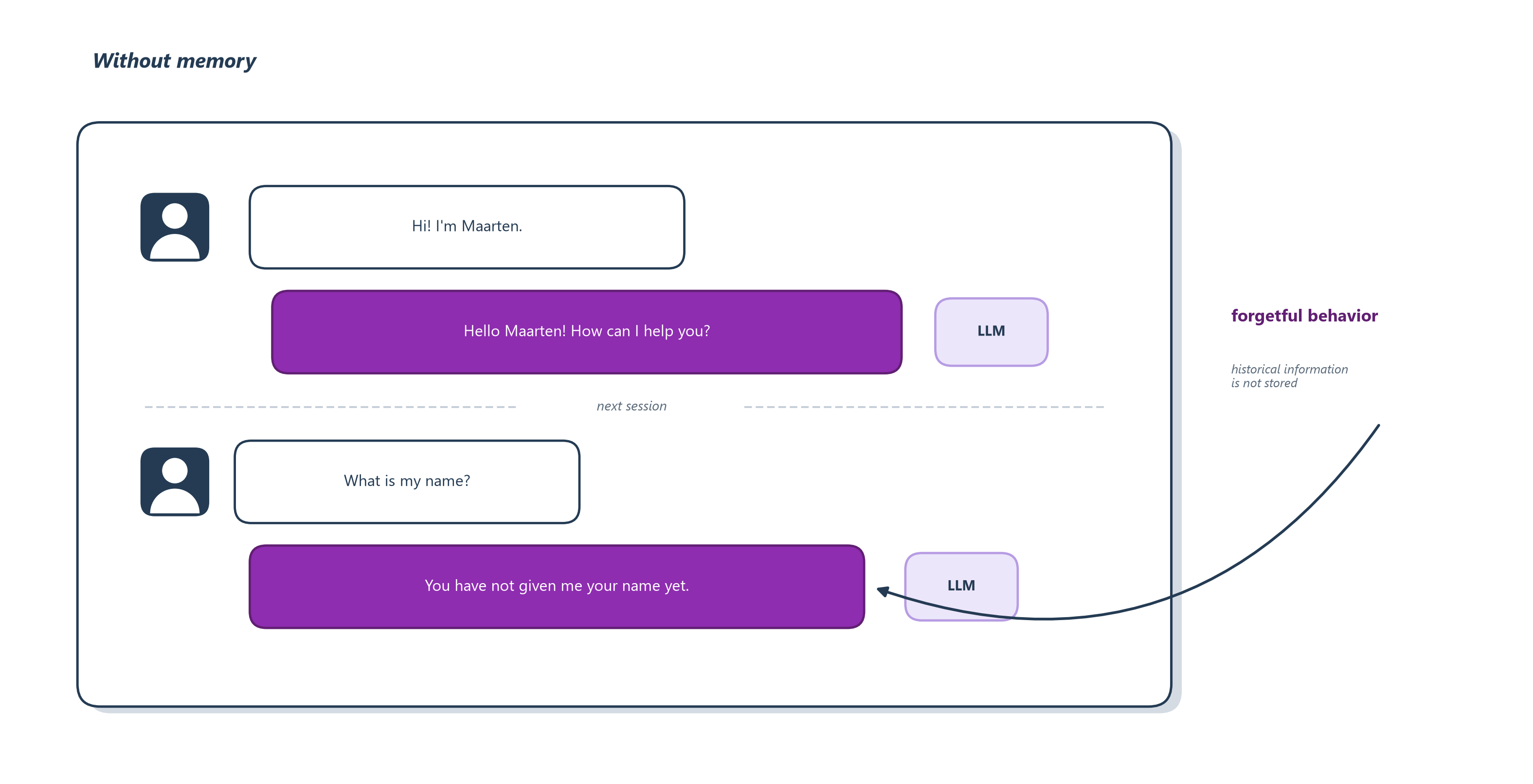
To feel why this matters, imagine a brilliant colleague with a peculiar condition: every morning they arrive having forgotten everything from the day before. Their raw intelligence is intact, so they can still reason, write, and solve, but you must reintroduce yourself daily, re-explain the project from scratch, and re-teach every preference you have ever stated. You would never call such a person a good assistant, however smart they are, because usefulness compounds through memory and theirs never accumulates. A stateless LLM is exactly this colleague. The model’s weights hold vast general knowledge, but about you, this task, and what just happened, it knows only what fits in the context window in front of it, and when that window scrolls past or the session closes, it is morning again and everything is forgotten. Figure 11.1 shows the failure in miniature: within a single session the model happily greets the user by name, yet one session later it has no record of ever being told who they are.
Figure 11.1: Without memory, an LLM is stateless. It can use your name within a single session, but once a new session begins that context is gone, and asked for your name it has no record of ever being told. Closing this gap is the job of the rest of the chapter.
Memory is what turns a clever text generator into an assistant that grows more useful the longer you work with it. It is the difference between a tool you operate and a partner that learns your world. Before we take memory apart, it helps to name the jobs we are asking it to do, because a memory system earns its keep only if it can do all of them at once:
Maintain continuity across the turns of a single conversation.
Personalize across sessions, so the agent remembers you from week to week.
Preserve task state across long-horizon work that spans many steps.
Learn from both successes and failures, not just recall what was said.
Retrieve the right context at the right time, from a store far too large to fit in a prompt.
Forget what is stale, trivial, or harmful, so recall stays sharp and cheap.
Respect privacy, deletion, and governance, because memory holds real user data.
That is a demanding list, and no single trick satisfies it. But “memory” is not one thing either, and building it well means being precise about which kind of memory a situation calls for: the fleeting kind that holds the current conversation, or the durable kind that carries knowledge across weeks. Human minds solve this with several distinct memory systems working together, and that turns out to be a remarkably good blueprint for agents. So we begin by taking the human mind apart, gently, to see what kinds of memory there are.
11.2 Types of memory
When psychologists talk about human memory, they do not treat it as a single bucket. They distinguish several systems that do different jobs, and borrowing their vocabulary is the clearest way to organize an agent’s memory too. Three distinctions matter for us: the fast, fleeting store that holds the present moment; the durable stores that divide by what kind of thing they remember; and the architectural line between what lives inside the model and what must live outside it. We take them in turn.
11.2.1 Working memory: the context window
The first and most immediate system is working memory, the handful of things you are actively holding in mind right now, like the digits of a phone number you are about to dial. It is fast, it is small, and it empties quickly. For an agent, working memory has an exact counterpart we have already been using all book long: the context window. Everything currently in the prompt (the system instructions, the conversation so far, the last tool result) is the agent’s working memory, and like yours it is strictly bounded and lost when attention moves on.
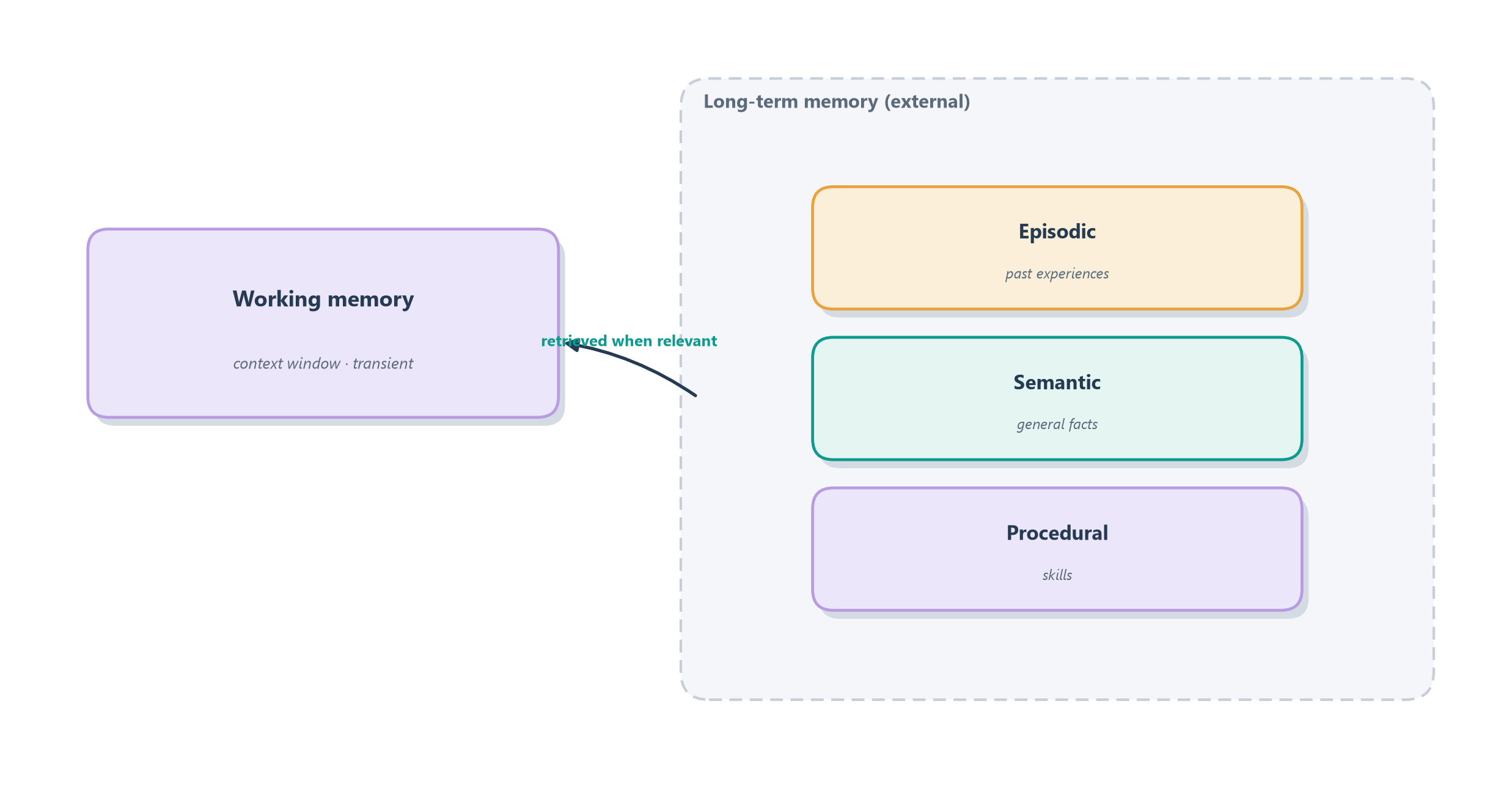
The other three systems are all forms of long-term memory, the durable store that survives past the present moment, and they divide by what kind of thing they remember. Episodic memory holds specific past experiences, such as remembering that you had coffee with Sam last Tuesday and she mentioned changing jobs. Semantic memory holds general facts stripped of the occasion on which you learned them, like knowing that Paris is the capital of France without recalling when you first heard it. And procedural memory holds skills, the how-to knowledge of riding a bicycle that you can perform without being able to state in words. Each maps cleanly onto something an agent needs: a log of past interactions (episodic), a store of learned facts about the user and domain (semantic), and reusable routines or successful strategies (procedural). Figure 11.2 lays the family out.
Figure 11.2: The memory systems, borrowed from human cognition. Working memory is the agent’s context window: fast, small, and transient. Long-term memory divides into episodic (past experiences), semantic (general facts), and procedural (skills), each persisted outside the model and retrieved when relevant.
11.2.3 Procedural memory: a library of skills
Two of those long-term stores deserve a closer look, because agents lean on them in ways the one-line definitions undersell, and the first is procedural memory. Semantic memory stores facts and episodic memory stores events, but procedural memory stores reusable ways of acting, the how-to knowledge you can perform without reciting. Think of a chef’s private binder of recipes. It is not a diary of dinners cooked (that would be episodic) nor a list of ingredient facts (that would be semantic). It is a growing collection of procedures, each one a reliable sequence the chef worked out once and now reaches for whenever the same dish is ordered.
The Voyager agent turned this idea into a working system inside Minecraft [1]. As it explored, Voyager wrote successful behaviors, such as how to craft a tool or fight off a monster, into an ever-growing skill library of executable code, and it retrieved and reused those skills when a new task called for them, composing simple skills into complex ones over time [1]. The payoff is compounding competence: the agent does not re-derive how to do a thing it has already mastered, it looks the skill up and runs it. That is procedural memory doing exactly what your chef’s binder does, sparing you from reinventing a recipe you already perfected.
11.2.4 Reflective memory: lessons learned
The second store worth adding is one the classic taxonomy leaves out, and it matters enough for agents to name on its own: reflective memory, the store of lessons learned. Episodic memory records what happened; reflective memory records what the agent concluded from what happened. The difference is the one between a diary entry (“the soufflé collapsed on Tuesday”) and the lesson you draw from it (“open the oven less near the end”). The event is raw experience; the reflection is distilled wisdom, and it is the reflection that changes how you act next time.
Reflexion built agents around exactly this move [2]. After a failed attempt, the agent generates a short verbal self-critique of what went wrong and stores that reflective text in its memory, so that on the next attempt the lesson is retrieved and folded into context, steering the agent away from the mistake [2]. Crucially, nothing in the model’s weights changes; the improvement lives entirely in remembered words, a kind of learning by note-taking rather than retraining. Reflective memory is how an agent turns its failures into guidance instead of repeating them, and we will see it earn its place when Ledgerly learns from a refund it should never have issued.
11.2.5 The research view: forms, functions, and dynamics
The human taxonomy, working, episodic, semantic, procedural, reflective, is the intuitive on-ramp, and it will carry us through most of this chapter. But it is worth knowing that agent-memory research has outgrown the simple short-term-versus-long-term split and now describes memory along three richer axes [3]. The first is form, meaning what physically carries the memory: tokens in the context window, weights baked into the model’s parameters, latent internal state, or records in an external store. The second is function, meaning what the memory is for: factual knowledge, lived experience, or the working scratchpad of the current task. The third is dynamics, meaning how a memory behaves over time: how it forms, how it is updated, how it decays or is forgotten, and how it is retrieved [3].
The value of this lens is that it separates questions the human taxonomy tends to blur. “Is this memory episodic or semantic?” is a function question; “does it live in the prompt or in a database?” is a form question; “should it fade next month?” is a dynamics question. A production memory system has to answer all three for every memory it holds, and much of the rest of this chapter is really about form (where memories live) and dynamics (how they change), with the human functions as our familiar vocabulary. Keep this map in your back pocket; it explains why two systems that both claim to give an agent “memory” can be doing utterly different things.
11.2.6 Inside the model, or outside it
The forms axis points straight at the crucial architectural fact, the one that drives the rest of the chapter. Working memory lives inside the model’s context window and is therefore small, fast, and free to read, yet fleeting and finite. Long-term memory must live outside the model, in some external store you control, precisely because it has to persist beyond a single context and can grow far larger than any window could hold. That immediately raises the defining challenge of agent memory: if the durable knowledge sits outside the model, how do you get the right piece of it back into the tiny working-memory window at the moment it is needed? You cannot pour a lifetime of memories into a single prompt. You need a way to reach into a vast store and pull out just the few memories relevant to right now, and that retrieval problem is exactly what vector stores were built to solve.
11.3 Long-term memory with vector stores
The retrieval problem we just posed should feel familiar, because we met its twin in Section 6.4 when we gave the augmented LLM an open book through retrieval-augmented generation [4]. Long-term memory is RAG pointed inward: instead of retrieving from a corpus of external documents, the agent retrieves from its own accumulated past. The machinery is the same, and it rests on one beautiful idea, the embedding, so it is worth building the intuition carefully.
11.3.1 Embeddings: shelving by meaning
Imagine a librarian who does not shelve books by title or author but by meaning. Every book is placed in a vast hall so that books about similar ideas sit near one another, all the sailing books in one region and all the cooking books in another, regardless of the exact words on their spines. To find what you want, you do not need the precise title. You describe the idea, and the librarian walks to that region of the hall and hands you the nearest books. An embedding is how we build that hall for a computer. A model turns any piece of text into a list of numbers, a point in a high-dimensional space, positioned so that texts with similar meaning land close together. “I love my dog” and “my puppy is wonderful” end up as near neighbors even though they share almost no words, while “quarterly tax filing” lands far away. Closeness in this space is similarity of meaning.
11.3.2 The write and read paths
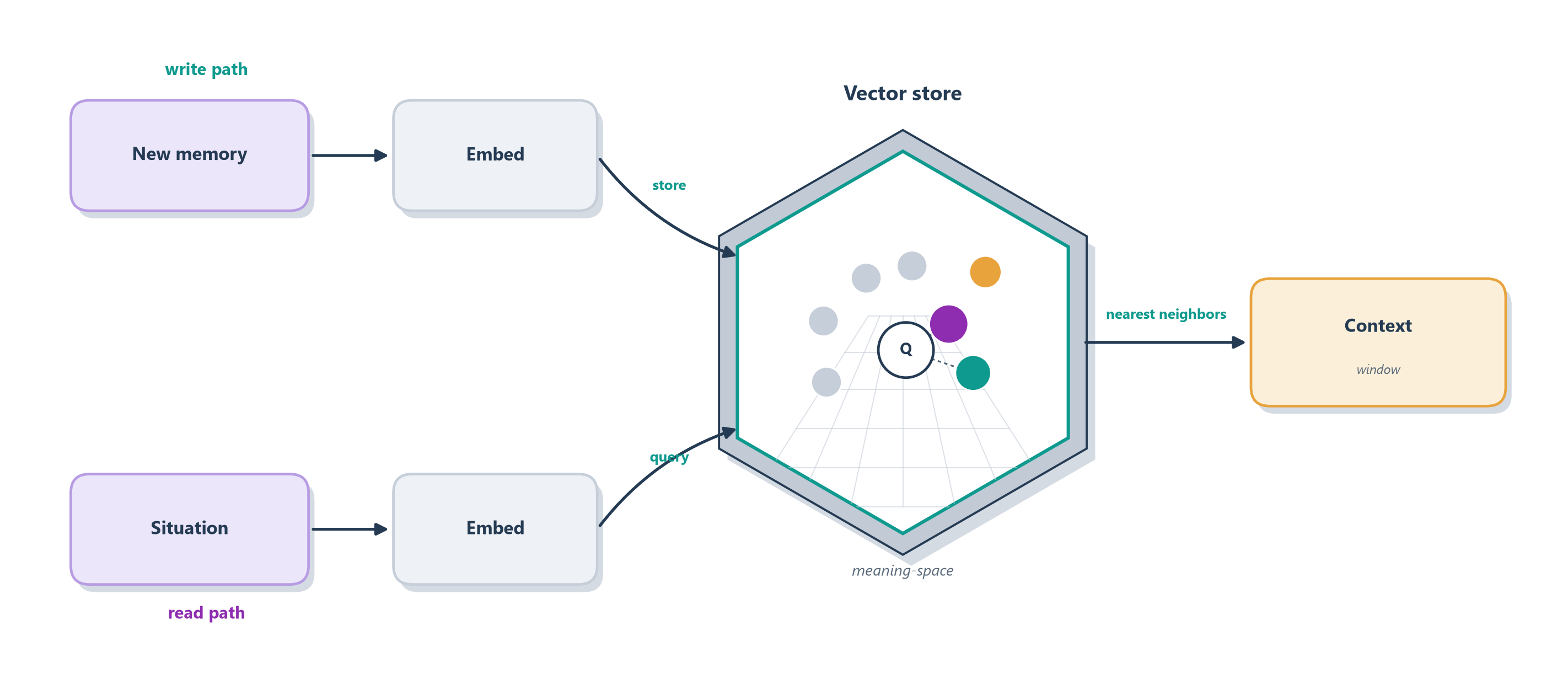
Once memories live as points in that space, retrieval becomes geometry, and it runs as two matching halves. On the write path, whenever something worth remembering happens, you embed it into a vector and store it, the vector alongside the original text, in a vector store, a database built to hold millions of these points and search them fast. On the read path, when the agent needs to remember, you embed the current situation into a query vector and ask the store for its nearest neighbors, the handful of stored memories whose points lie closest and are therefore the most semantically relevant. Those few memories, and only those, get pulled into the context window as working memory. Figure 11.3 shows both halves.
Figure 11.3: Long-term memory as a vector store. On the write path, each memory is embedded and stored as a point in meaning-space. On the read path, the current situation is embedded and used to fetch its nearest neighbors, the most relevant memories, which are placed into the context window.
This is what lets an agent draw on far more than could ever fit in a prompt. It might hold months of conversations, thousands of learned facts, and a whole history of past tasks, all sitting quietly in the vector store, and yet each turn it pays only for the three or four memories that actually matter, fetched by meaning in milliseconds. The vast store stays outside the model; the tiny relevant slice comes inside. It is the librarian trick applied to the agent’s own life. But notice the quiet assumptions we just made: that we knew what was “worth remembering” on the write path, and that nearest-neighbor relevance is all that should decide what comes back. Both turn out to be too simple. Before we refine either one, though, there is a prior question hiding in plain sight: of everything sitting in that vast store, what should occupy the agent’s scarce working context right now?
11.4 Memory as context management
That question has a beautiful precedent, and it comes from the operating system running the very computer you are reading this on. An OS faces the same predicament an agent does: it has a small amount of fast memory (RAM) and a large amount of slow storage (disk), and far more data than RAM can hold. Its trick is paging: keep the working set in RAM, leave everything else on disk, and page data in and out as the running program needs it, so the program feels like it has vast memory while only ever touching a small fast window at a time. The MemGPT project noticed that this is exactly the shape of the agent-memory problem and borrowed the OS design wholesale [5].
The mapping is clean and worth holding onto. The context window is RAM: small, fast, and where all real “thinking” happens. The external store is disk: large, slower to reach, effectively unbounded. Recall is paging in: fetching a memory from the store into the context so the model can use it. And summarization and eviction are memory management: when the context fills, compress or move older content back out to the store to make room, just as an OS evicts a page it does not currently need. MemGPT gives the agent explicit functions to move information across this boundary, letting it manage its own limited context and thereby hold conversations and documents far larger than the window could ever contain at once [5].
The reason this reframing matters is that it shifts the central question. We spent the last section asking where memories are stored, and vector search answered it. The OS view insists on a second, equally hard question: of everything in storage, what gets paged into the limited working context this turn? A perfect store is useless if the wrong three memories come into RAM. So memory design is really two disciplines working together, one that decides what to keep and where, and one that decides what to load right now, and the next section takes up the everyday techniques for both.
11.5 Memory management
A vector store solves where to keep memories, but it leaves open the harder, more human questions. What deserves to be remembered, what should fade, and how do you decide which memories matter now? These are the questions of memory management, and they exist for one unavoidable reason: the context window is finite, and every token in it costs money and attention. You cannot remember everything, surface everything, or keep everything forever. Good memory, for agents as for people, is as much about forgetting well as about storing.
11.5.1 Managing working memory: summarization
Start with the working-memory side, where the pressure is most acute. A long conversation will eventually overflow the context window, so you need a policy for what to do as it fills. The simplest is a sliding window that keeps the last N turns and drops the oldest, but that throws away potentially important early context. A better move is summarization: periodically compress the older parts of the conversation into a short synopsis and keep that in context instead of the raw transcript, trading fine detail for a durable gist. This is exactly what you do when recounting a long meeting. You do not replay it word for word; you say “we agreed to ship in March and Sam owns the launch.” Summarization is how an agent keeps the thread of a conversation far longer than its raw window could ever hold.
On the long-term side, the subtle problem is relevance, deciding which stored memories to pull back. Pure nearest-neighbor similarity, the tool from the last section, is necessary but not sufficient, and the Generative Agents project showed why with a memorable design [6]. Their simulated characters each kept a memory stream of everything they observed, and to decide what to recall they scored memories on three factors together rather than one: relevance (semantic similarity to the current situation, our vector search), recency (how long ago the memory formed, with older ones gently decaying), and importance (how significant the memory is, scored by the LLM itself, so that remembering a breakup outweighs remembering breakfast) [6]. Blending the three retrieves memories that are not merely similar but genuinely worth surfacing. The same project added a second idea worth stealing, reflection, in which the agent periodically reviews its recent memories and writes new, higher-level ones. It turns “Sam mentioned changing jobs” and “Sam asked about salaries” into the synthesized insight “Sam is job-hunting” [6]. Reflection is how episodic memories mature into semantic knowledge.
Tip
Treat forgetting as a feature, not a failure. An agent that faithfully stores and resurfaces every trivial exchange will drown its own context in noise, grow slower, and cost more with each turn. Deciding what not to remember, by pruning the trivial, decaying the stale, and summarizing the verbose, is a core part of memory design, not an afterthought to bolt on when the bill arrives.
11.5.3 Retrieval is more than similarity
The Generative Agents trio, relevance, recency, and importance, already hints that similarity alone is the wrong master. In a real production agent the gap is wider still, because a memory can be a perfect semantic match and yet be exactly the one you must not surface. Picture a customer-support agent that pulls the most similar past note and confidently repeats it, only for the note to be a year old, about a different account, since overturned by a policy change, and belonging to a customer who asked to be forgotten. Every one of those is a reason to reject a memory that vector search would happily rank first.
So a mature retrieval step blends several signals, not one, and weighs them against the current task:
Semantic relevance: does the memory mean the same thing as the current situation? (The vector score.)
Recency: how fresh is it? A memory from this morning usually beats one from last year.
Importance: how significant was it? A refund dispute outweighs a “thanks.”
Source trust: did it come from a verified record, or from the model’s own guess?
Scope and permission: is this memory allowed to be used for this user, in this context?
Temporal validity: is it still true now, or was it only true for a past window?
Conflict status: has a newer memory contradicted and superseded it?
Usage success: the last time this memory was surfaced, did it actually help?
No agent needs all eight tuned to perfection, but every serious one blends more than raw similarity. The Ledgerly framing makes the stakes concrete: a memory can be semantically similar to the current ticket and still be old, unauthorized, contradicted, or out of scope for the customer in front of the agent, and surfacing it would be worse than surfacing nothing. Good retrieval is therefore an act of judgment across signals, not a single nearest-neighbor lookup.
11.5.4 Forgetting is a design feature, not a bug
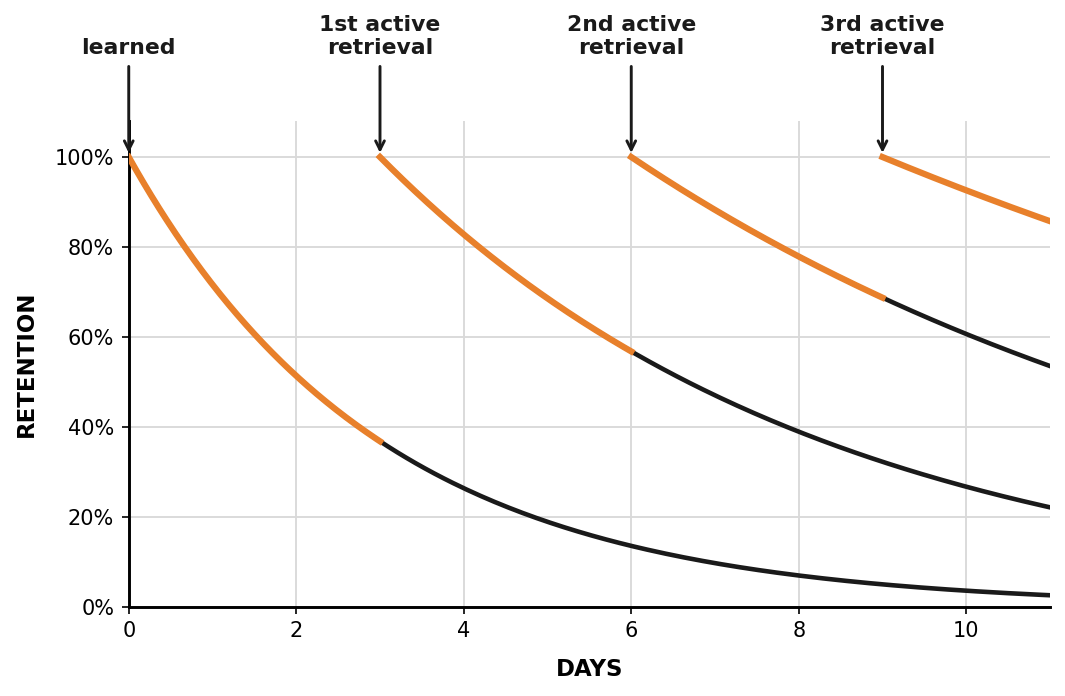
The callout above called forgetting a feature; it is worth taking that seriously, because a store that only ever grows is a store that slowly poisons itself with stale and contradictory memories. Human memory solved this long ago, and MemoryBank built an agent memory around the solution [7]. Inspired by the Ebbinghaus forgetting curve, the psychological finding that we forget on a predictable decay unless a memory is reinforced by use, MemoryBank lets memories fade over time while frequently recalled ones are strengthened, and it continually updates what it knows about a user as new interactions arrive [7]. The result behaves less like a database and more like a mind that keeps what matters and quietly lets go of the rest.
Figure 11.4: The Ebbinghaus forgetting curve, and why decay is a feature rather than a flaw. A memory learned once fades fast (the steep black curves), but each active retrieval snaps retention back to full and, crucially, flattens the next decay, so a well-used memory lingers far longer than a neglected one. An agent’s memory store runs the same rule: reinforce what keeps proving useful, and let the unused quietly fade.
That gives us three lifecycle operations to run over long-term memory, and Ledgerly shows each one in miniature. Reinforce the memories that keep proving useful, so “this customer is on annual enterprise billing” stays strong because it is relevant on nearly every ticket. Decay the memories that go stale and unused, so a one-off “preferred email updates in 2024” is allowed to fade rather than clutter every recall. And update a memory when a new fact contradicts the old one, so when the billing owner changes from Alex to Priya the agent overwrites the stale contact rather than carrying two conflicting truths. Reinforce, decay, update: those three verbs are what keep a long-lived memory sharp instead of turning it into an attic.
Taken together, these techniques turn a raw vector store into something that behaves like a mind: holding the current thread in working memory, distilling it when it grows long, remembering the significant while letting the trivial fade, and occasionally stepping back to form new understanding. That is a lot of moving parts, so let’s assemble them into one concrete agent and watch a single memory travel through the whole system.
11.6 A worked example: an assistant that remembers you
Let’s make all of this concrete by building the very thing our amnesiac colleague could never be: a personal assistant that gets to know you across sessions. The goal is simple to state: when you come back next week and say “book me the usual,” it should know what “the usual” means. And it falls right out of the pieces we have assembled. Follow one preference as it is born, stored, and later recalled, and the whole system will click into place.
The assistant wraps every turn in a read-act-write cycle, three beats around the model. On the read beat, before answering, it embeds what you just said and queries the vector store for the most relevant long-term memories, folding them into the context window alongside the recent conversation. This is the read path from Section 11.3, run live. On the act beat, the model does its normal work with that enriched context, now aware of both the immediate thread and the relevant past. On the write beat, after responding, it decides whether anything in the exchange is worth keeping and, if so, embeds and stores it for next time. The spine is just this:
Now watch a single memory live its life. In week one you mention, in passing, “I always fly window seats, and I hate red-eyes.” The write beat notices this is a durable preference, not idle chatter, and stores it as an episodic memory of what you said. Weeks pass and dozens of other conversations pile into the store, but this one sits quietly among them, costing nothing. Then, next month, you say “book me a flight to Boston.” The read beat embeds that request, and because “book a flight” lands near “window seats” and “red-eyes” in meaning-space, nearest-neighbor search surfaces your preference and slips it into context. The model, now reminded, books a daytime window seat without your having to repeat yourself. To the user it feels like being known; under the hood it is nothing more than the read-act-write loop turning, with a vector store standing in for a past.
Everything from the chapter shows up in that little story. Working memory held the live conversation; the vector store held the durable preference; nearest-neighbor retrieval fetched it by meaning rather than exact words; and a write-time judgment about what was “worth remembering” kept the store from filling with noise. Layer on the management techniques from the last section (summarize the conversation when it grows long, score recalls by importance and recency as well as relevance, and reflect occasionally to notice “this user values convenience over price”), and the same humble loop grows into a genuinely personal assistant. That is the payoff of memory: not a cleverer model, but a system that compounds, growing more useful with every interaction.
11.7 Memory is a lifecycle, not a database
The worked example is a good place to confess something the word “store” has been quietly hiding. We keep saying an agent stores memories, as if memory were a database with a write and a read, but a database is a poor model for what we have actually been building. A database holds whatever you put in it, unchanged, forever, and hands it back exactly as given. Real memory does none of that. It selects what is worth keeping, reshapes it over time, promotes some records and quietly drops others, and answers questions the raw data never explicitly stored. Memory is less a container than a lifecycle, a loop that a piece of information travels through, and naming the stages of that loop is the single most useful mental model in this chapter.
A useful memory system has to answer five questions in turn, one per stage, and Figure 11.5 draws them as the loop they form. Observe: what just happened that the agent might want to keep? Write: is it worth recording, and in what form? Consolidate: how do today’s raw records mature into durable, higher-level knowledge? Retrieve: which memories belong in the context for the situation at hand? Update or forget: what should change, decay, or be deleted as the world moves on? Answer those five well and you have a memory system; skip any one and you have a leaky container.
flowchart LR O[Observe<br/>raw events] --> W[Write<br/>record if worth keeping] W --> C[Consolidate<br/>episodes to facts,<br/>traces to skills,<br/>failures to lessons] C --> R[Retrieve<br/>surface the right memories] R --> U[Update or forget<br/>decay, overwrite, delete] U -.-> O
flowchart LR
O[Observe<br/>raw events] --> W[Write<br/>record if worth keeping]
W --> C[Consolidate<br/>episodes to facts,<br/>traces to skills,<br/>failures to lessons]
C --> R[Retrieve<br/>surface the right memories]
R --> U[Update or forget<br/>decay, overwrite, delete]
U -.-> O
Figure 11.5: Memory as a lifecycle loop. Raw observations are written, consolidated into durable knowledge, retrieved when relevant, and continually updated or forgotten, and the cycle feeds itself as new observations arrive.
The consolidate stage is where the memory types from earlier stop being a static list and start being a set of transformations, which is the loop’s real magic. Raw events become episodic memories of what happened. Repeated episodes distill into semantic facts, the way many “the user chose the window seat” observations become the belief “this user prefers window seats.” Successful action traces harden into procedural memories, reusable skills in the sense of Section 11.2.3. Failed attempts turn into reflective lessons, in the sense of Section 11.2.4. Meanwhile the update-or-forget stage keeps the whole thing honest: old and unused memories decay, contradicted memories are overwritten, and sensitive memories stay scoped, auditable, and deletable rather than lingering forever. Each verb from the last two sections lands on a stage of this loop.
Ledgerly runs the full lifecycle on every ticket, and tracing one complaint through it shows why the loop matters more than any single store. The agent observes a customer reporting a double charge. It writes an episodic note of the incident. Over many such tickets it consolidates: the repeated incidents become the semantic fact “duplicate charges spike right after plan migrations,” and the steps that reliably fixed them become a procedural runbook. On the next migration-related complaint it retrieves that fact and that runbook into context. And as the world changes it updates or forgets: a superseded refund policy is overwritten, a resolved one-off is allowed to decay, and a customer’s deletion request is honored end to end. The store never changed shape, but the memory matured, and that maturation is the whole point.
11.7.1 What not to remember
The lifecycle has a quiet twin that production systems ignore at their peril: for every rule about what to keep, there is a rule about what to leave out, and the write stage is where discipline pays off most. A memory system is only as trustworthy as the things it refuses to store, so it is worth being explicit about what does not belong in long-term memory.
Trivial politeness. “Thanks!” and “no worries” carry no durable signal; storing them only dilutes recall and inflates cost.
Raw sensitive data, unless truly necessary. Card numbers, government IDs, and health details should be minimized, redacted, or referenced by handle, not copied wholesale into a memory store.
Temporary facts dressed up as permanent preferences. “Ship it to my hotel this week” is a one-off, not a standing address; promoting it to a preference will mislead every future turn.
Unverified model guesses stored as facts. An inference the model made (“they seem to be on the Pro plan”) must be labelled as a guess, never written as ground truth.
Policy outputs without provenance. A decision like “refund approved” is only safe to remember alongside why and under which policy version, so a later audit can reconstruct it.
Anything with no deletion or audit path. If a memory cannot be found, explained, and erased on request, it should not be written in the first place.
Each of these is a small act of restraint, and together they are what separates a memory system you can put in front of real customers from one that quietly accumulates liability. This is also where memory design starts to shade into safety and governance, a thread we pick up in earnest in the safety chapter. For now the rule of thumb is simple: when in doubt about a memory, the safe default is not to store it.
11.8 Memory as a graph, not just a list
There is one more shape memory can take, and it addresses a blind spot in everything we have built so far. A vector store is, at heart, a list of memories that happens to be searchable by meaning. Ask it a question and it hands back the items that most resemble your query, each one considered in isolation. But some of the most valuable things an agent needs to know are not properties of any single memory; they are relationships between memories. A vector store can find the note about a customer’s refund and, separately, the note about their plan migration, yet it has no notion that the first was caused by the second. For that you need not a list but a graph.
The intuition is the difference between a stack of index cards and a detective’s cork board. The cards each hold a fact, and you can flip through them for the one that matches. The cork board holds the same facts as pinned nodes, but it adds the strings between them: this invoice belongs to that subscription, which underwent that plan migration, which triggered these failed payments, which the refund policy governs, which a prior resolution already handled. When the question is “why does this customer keep getting double charged,” the strings are the answer, and no amount of similarity search over isolated cards will reconstruct them. A graph memory represents customers, subscriptions, invoices, plan migrations, failed payments, refund policies, and prior resolutions as connected entities, so the agent can follow the relationships instead of guessing at them.
The honest caveat is that graphs are not free and not always worth it. They help precisely when relationships carry the meaning, as in Ledgerly’s tangle of billing entities, and add mostly overhead when memories are independent, as in a pile of unrelated user preferences. The Mem0 system is a useful reference point here: it dynamically extracts, consolidates, and retrieves the salient facts from a conversation, and it offers a graph variant that additionally captures the relational structure among those facts for cases where the connections matter [8]. It is one representative production approach, not the only one, and the right choice depends on whether your domain’s value lives in the nodes or in the edges between them.
Tip🛠️ In practice: memory must be cheap enough to use every turn
Whatever shape you choose, memory is paid for on every turn, so its cost is not incidental, it is the design constraint. The naive baselines make the trade-off vivid. Replaying the entire history into the context each turn is trivial to build but grows unboundedly expensive and eventually overflows the window. Naive retrieval-augmented generation is cheaper but sprays the context with loosely relevant chunks, adding noise that can degrade answers. A structured memory that stores consolidated facts, skills, and relationships, and retrieves only the few that matter, is the design that keeps both the token bill and the noise low enough to afford on every single turn. Reported production results bear this out: Mem0 reports large latency and token-cost reductions against a full-context baseline while improving answer quality [8]. Treat “can I afford to run this memory on every turn?” as a first-class question, not an afterthought.
11.9 Case study: the Ledgerly support agent
Where we left off, Section 6.7 promised the Ledgerly agent a notebook, and the write beat that stored “this customer hit a billing bug” was its first note. This chapter’s taxonomy tells us that note was episodic, and Ledgerly benefits from every kind of memory from Section 11.2 working together, matured through the lifecycle of Section 11.7.
Episodic memory is the log of past tickets: this customer reported a double charge in March, and we refunded it. When they write in again, the read beat surfaces that history so the agent never makes them re-explain, exactly the “feels known” effect from the worked example in Section 11.6. Semantic memory holds durable facts distilled from those episodes: this customer is on the Pro plan, prefers email over chat, and has been with Ledgerly for two years.Procedural memory holds the reliable runbooks the agent has learned for recurring jobs, in the sense of Section 11.2.3: how to investigate a duplicate charge after a plan migration, how to validate refund eligibility, and how to escalate a policy exception, each a reusable sequence rather than a fact or an event.
Reflective memory is the newest and, for a support agent, the most valuable, because it is how Ledgerly stops repeating expensive mistakes. Suppose the agent once issued a refund before checking the migration logs and later discovered the charge had been legitimate. The lesson from that failure, in the sense of Section 11.2.4, is not another fact about the customer; it is a note to itself: for plan-migration complaints, check the migration logs before deciding refund eligibility. Stored as a reflective memory and retrieved the next time a migration complaint arrives, that single sentence steers the agent away from the mistake it made before, with no retraining required.
Those kinds, and Ledgerly’s policy for each, make a compact memory plan:
Memory type
Ledgerly example
Keep or decay
Episodic
“double charge in March, refunded”
keep significant incidents
Semantic
“on the Pro plan, prefers email”
keep durable preferences
Procedural
the ordered steps of a refund
keep the reliable runbook
Reflective
“check migration logs before refunding”
keep hard-won lessons
Transient
“thanks!”
let it decay
All of these live outside the model in Ledgerly’s memory store and reach the agent through the read-act-write loop from Section 11.6. On each ticket the agent embeds the incoming message, retrieves the customer’s most relevant memories by meaning (Section 11.3) while weighing the other signals from Section 11.5.3, so a memory that is old, unauthorized, contradicted, or out of scope is not blindly surfaced, acts with that history in context, and writes back anything worth keeping. And because forgetting is a feature (Section 11.5.4), Ledgerly does not store every “thanks!”. It reinforces the durable preferences and significant incidents, lets the trivia decay, and updates a fact like “billing owner changed from Alex to Priya” rather than carrying both, so recall stays sharp and the bill stays low.
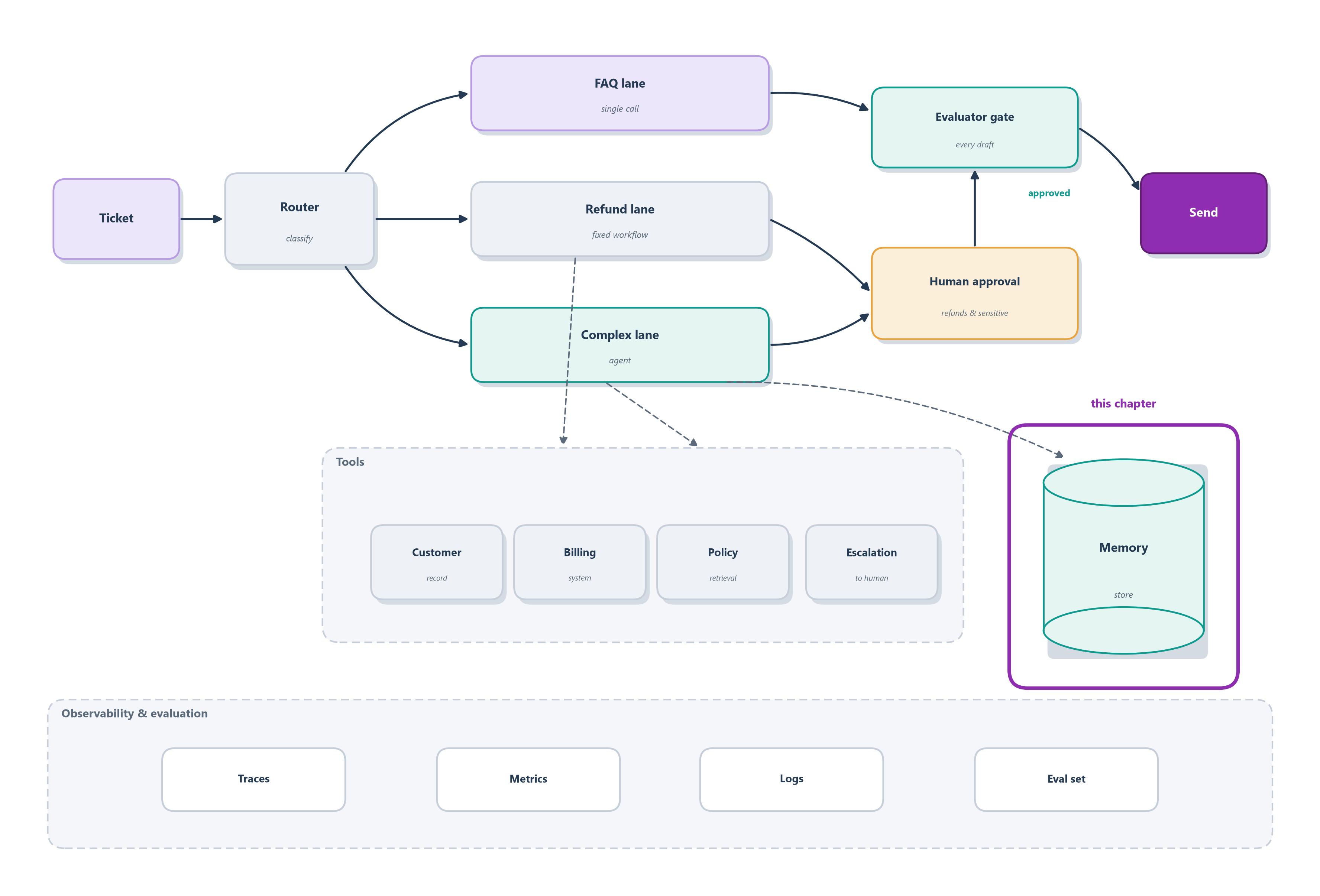
On the system blueprint, this chapter switches on the memory store (Figure 11.6), the one part every lane quietly leans on.
Figure 11.6: The same Ledgerly blueprint with its memory store lit: an external vector store the lanes read from and write back to on every ticket.
Ledgerly now reasons, acts through bounded tools, and remembers its customers, yet it is still one loop improvised turn by turn. Section 12.7 gives that loop a durable skeleton, modeling the whole agent as a graph with checkpoints and a human approval step before any refund goes out.
Note🧾 Ledgerly so far
The notebook grows into a real memory:
Router to three lanes; shared evaluator gate; MCP-served tools.
New this chapter: memory becomes a lifecycle over four stores, episodic (past tickets), semantic (durable facts), procedural (learned runbooks), and reflective (hard-won lessons), retrieved by blended signals and kept sharp by a reinforce/decay/update policy (Figure 11.6).
11.10 How do we know memory works?
We have built a lot of machinery, and an honest engineer’s next question is uncomfortable: how would we know if any of it actually worked? It is tempting to assume that a bigger context window or a fancier store must mean better memory, but memory is a capability, not a component, and capabilities have to be measured. The trap to avoid is treating “the model has a huge context window” as a proof of good memory. It is not, and the benchmarks below exist precisely to tell the two apart.
Start with what a memory test should actually probe, because “does it remember?” is too blunt. A thorough evaluation checks recall accuracy (does the right fact come back?), retrieval precision (does only the right fact come back, or a pile of noise with it?), latency and token cost (can you afford the memory on every turn?), update correctness (when a fact changes, does the new one win?), forgetting correctness (does stale or deleted information actually disappear?), conflict handling (when two memories disagree, does the agent resolve it?), privacy and permission enforcement (are scoped memories kept scoped?), robustness to false memories (does a planted or hallucinated “fact” get trusted?), and the ability to abstain (when the answer was never stored, does the agent say so instead of inventing one?). That last one matters more than it sounds: an agent that confidently fabricates a memory is worse than one that admits it does not know.
Three recent benchmarks turn that wish list into concrete tests, and reading them together is the fastest way to calibrate your expectations. LongMemEval evaluates chat assistants on five core long-term abilities, information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention, and it frames memory design as three stages worth measuring separately: indexing, retrieval, and reading [9]. Its headline finding is a warning for anyone who trusts raw context length: commercial assistants and long-context models showed a sharp accuracy drop when they had to hold information across sustained, multi-session interactions [9]. LoCoMo pushes on sheer length, with conversations averaging around 300 turns across up to 35 sessions, and finds that both long-context models and retrieval-augmented approaches help but still lag well behind humans on long-range temporal and causal reasoning [10]. The lesson from both is the one to tattoo on the wall: long context is not the same as good memory.MemBench rounds out the picture by evaluating memory along multiple aspects, effectiveness, efficiency, and capacity, and by distinguishing factual memory from reflective memory as different levels to test, which is exactly the episodic-versus-reflective distinction we drew earlier [11].
For Ledgerly, this is the difference between a demo and a service you can trust with refunds. A memory that recalls a customer’s history but cannot abstain when it has none will invent a phantom prior ticket; a memory that cannot handle updates will keep refunding against a policy that changed last month; a memory that cannot enforce scope will leak one customer’s data into another’s conversation. Measuring those failure modes, rather than assuming a big context window rules them out, is the whole job, and it is the bridge into the evaluation chapter, where we make this discipline systematic in Chapter 15.
11.11 Where memory research is going
It is worth closing with a brief look over the horizon, clearly labelled as forward-looking rather than settled practice, because the direction of travel changes how you should build today. Almost everything in this chapter treats memory as a fairly passive store: the agent writes records, and retrieval later pulls the relevant ones back. The emerging frontier is active memory, memory that organizes and rewrites itself rather than waiting to be queried.
The A-MEM system is a good marker of this shift [12]. Inspired by the Zettelkasten method of note-taking, in which every new note is deliberately linked to related existing notes to grow a web of knowledge, A-MEM builds richly annotated memories and dynamically forms links between them, and it allows memory evolution, where adding a new memory can update the descriptions of older, related ones [12]. The store stops being a flat list and becomes a self-organizing network that gets smarter as it grows. For Ledgerly, the promise is tangible: a new duplicate-billing complaint would not land as an isolated note but would link itself to the earlier plan-migration failures it resembles, and over time those links would let the system evolve from a scatter of individual tickets into a map of recurring billing-failure patterns, the kind of structural insight no single memory ever explicitly recorded. Whether or not any particular system wins, that trajectory, from passive storage to active organization, is the one to watch.
11.12 Summary
This chapter gave the agent a past, turning a stateless text generator into an assistant whose usefulness compounds over time.
Without memory, every turn starts from zero. A stateless LLM is a brilliant colleague with daily amnesia; memory is what lets usefulness accumulate.
Borrow the mind’s taxonomy, then go past it.Working memory is the context window; long-term memory persists outside the model as episodic (events), semantic (facts), procedural (skills, as in Voyager [1]), and reflective (lessons, as in Reflexion [2]). Research adds a sharper lens still: memory by form, function, and dynamics[3].
Long-term memory is RAG pointed inward. Embeddings place memories as points in meaning-space, so recalling one means embedding the current situation and fetching its nearest neighbors.
Manage the scarce context like an OS manages RAM. The context window is RAM, the store is disk, and recall is paging the right memories in, as MemGPT framed it [5].
Retrieval is judgment, not just similarity. Blend relevance, recency, and importance [6] with source trust, scope, temporal validity, and conflict status, so an old, unauthorized, or contradicted memory is not blindly surfaced.
Forgetting is a design feature. Reinforce useful memories, decay stale ones, and update contradicted ones, in the spirit of MemoryBank’s forgetting curve [7].
Memory is a lifecycle, not a database. Observe, write, consolidate, retrieve, and update-or-forget; a graph memory [8] adds the relationships a flat list cannot hold.
Measure it, do not assume it. Long context is not good memory; benchmarks like LongMemEval [9], LoCoMo [10], and MemBench [11] test recall, updates, abstention, and more.
Our agent can now reason, act through well-designed tools, and remember across time. It has, in a sense, all the faculties of a capable individual. But so far it has always been a single agent running a single loop, and our worked examples have quietly grown more elaborate: read, act, write; route, retrieve, reflect. Coordinating all these moving parts reliably, with state that persists and steps that can branch and resume, is an engineering problem of its own. The next chapter picks up a framework built precisely for it: orchestrating agents as graphs, in Chapter 12.
11.13 Exercises
Classify the memory. For each, name the type (working, episodic, semantic, procedural, or reflective): (a) the last five messages of the current chat; (b) “the user’s daughter is named Mia”; (c) “on March 3rd the user reported a login bug”; (d) “the reliable way to reset this account is steps X, Y, Z”; (e) “last time I refunded before checking the logs, I was wrong, so check the logs first.”
Episodic versus reflective. Explain, in your own words, the difference between an episodic memory and a reflective one, using an example from your own life. Why is it useful for an agent to store the two separately rather than collapsing them into one log?
Why embeddings, not keywords? Explain why a keyword search for “dog” would miss the memory “my puppy is wonderful,” and how embedding-based retrieval fixes it. Give another pair of texts that mean the same thing while sharing no words.
Beyond similarity. Pick three of the retrieval signals from Section 11.5.3 (say, recency, scope, and conflict status) and, for each, describe a case where the most semantically similar memory is the wrong one to surface and that signal would catch the mistake.
Design a forgetting-and-update policy. For a customer-support agent, sketch rules for which memories to reinforce, which to decay, and which to update or overwrite. Justify each rule in terms of relevance, correctness, and cost, and name one memory you would refuse to store at all (Section 11.7.1).
Walk the lifecycle. Using the five stages from Section 11.7 (observe, write, consolidate, retrieve, update-or-forget), trace what should happen to the fact “the user is vegetarian” from the moment they mention it, through several later dinner-recommendation sessions, to the day they say they have started eating fish.
Design a memory evaluation. You are handed two support agents and told one has “better memory.” Using the dimensions from Section 11.10 (recall, update correctness, abstention, scope enforcement, cost), design three test cases that would reveal which agent is actually better, and explain why a larger context window alone would not settle the question.
[1]
G. Wang et al., “Voyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023.
[2]
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in neural information processing systems (NeurIPS), 2023.
[3]
Y. Hu et al., “Memory in the age of AI agents,”arXiv preprint arXiv:2512.13564, 2025, Available: https://arxiv.org/abs/2512.13564
[4]
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in neural information processing systems (NeurIPS), 2020.
[5]
C. Packer et al., “MemGPT: Towards LLMs as operating systems,”arXiv preprint arXiv:2310.08560, 2023, Available: https://arxiv.org/abs/2310.08560
[6]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in ACM symposium on user interface software and technology (UIST), 2023.
[7]
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y. Wang, “MemoryBank: Enhancing large language models with long-term memory,”arXiv preprint arXiv:2305.10250, 2023, Available: https://arxiv.org/abs/2305.10250
[8]
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building production-ready AI agents with scalable long-term memory,”arXiv preprint arXiv:2504.19413, 2025, Available: https://arxiv.org/abs/2504.19413
[9]
D. Wu, H. Wang, W. Yu, Y. Zhang, K.-W. Chang, and D. Yu, “LongMemEval: Benchmarking chat assistants on long-term interactive memory,” in International conference on learning representations (ICLR), 2025. Available: https://arxiv.org/abs/2410.10813
[10]
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y. Fang, “Evaluating very long-term conversational memory of LLM agents,”arXiv preprint arXiv:2402.17753, 2024, Available: https://arxiv.org/abs/2402.17753
[11]
H. Tan, Z. Zhang, C. Ma, X. Chen, Q. Dai, and Z. Dong, “MemBench: Towards more comprehensive evaluation on the memory of LLM-based agents,” in Findings of the association for computational linguistics: ACL 2025, 2025, pp. 19336–19352. Available: https://aclanthology.org/2025.findings-acl.989/
[12]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y. Zhang, “A-MEM: Agentic memory for LLM agents,” in Advances in neural information processing systems (NeurIPS), 2025. Available: https://arxiv.org/abs/2502.12110