5 LLMs as Reasoners
“The limits of my language mean the limits of my world.”
— Ludwig Wittgenstein, Tractatus Logico-Philosophicus
After this chapter you will understand what turns a next-word predictor into a usable reasoning engine for an agent: what it does well, where it quietly breaks, and why almost every design choice in the rest of the book is a response to those limits.
5.1 Opening intuition
Part I left us with a picture and a promise. The picture was the agent loop from Chapter 1: sense the world, decide what to do, act, and repeat. The promise, made at the close of Chapter 4, was that Part II would open up the box labelled decide and look at the engine we actually put inside it today, the large language model. This chapter keeps that promise. Before you can reason about tools, memory, or planning, you have to understand the strange little machine at the center of it all, because everything else in the book is built to work around its particular strengths and weaknesses.
And it really is strange, when you stop to think about it. A large language model is trained to do one almost comically simple thing: given a stretch of text, predict the next word. That’s the whole objective. It is autocomplete, the same idea as the grey suggestion your phone offers when you type “running a little” and it guesses “late.” Nobody sat down and programmed it with the rules of arithmetic, the plot of Hamlet, or how to read a Python stack trace. It was simply shown an enormous amount of text and asked, over and over, billions of times: what word comes next?
Here is the puzzle that should nag at you. That humble training objective somehow produces a system that can draft a contract clause, walk step by step through a math problem, translate between languages nobody explicitly paired up for it, and decide which tool to call in the middle of an agent loop. How on earth does “guess the next word” turn into something that looks, at least from the outside, like thinking? Answering that question is the whole job of this chapter, and the answer matters, because it tells us exactly how far we can trust the result before we start handing this engine real work to do.
That trust question is not academic. In Part I an agent could afford to be a little abstract, but from here on we are building something that will take actions in the world on its own. If the engine at its center is brilliant in some ways and quietly unreliable in others, then knowing precisely which is which is the difference between an agent you can deploy and one that will embarrass you at the worst possible moment. So we will spend this chapter getting honest about both.
5.2 From guessing words to modeling the world
Let’s start by dissolving the magic trick, because once you see how “guess the next word” becomes “reason about the world,” it stops feeling like sorcery and starts feeling almost inevitable. The key insight is this: predicting the next word well is not a shallow task. Done to a high enough standard, it quietly forces the model to learn an enormous amount about the world that produced the words.
Picture a mystery novel whose very last sentence reads: “The detective gathered everyone in the drawing room, paused for effect, and announced that the murderer was none other than ___.” Now try to fill in that blank with the correct name. You cannot do it from grammar alone. To get it right you must have followed the whole plot, kept track of who had a motive, remembered who was standing where when the clock struck nine, and absorbed how detective stories tend to resolve. That single missing word sits at the tip of an enormous iceberg of understanding. A system trained to predict that word (not just any plausible word, but the right one, across millions of stories, arguments, and explanations) is under constant pressure to build the iceberg underneath. Language is a compressed encoding of human thought and the world it describes, and to predict language well you are quietly forced to decompress a good deal of that world back out. That is why a “mere” next-word predictor ends up knowing things.
Pressure alone, though, is not the whole story. Three specific ingredients turned that pressure into the genuinely capable models we build on today, and each one is worth meeting on its own.
The first ingredient is simply scale: more data, more parameters, more computation. As researchers trained larger and larger models, they noticed something more interesting than a smooth improvement. Certain abilities were essentially absent in small models and then, past some size, began to appear: multi-step arithmetic, answering questions that require chaining several facts together, and more. These jumps were striking enough to earn a name, emergent abilities [1]. Researchers still argue about how sharp and sudden the jumps truly are, and you should hold the strong version of the claim loosely, but the uncontroversial core is what matters here: make a next-word predictor large enough, and feed it enough text, and it crosses into territory it was never explicitly taught to reach.
The second ingredient is in-context learning, and it is the quiet superpower behind almost everything we will do with agents. A large model can pick up a brand-new task from just a handful of examples placed in its prompt: no retraining, no new weights, nothing but a few demonstrations [2]. Show it two or three lines of the pattern you want (“English: hello → French: bonjour; English: thanks → French: merci”) and it will happily continue the pattern for a word you never showed it. Think of it as a sharp new hire on their first morning: you don’t send them back to school, you just show them a couple of worked examples and they infer the shape of the job. This is precisely why so much of the craft of working with LLMs lives in what you put in the prompt rather than in retraining anything.
The third ingredient is instruction following, and it is what turned these models from things you had to trick into things you can simply talk to. A raw pretrained model is a pure continuer of text: hand it “Write a poem about the sea” and it might unhelpfully continue with “…and three other poems for a children’s anthology,” because that is a plausible way for such a sentence to continue somewhere on the web. Researchers closed this gap by fine-tuning the model on examples of instructions paired with good responses, then using human preferences to reward the more helpful answers, a recipe known as reinforcement learning from human feedback [3]. The payoff is a model that treats your prompt as a request to fulfil rather than a string to extend. Figure 5.1 lays out all three stages in order.
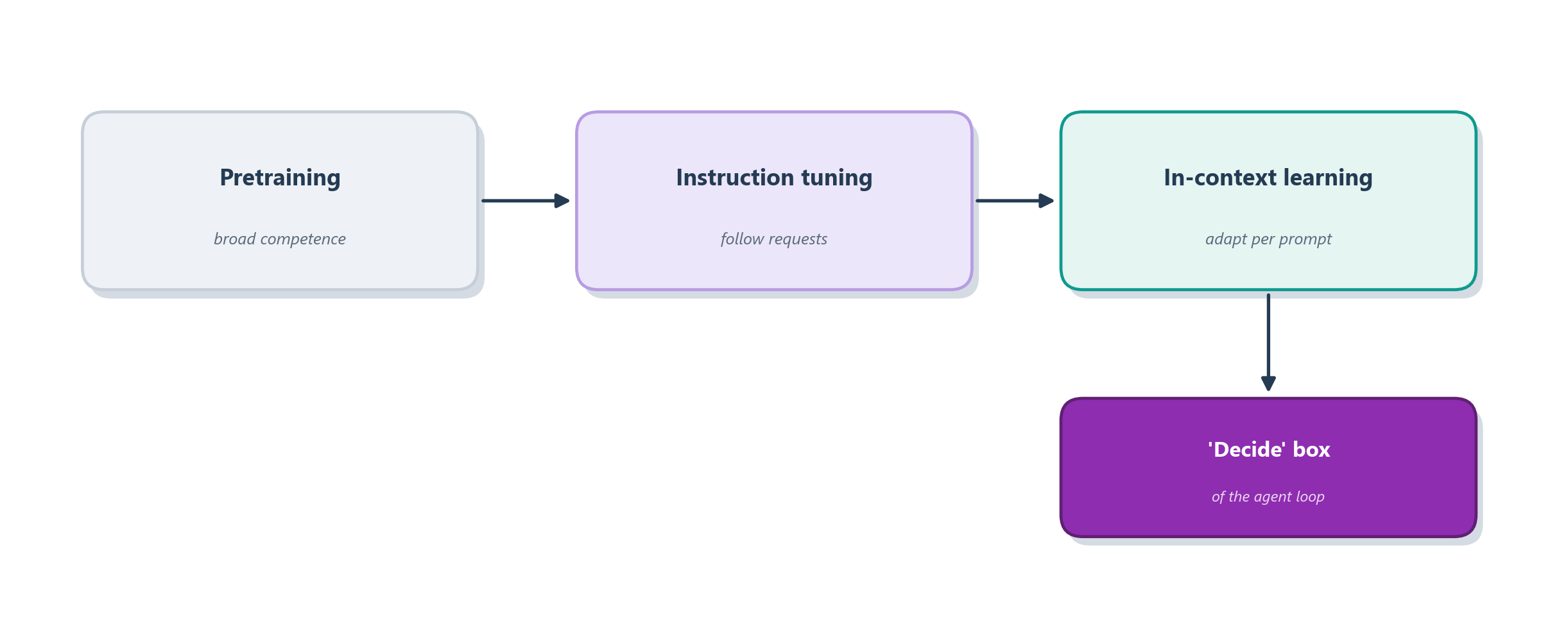
Put the three together and the mystery genuinely dissolves. A model pressured to predict text learns a rich, implicit picture of the world; scale sharpens that picture; instruction tuning aims it at your goals; and in-context learning lets you steer it, task by task, without ever touching its weights. That is the engine we are about to drop into the decide box of the agent loop, and now we can ask what it is like to actually reason with it.
5.3 Thinking out loud
Knowing how the engine came to be is one thing; getting it to reason reliably is another, and it turns out there is a single technique that matters more than any other. Better still, it falls straight out of the way the model works, so it will deepen your intuition rather than add a new mystery.
Picture a bright student who is asked a tricky word problem and forced to answer instantly, with no pause, no paper, just the very first thing out of their mouth. They’ll stumble more often than not, not because they’re incapable, but because they never got the chance to work it through. Now hand the same student a scratchpad and say the four magic words: “show your work.” Suddenly they’re far more reliable, because each line they write down sets up the next, and a single hard leap becomes a staircase of small, safe steps. Large language models behave in almost exactly the same way, and the technique that takes advantage of it is called chain-of-thought prompting: rather than asking for the answer straight away, you invite the model to reason step by step before it commits to one [4].
Why would writing the steps out help a machine, though? The answer is the most important idea in this section, and it comes directly from how generation works. Every word the model produces is immediately fed back in as part of the context for the word that follows. So when the model writes “First, there are 3 boxes with 4 apples each, which makes 12 apples,” those words become scratch paper it can now read back. The reasoning is not happening somewhere hidden and then getting summarized for us; the writing quite literally is the thinking, spelled out one token at a time in the open, each step handing the next step a concrete foothold instead of a guess. Figure 5.2 shows the difference between blurting an answer and working it out.
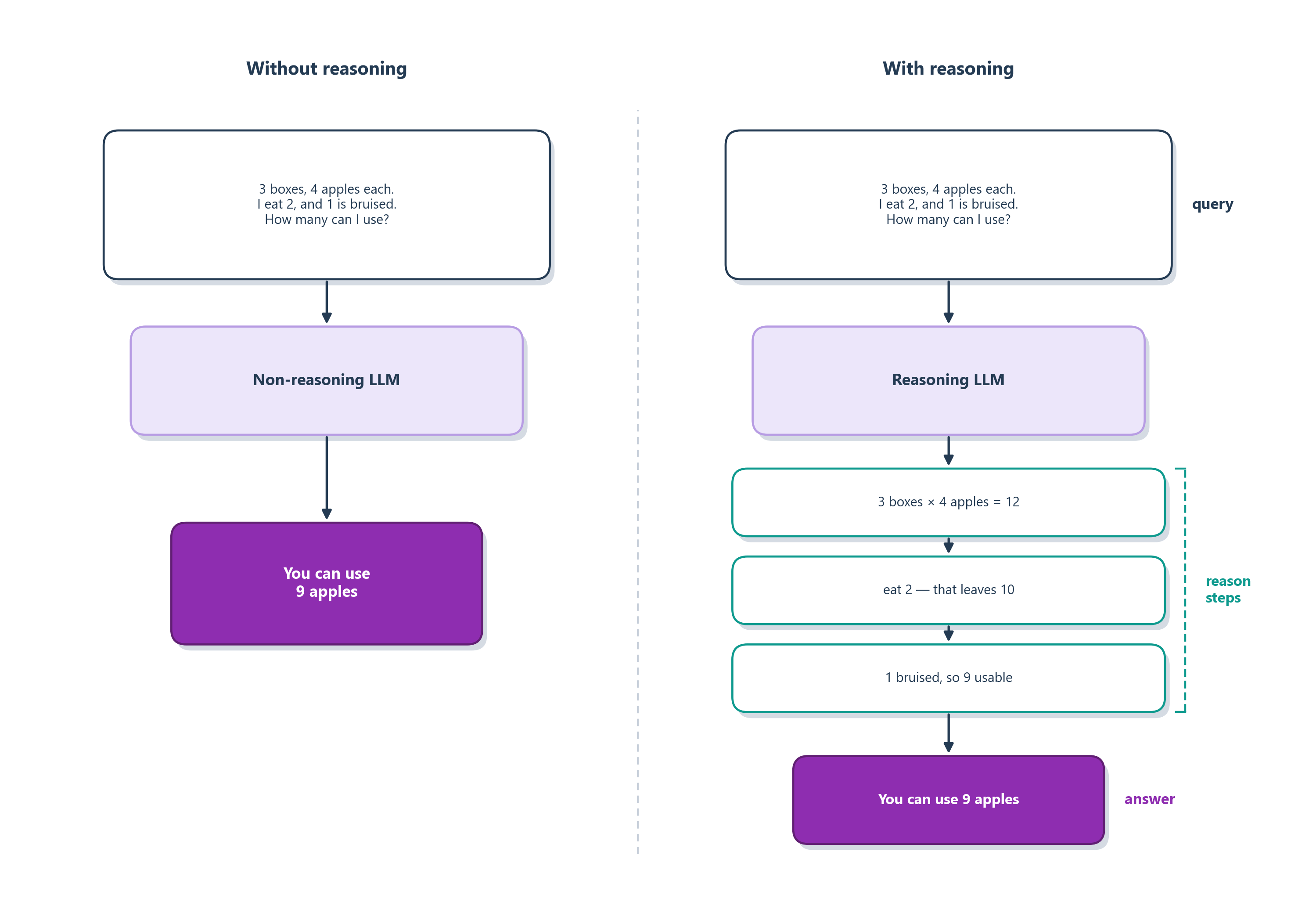
What’s striking is how little it takes to switch this on. Researchers found that simply appending the phrase “Let’s think step by step” to a question measurably improved a model’s performance on math and logic problems, with no worked examples, no fine-tuning, just an invitation to slow down [5]. And there’s a sturdier cousin of the trick worth knowing about, because agents will lean on it later. Instead of trusting a single chain of reasoning, you can have the model generate several independent chains and then keep the answer they most agree on. It’s the same instinct as asking three students to solve a problem separately and going with the majority verdict; a lone chain might wander off, but three chains rarely wander off in the same wrong direction. This technique is called self-consistency [6].
Chain-of-thought is the raw material for a great deal of what follows, so it is worth being just as clear about what it is not before we lean on it. The next two subsections do exactly that: first a caution about how much the written trace really tells you, then a quick map of the richer shapes reasoning can take once one straight line is not enough.
5.3.1 Chain of thought is a scaffold, not proof
There is a tempting mistake hiding inside everything we just praised. Because the model writes its reasoning out in plain, orderly steps, it is natural to read that trace as a confession: this is how the model actually reached its answer, laid bare for you to inspect. Treat it that way and you will eventually be burned, because the written chain is a scaffold that helps the model think, not a faithful record of what happened inside it.
Picture a student who quietly settles on an answer the moment they read the question, then fills in tidy working backwards to justify the number they already liked. The working looks like a derivation. It is really a rationalization, assembled after the fact to look convincing. Large language models do the same thing more often than their fluent prose suggests. Researchers have shown that a model’s stated reasoning can be unfaithful: it can reach the right answer for a reason it never writes down, or write down a reason that is not what actually drove the answer, and this happens even on ordinary, naturally worded prompts rather than only on trick questions designed to mislead it [7]. Follow-up work on dedicated reasoning models found the same gap: when a hint in the prompt secretly steered the answer, the models usually did not mention the hint in their chain of thought at all, so the visible reasoning quietly hid the thing that most influenced the result [8].
Chain-of-thought is genuinely useful and worth using, but keep four limits in view:
- It often improves the answer, by giving the model a scratch pad to work on.
- It often aids inspection, by making the model’s apparent steps visible to read.
- It is incomplete: the real computation happens in the weights, and the words are a lossy shadow of it.
- It can rationalize: the trace may be a plausible story invented to fit an answer the model had already reached, so a coherent chain is not proof that the reasoning is sound.
For an agent, the practical consequence is sharp. Do not treat the model’s narration as your audit trail. The trail that actually holds up under scrutiny is the record of what the agent did: which policy document it retrieved, which tool it called, with what arguments, what result came back, and whether a human approved the action before it ran. That record, unlike the narration, cannot be quietly rewritten to sound convincing. It is a major reason Chapter 16 later insists on logging every step.
This is also why checking only the final answer is not enough. A useful distinction from the research on training reliable reasoners is between outcome supervision, which judges only whether the last number is right, and process supervision, which checks each intermediate step; the latter turns out to produce markedly more reliable reasoning because it catches the flawed steps that a lucky final answer would otherwise hide [9]. Carry that lesson into agent design. Imagine Ledgerly, the billing-support agent whose task we specified back in Section 4.6, denies a refund, and the denial happens to be correct. If it reached that decision by actually reading the refund policy and the invoice, the process was sound. If it simply guessed and got lucky, the process was broken, and the next customer with a slightly different case will get a wrong answer delivered with the same confidence. A right answer from a bad process is a bug that has not surfaced yet.
5.3.2 More than one path
A single chain of thought commits to one line of reasoning and rides it to the end. That is often enough, but when a problem is hard or the first idea might be wrong, you want the model to consider more than one path. It helps to see the options as a small ladder of shapes, which researchers call reasoning topologies [10], and Figure 5.3 lays out the three that matter here.
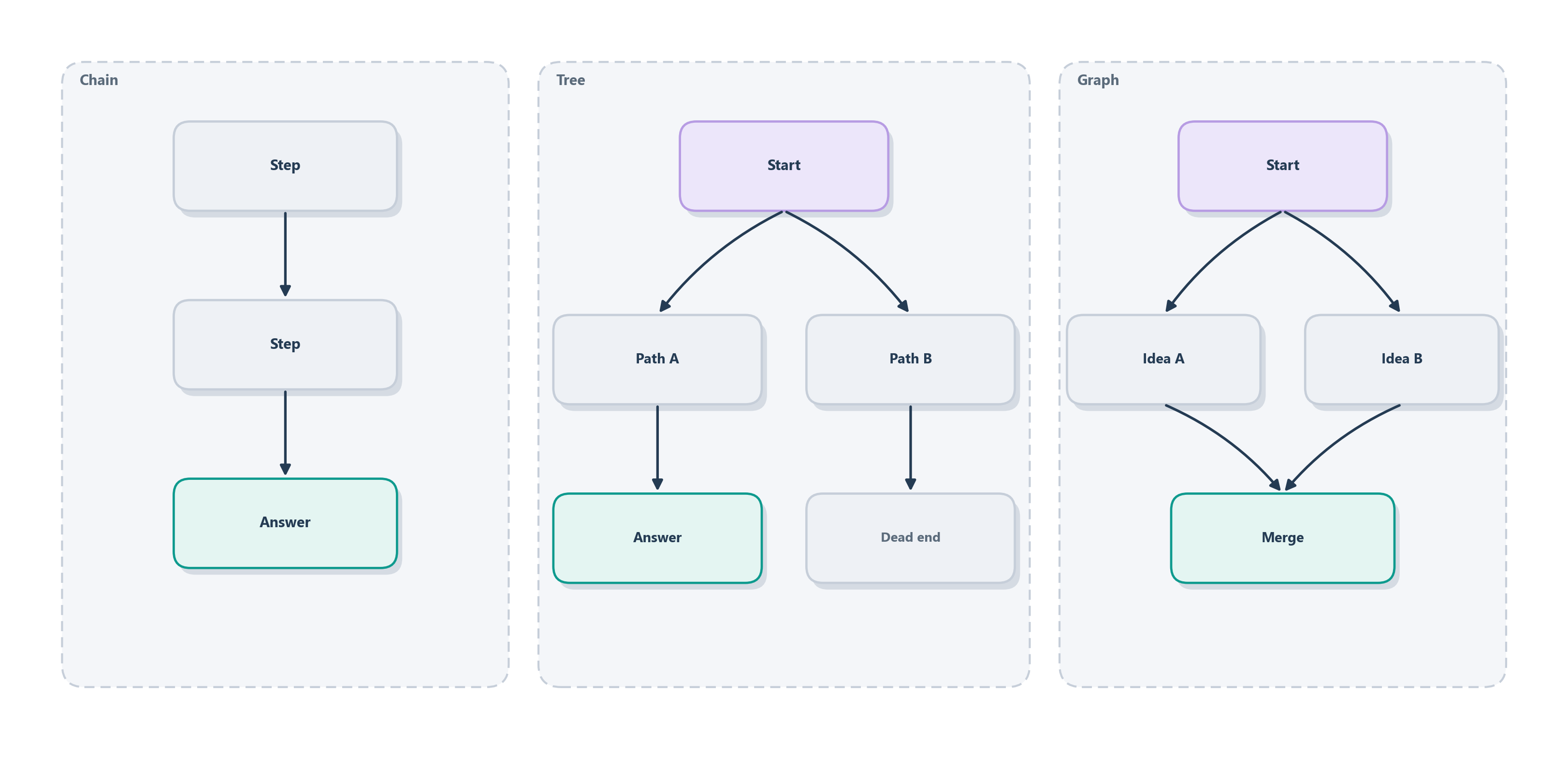
The plainest shape is a direct answer, no visible reasoning at all. Add a scratch pad and you get a chain. Sample several chains and vote and you get self-consistency, which we already met. Let the model branch, explore competing lines, and abandon the ones that go nowhere, and you have a tree; let those lines rejoin and reinforce one another and you have a graph. Each step up the ladder buys the ability to recover from a wrong turn, at the cost of more computation.
One caution travels with this idea, because it is easy to assume that simply generating more paths must be better. It is not, if the extra paths are bad. When several reasoning paths disagree, blindly taking a majority vote lets confident-but-wrong paths outvote a correct one, so the useful move is to validate paths before aggregating them, keeping a path’s conclusion only when its reasoning actually holds up. Adding such a validation step on top of tree-style reasoning has been shown to raise accuracy on grade-school math problems over plain tree search across several models [11]. The lesson to carry forward is that quantity of reasoning is not quality; bad paths must be filtered, not merely counted.
We will not go further here, because branching, searching, and self-correction are the whole subject of Chapter 7, where ReAct, Tree of Thoughts, and reflection loops each turn one of these shapes into a working strategy. For this chapter, the point is only to know the shapes exist and to remember the caution: an LLM reasons best when you let it think out loud, and it reasons more reliably when you give its thoughts room to branch and a way to be checked.
5.4 What LLMs are genuinely good at
Now that we understand how the engine works, we can be precise about where it excels, and being precise matters, because these strengths are not a grab-bag of neat tricks. They are the exact capabilities that make the whole idea of an LLM agent possible in the first place. Take any one of them away and the agents in this book would not work.
5.4.1 Reasoning is not one thing
Before we list what the model is good at, we have to retire a lazy habit of speech. People say “the model can reason” or “the model can’t reason” as if reasoning were a single dial turned up or down. It is not. Think of a brilliant novelist who can hold a thousand-page plot in their head and turn a phrase that gives you chills, yet cannot be trusted to split a restaurant bill three ways without a calculator. The eloquence and the arithmetic are simply different faculties, and being world-class at one tells you almost nothing about the other. Language models are the same. A model can be a fluent essayist and a shaky accountant at the same time, strong at reasoning that lives in words and weak at reasoning that demands exact symbol manipulation. Worse for an agent builder, it can explain a plan beautifully and then choose a poor next action, because narrating a good plan and selecting a good move are, once again, not the same skill.
It helps to name the different kinds of reasoning an agent actually leans on, because each one fails in its own characteristic way. Table 5.1 lays them out against Ledgerly’s support setting, so you can see where the same model might shine and stumble within a single ticket.
| Kind of reasoning | What it asks | A billing-support example | How it characteristically fails |
|---|---|---|---|
| Linguistic | What does this text mean? | Read “I keep getting dinged twice since I upgraded” as duplicate charges after a plan change. | Over-reads tone or misjudges the real intent behind the words. |
| Mathematical | What is the number? | Compute the prorated refund across a partial billing period. | Brittle arithmetic: the right method, the wrong total. |
| Logical | What follows from the rules? | If refunds are allowed only within 30 days and this charge is 45 days old, deny it. | Invalid deductions, or knowing a fact one direction but not its reverse. |
| Causal | What made this happen? | Decide the second charge was caused by the plan switch, not a separate purchase. | Mistakes two charges landing close together for one causing the other. |
| Counterfactual | What if things had differed? | Answer “would I still have been billed if I had cancelled on the 1st?” | Answers confidently without the records that would actually settle it. |
| Planning | What should I do next? | Sequence the work: look up the invoice, check policy, confirm, then refund. | A correct explanation paired with a wrong or out-of-order action. |
| Social / multi-actor | How will the other party react? | Read a frustrated customer, stay calm, and know when to escalate. | Placates by promising a refund the policy does not allow. |
Keep this table in the back of your mind for the rest of the chapter. When we reach the failure modes, you will notice that they cluster on the right-hand columns of exactly this table: the model’s linguistic and social reasoning are usually its strong suit, while its mathematical, logical, and causal reasoning are where the quiet cracks appear.
5.4.2 Four capabilities agents are built on
With that landscape in view, here are the four capabilities the rest of this book leans on hardest. They are not the whole of what a model can do, but they are the ones that turn a text predictor into something you can build an agent around.
The first and most far-reaching strength is in-context learning, which we met earlier as the ability to absorb a task from a few examples in the prompt. What’s worth appreciating now is how much leverage this gives an agent builder. Because you can teach the model a new job without touching its weights, a single underlying model can play a dozen different roles in one system (classifying a ticket in one call, extracting dates from a contract in the next, rewriting a paragraph in a friendlier tone in a third) with nothing changing but the instructions you hand it. That flexibility is what lets a small team build something that would once have required a dozen separate, specially trained models.
The second strength is following instructions written in plain language. You don’t have to encode your intent in a rigid schema, a config file, or a special syntax; you can more or less ask for what you want the way you’d ask a colleague. This is easy to take for granted, but it is precisely what lets an agent accept a messy, very human goal, “figure out why this customer keeps getting billed twice,” and actually make headway, instead of demanding the request be pre-chewed into some machine-shaped form first.
The third strength is the one the rest of the book leans on hardest: the knack for mapping fuzzy language onto concrete actions. Give a capable model a goal and a menu of tools described in words, and it can usually pick a sensible tool and fill in its arguments, reading “email me a copy of invoice #4471” and deciding to call get_invoice with invoice_id = "4471". That single ability, turning an intention into a well-formed action, is the hinge the entire field of LLM agents swings on, and we will spend much of Part III sharpening it into something dependable.
The fourth strength is sheer breadth of knowledge. Having digested a vast sweep of text, one model can hold a passable conversation about tax rules, Python decorators, and medieval trade routes, which means an agent doesn’t need a hand-built knowledge base for every domain it might wander into. This breadth is genuinely useful, but notice that it is also a temptation. It invites you to trust the model’s memory, and that trust, as the next section shows, is exactly where things start to go wrong.
5.5 Where they quietly break
Everything so far might tempt you to treat an LLM as a reliable reasoning oracle. It is not, and understanding precisely how it fails is more valuable than being impressed by how it succeeds. The reason is the agent loop itself: a single confident mistake early in a loop becomes the input to every later step, so a small error at the start can snowball into a completely wrong outcome by the end. What makes this especially treacherous is that all four of the failures below share one root cause, the very thing we started the chapter with: the model was trained to produce plausible text, not true statements. Figure 5.4 gathers them under that common root.
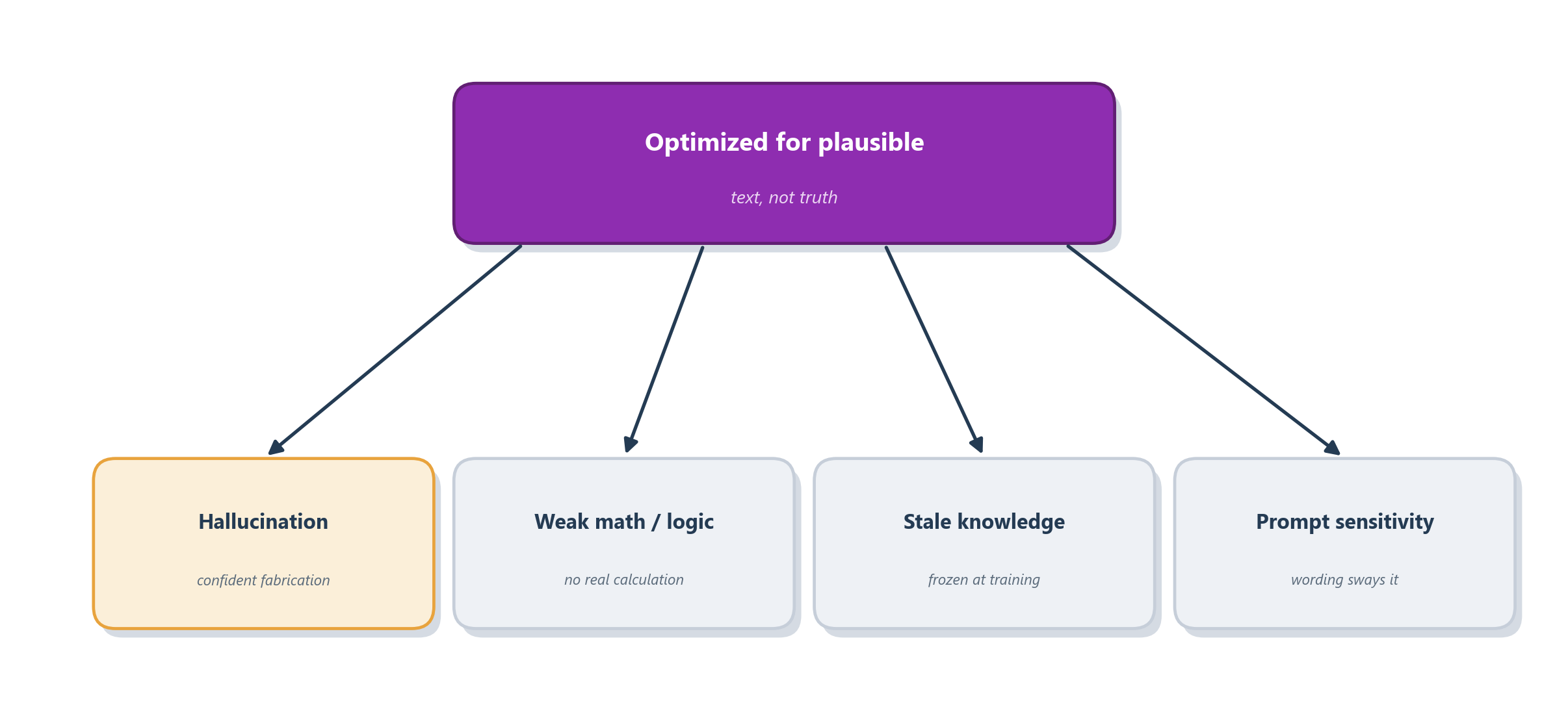
The most notorious failure is hallucination: the model states something false with exactly the same fluent confidence it uses for the truth [12]. Ask it for a supporting citation and it may hand you a plausible-looking paper (believable authors, a sensible title, a reasonable year) that simply does not exist. The reason is baked right into the objective. To the model, a fluent fabrication and a fluent fact look equally like “text that could plausibly come next,” and nothing in its training cleanly teaches it to tell them apart. It is, in effect, a student who never learned to say “I don’t know,” and who will always prefer a confident guess to an honest blank.
The second failure hides behind the first, which is what makes it so dangerous: arithmetic and logic are brittle, even when the model appears to reason beautifully. A revealing study built a math benchmark whose problems could be regenerated with different numbers, or with an extra, irrelevant sentence dropped in. Two findings stand out. First, a model’s accuracy wobbled merely from changing the numbers in an otherwise identical problem. Second, and more damning, inserting a single clause that looked relevant but added nothing to the actual solution dropped performance by as much as 65% across every state-of-the-art model tested [13]. The authors’ reading of this is sobering: much of the time the models are not reasoning through a problem so much as pattern-matching it against similar problems seen in training. Shift the surface pattern and the “reasoning” shifts right along with it, which is precisely what you do not want from something you’re about to trust with a multi-step task.
A vivid illustration of that same brittleness is so oddly specific that it’s almost funny, yet it reveals how alien the model’s grasp of a “fact” can be. Tell a model that “A is B” and it will frequently fail to conclude that “B is A”, a quirk researchers named the reversal curse. In one test, GPT-4 could answer “Who is Tom Cruise’s mother?” correctly about 79% of the time, but when the very same fact was probed in reverse, “Who is Mary Lee Pfeiffer’s son?”, it succeeded only around 33% of the time, even though the two questions are logically identical [14]. A person who knows one direction automatically knows the other; the model, it turns out, often learned a one-way word association rather than a symmetric fact about the world. It is a sharp reminder that “knowing” something, for an LLM, is not what it is for us.
The third failure matters enormously the moment your agent starts stuffing long documents and long histories into the prompt: models have context blind spots. You might assume that as long as the crucial fact is somewhere in the input, the model will find and use it. Not so. When researchers hid a needed piece of information at different positions in a long context, models used it reliably when it sat near the beginning or the end, but their accuracy sagged noticeably when the fact was buried in the middle, a U-shaped pattern the authors memorably dubbed being “lost in the middle” [15]. The lesson is one to tattoo on the back of your hand: a longer context window is not the same thing as a longer attention span.
Underlying much of the above is a fourth, more diffuse fragility: LLMs are sensitive to how you ask. The same question, reworded, reordered, or with its examples shuffled, can produce a different answer. This is the reason “prompt engineering” became a discipline at all, and the reason you should be quietly suspicious of any agent whose success rests on one perfectly phrased, magical prompt. If a small change in wording breaks it, it was never truly reasoning; it was reciting, and reciting is brittle.
It is worth seeing these four as faces of one underlying fragility rather than a list to memorize. Distractor sensitivity (a model thrown off by an irrelevant clause), an unfaithful or shortcut rationale (a tidy explanation that is not what drove the answer, as we saw in Section 5.3.1), step-error propagation (one wrong step early quietly poisoning every step after it), plain overconfidence, and poor abstention (pressing ahead instead of admitting it does not know) are all the same coin seen from different angles. Each one traces back to a system optimized to produce text that looks right rather than text that is right, which is exactly why none of them announce themselves.
Notice that none of these failures announce themselves. The model does not hedge, stammer, or flag its own uncertainty; a hallucinated citation and a brittle miscalculation arrive wrapped in the same calm, authoritative prose as a correct answer. In an autonomous agent that acts on its own conclusions, that quiet confidence is exactly what makes these failures hazardous: an agent cannot route around a mistake it does not know it made. This is why the verification and grounding techniques in the next section are not optional polish; they are structural necessities.
5.5.1 How to test whether it is really reasoning
The GSM-Symbolic result gives us more than a warning; it hands us a method. If a model is genuinely reasoning, its conclusion should move only when the underlying facts move, and stay put when you merely change the wording. If instead the answer swings around as you rephrase the question, you are watching pattern-matching wearing the costume of reasoning. So before you trust a model on a class of task, poke it the way a good teacher probes a student who might be reciting rather than understanding: keep the substance fixed and vary the surface, then keep the surface fixed and vary the substance, and watch which way the answer follows.
Here is a practical perturbation checklist you can run against any reasoning step an agent depends on. Change the names. Change the numbers. Reorder the facts. Add an irrelevant clause that sounds related but changes nothing. Add a contradictory detail and see whether the model notices. Remove a fact the answer actually requires and see whether the model invents it or asks for it. Reverse the relationship (the reversal-curse test). Reword the whole thing in a different register. Run the same prompt several times, because a stable reasoner should not flip its verdict from one sample to the next. And inspect the intermediate steps, not only the final answer, since a right answer reached by a broken step is the very bug Section 5.3.1 warned about.
The rule underneath all of these is a single sentence worth memorizing: the conclusion should change only when the facts change, not when the wording changes. Ledgerly makes it concrete. “I was charged twice,” “there are two debits on my card,” and “I got two invoices right after I switched plans” are three surface forms of what may be the same underlying situation. If the account’s records are equivalent in each case, a reasoning agent should reach the same conclusion for all three; if it clears the charge under one phrasing and escalates under another, its judgment is riding on wording, not facts, and it is not ready to act unsupervised. This is precisely the kind of stability that Chapter 15 turns into a repeatable test suite, so that “does it really reason here?” becomes a number you can track rather than a hunch.
5.6 What this means for building agents
Here is the reframing that will carry you through the rest of the book. Once you stop seeing that list of failures as a disappointment and start seeing it as a specification, the whole architecture of an agent snaps into focus. Almost every technique in the chapters ahead exists for one reason: to shore up a specific weakness we just named. The raw model is the engine; the agent is the whole car built around it: the brakes, the mirrors, and the seatbelts that make the engine safe to actually drive. Broadly, those safety systems come in three families, and Figure 5.5 lines each one up against the weakness it is there to answer.
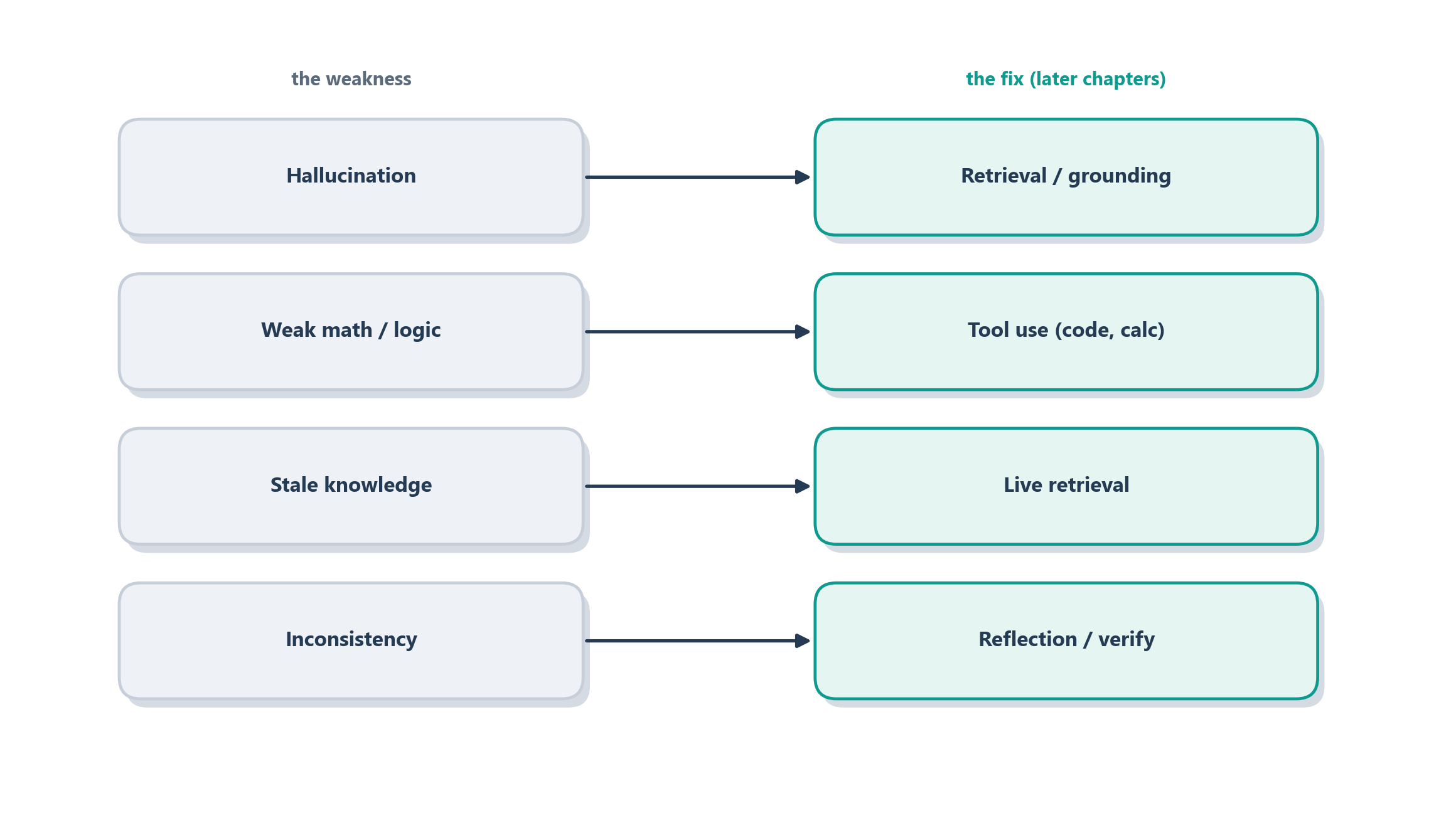
The first move is to ground the model, to stop it from relying on its own fallible memory and instead give it a real source of truth. Rather than asking the model what the weather is, you hand it a weather tool and let it read the live answer; rather than trusting it to recall a company’s refund policy, you retrieve the actual policy document and place it in the context. This is the whole idea behind giving models tools [16], retrieving relevant documents before answering [17], and interleaving reasoning with real actions the way the ReAct pattern does [18]. Grounding attacks hallucination and stale knowledge at the root: a model that can look things up has far less need to make things up.
The second move is to verify rather than trust a single pass. Because a lone answer can be confidently wrong, you build in a check. Sometimes that means sampling several reasoning paths and taking the answer they agree on, which is exactly the self-consistency idea from earlier in this chapter [6]. Sometimes it means letting the agent critique its own output, notice a flaw, and try again, the reflection loop we will meet in Chapter 7. Either way the principle is the same as asking a colleague to double-check a number before you send it to the CEO: a second look is cheap, and it catches the brittle mistakes a first pass sails right past.
The third move is the humblest and the most important: keep a human in the loop wherever the cost of a silent error is high. This is the same lesson we drew back in Section 1.7, now with teeth. Because the model’s mistakes are confident and quiet, the design question is never merely “can the agent do this?” but “what happens when it does this wrong, and who catches it?” For a task that drafts a suggestion you will review anyway, full autonomy is fine. For a task that moves money, deletes records, or emails a customer, a checkpoint where a person approves the action is not a lack of ambition, it is the mark of a system designed by someone who understands the engine.
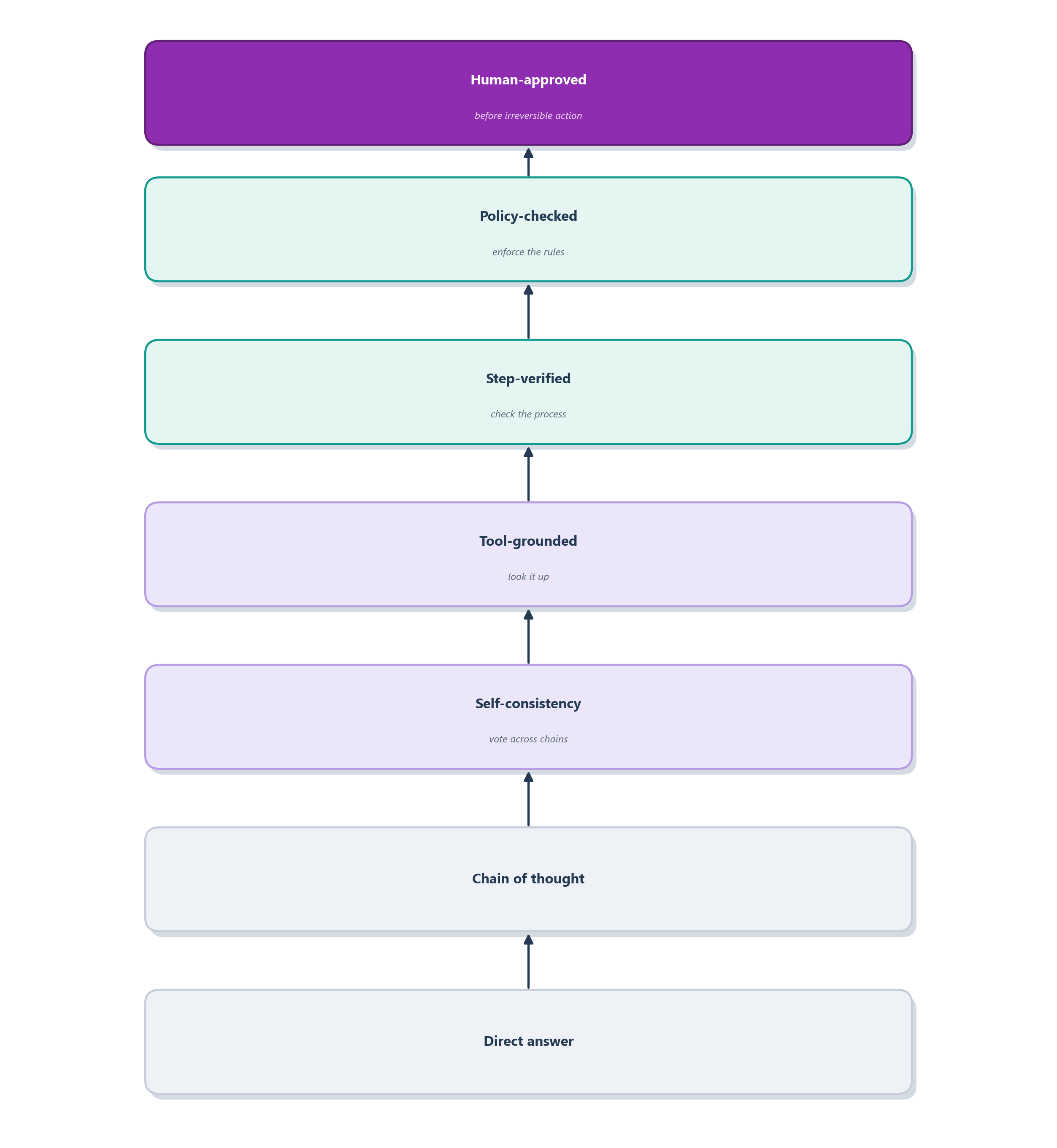
These three moves are not a menu you pick one item from; they stack. Figure 5.6 arranges them as a reliability ladder, from a bare direct answer at the bottom to a human-approved action at the top, with each rung adding a layer of support the rung below it lacks. A direct answer is fine for something trivial. Letting the model think out loud adds a scratch pad; sampling several chains and voting adds a sanity check; grounding the answer in a tool or a retrieved document replaces memory with evidence; verifying the individual steps catches a lucky-but-broken process; checking the result against policy enforces the rules that matter; and, at the top, a human approves before anything irreversible happens. The skill is not to climb as high as possible every time. It is to match the height of the ladder to the cost of being wrong: a low rung for drafting a suggestion, the top rung before moving a customer’s money.
A useful habit when designing any agent is to walk down the failure list and ask, for each one, “how am I covered here?” Where could this agent hallucinate, and have I grounded it? Where could its logic be brittle, and have I added a verification step? Where would a silent mistake be expensive, and is a human watching that spot? An agent is only as trustworthy as its answer to those three questions, and you now know enough to ask them.
5.6.1 Grounding gives evidence, not correctness
It is easy to hear “just ground the model” and assume grounding solves the reliability problem on its own. It does not, and the gap between the two is subtle enough to be worth its own subsection. Grounding fetches evidence. Being correct means using that evidence rightly, and those are separate acts. A detective handed the right case file has not solved the case; they still have to read it correctly, and a file sitting on the desk proves nothing by itself.
All the ways this can go wrong are ordinary, not exotic. Retrieval can fetch the wrong passage, or fetch the right passage that the model then misreads. A tool can return perfectly correct data that the model then uses incorrectly. Two sources can conflict, and the model has to decide which to believe. And the model can simply overlook the single most relevant line in favor of a less relevant one, the lost-in-the-middle failure wearing a new coat. Grounding narrows the space for error, but it does not close it, which is why verification has to be a deliberate, separate step and not a side effect of retrieval.
Ledgerly makes the distinction sharp. Suppose its billing tool truthfully reports two charges on the account. That fact, on its own, does not prove a duplicate. Before the agent can call it one, it has to verify that the two charges are for the same subscription, cover the same period, share the same reason, and trace to the same invoice, and it has to rule out the ordinary explanations: that one is a legitimate one-time adjustment, or that a refund for it was already issued last week. The evidence was grounded the moment the tool returned; the conclusion is earned only after those checks. An agent that skips them is not grounded, it is merely confident with a citation attached.
5.6.2 Reasoning versus planning
There is a distinction humming underneath this whole chapter that we can now name outright, because it draws the exact line between where Chapter 5 ends and the next reasoning chapter begins. Reasoning asks, “what follows from what I know?” Planning asks, “what should I do next?” They sound like the same activity, but they are not, and an agent can be fluent at one while stumbling on the other. A model can produce a flawless explanation of why a customer was double-charged and, in the very same breath, choose a bad next action, issuing the refund before confirming the customer’s identity, say, or escalating a case it could have closed. Getting the account of the world right is not the same as getting the move right.
This chapter has been about the first activity: what kinds of reasoning a model does, how to coax it out, how far to trust it. The second activity, turning reasoning into a sequence of grounded actions with checking and backtracking along the way, is the entire subject of Chapter 7, where patterns like ReAct, Tree of Thoughts, and reflection loops give the model a disciplined way to decide what to do next. Hold the distinction in mind as you cross into that chapter: everything there builds on the reasoning we have described here, but adds the machinery for acting on it well.
5.6.3 A reasoner must know when to abstain
The most underrated skill a reasoner can have is knowing when not to answer. A junior employee who confidently invents a policy rather than admitting they need to check is more dangerous than one who simply asks, and the same is true of an agent. Because an LLM will almost always produce a fluent answer whether or not it has grounds for one, a well-designed agent needs explicit triggers that tell it to stop, ask, or hand off rather than press ahead.
A short list of those triggers covers most real cases. The agent should abstain or escalate when the evidence it needs is missing, when two pieces of evidence conflict, when the customer’s identity or account is ambiguous, when it would have to assert a policy it cannot point to, when a tool returns an error, when the action it is about to take is high-risk or irreversible, when repeated reasoning over the same facts keeps giving inconsistent answers, and when what it is told contradicts what it already has in memory. For Ledgerly the rule is concrete: if the agent cannot pin down which account or which invoice the customer means, the right move is to ask, or to call the lookup tool, never to infer a plausible-looking account and act on it. Knowing when to abstain is not timidity; it is the core of safe agent behavior, and Chapter 17 builds a whole layer of guardrails on exactly this instinct.
5.6.4 When reasoning becomes action
It helps to see all of this land in one place, so let us watch a handful of tickets reach Ledgerly, the support agent whose world we mapped in Section 4.6, and pass through the machinery. Each request calls on a different kind of reasoning from Table 5.1, exposes a different characteristic failure, and therefore needs a different safeguard. Table 5.2 lines them up.
| Customer request | Reasoning needed | Likely failure | Safeguard that catches it |
|---|---|---|---|
| “Why was I charged twice?” | Causal | Calls two nearby charges a duplicate without checking | Invoice lookup plus a duplicate-validation check (same subscription, period, invoice) |
| “I already returned this, where is my refund?” | Logical | Asserts a refund status it never confirmed | Ticket-history plus refund-status lookup before answering |
| “Refund me for last month.” | Planning | Moves money before confirming eligibility | Policy check, then explicit confirmation before any charge is reversed |
| “This is the third time, and I am furious.” | Social / multi-actor | Placates by promising a refund the policy forbids | Stay evidence-based under pressure; escalate rather than over-promise |
| “I only started getting billed after I switched plans.” | Counterfactual / causal | Guesses a cause without the timeline | Plan-history plus charge-timeline lookup to test the claim |
The through-line is that no single ticket is handled by reasoning alone. Each one pairs a reasoning step with a grounding step, a verification step, and, where money moves, a human or policy checkpoint. Figure 5.7 draws the shape that every row of the table really follows: the agent forms hypotheses, gathers evidence to test them, checks the result against policy, validates before it acts, and either takes the grounded action or escalates when the evidence will not support one.
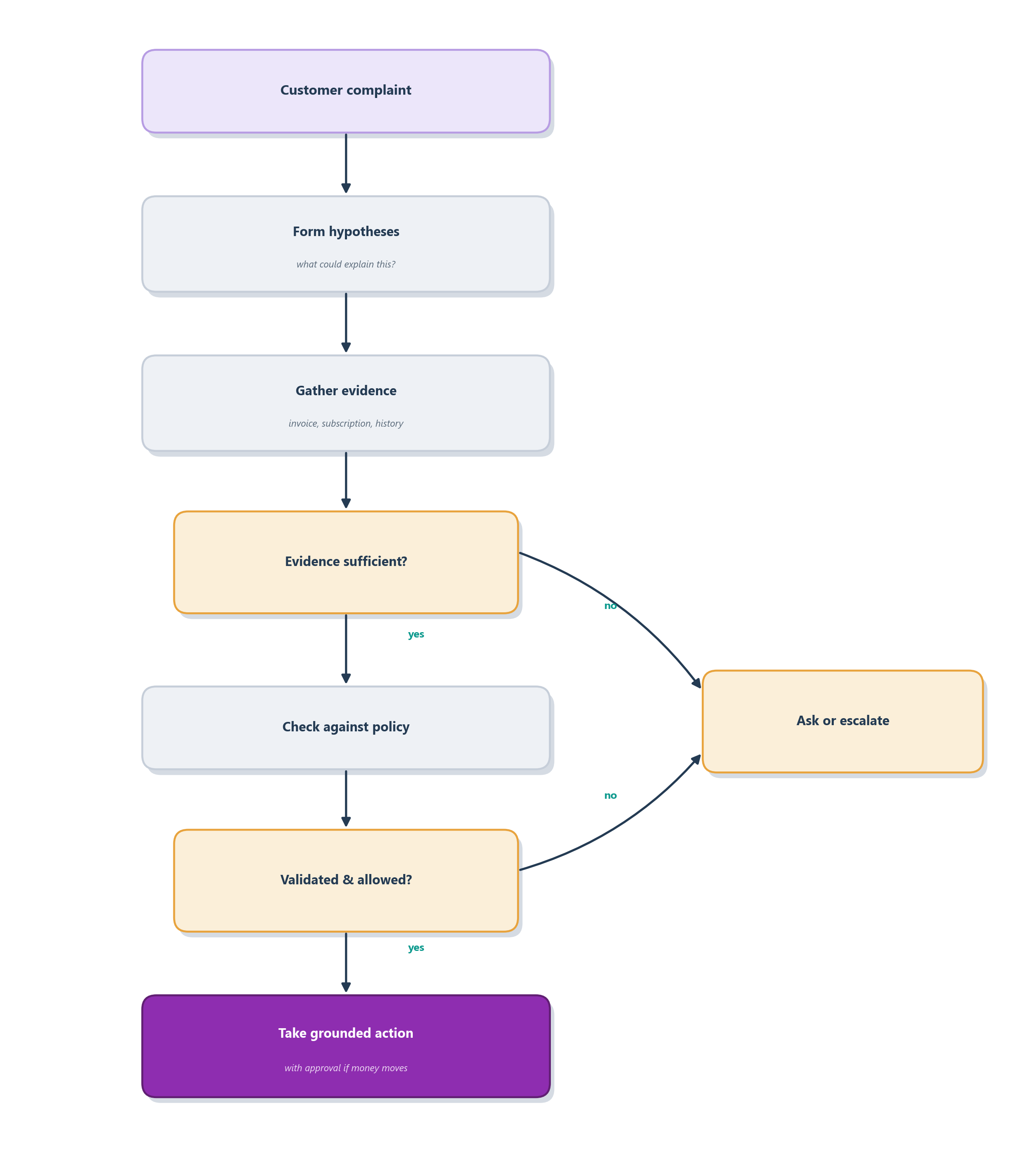
Notice that this small flow already gestures at almost everything the rest of the book will build: the tools that gather evidence (Chapter 6 and the tools chapter), the memory that supplies history, the policies and checks that gate an action, the logging that makes the whole path auditable (Chapter 16), and the human approval that guards irreversible moves (Chapter 17). Chapter 5 is where you learn why each of those exists. The chapters ahead are where you learn to build them.
Seen this way, the failures are not a reason to abandon LLMs; they are the blueprint for everything we build next. The chapters ahead are, in a real sense, a guided tour of these three moves (grounding, verifying, and supervising) applied over and over in richer and richer combinations. The very next chapter starts at the most fundamental of them: taking the bare model and giving it its first real capabilities, turning it into what we will call the augmented LLM in Chapter 6.
5.7 Summary
- An LLM is trained to do one simple thing, predict the next word, yet at scale that objective yields in-context learning, instruction following, and something that looks, from the outside, like reasoning [1], [2].
- Reasoning is not one thing. A model can be a fluent essayist and a shaky accountant at once, strong at linguistic and social reasoning while weak at exact mathematical, logical, and causal reasoning, so “can it reason?” is the wrong question; “which kind, how reliably?” is the right one.
- Chain-of-thought prompting, letting the model think out loud before answering, measurably improves reasoning, because each generated token becomes context that steadies the next one [4], [5]. But the written trace is a scaffold, not proof: it can rationalize an answer after the fact and is not a faithful audit log [7], [8], which is why verifying the process matters and not just the answer [9].
- Every core weakness traces to one root: the model is optimized for plausible text, not true text. This surfaces as hallucination [12], brittle logic and arithmetic [13], context blind spots [15], and prompt sensitivity. You can test for real reasoning by perturbing a task: the conclusion should change only when the facts change, not when the wording does.
- These failures are dangerous precisely because they are confident and silent, so building an agent means climbing a reliability ladder, grounding it (tools + retrieval), verifying its output (self-consistency, step checks, reflection), and keeping a human in the loop where a quiet mistake would be costly. Grounding supplies evidence, not correctness; verification is a separate step.
- Reasoning (“what follows?”) is not planning (“what next?”), and a good reasoner knows when to abstain, asking or escalating rather than guessing when the evidence will not support an answer.
With the engine understood, its power and its cracks, we can start bolting on the parts that make it dependable. Chapter 6 begins that work by giving the bare model its first real reach into the world: tools, retrieval, and memory.
5.8 Exercises
- In your own words, explain the puzzle at the heart of this chapter: how does an objective as simple as “predict the next word” give rise to behavior that resembles reasoning? What does that origin story tell you about how far to trust the result?
- Using Table 5.1, pick one billing ticket and name every kind of reasoning it secretly requires. Where would you expect the same model to be strong, and where would you expect it to be weak, and why does that unevenness matter for an agent?
- Chain-of-thought helps on multi-step problems but adds latency and cost on simple ones. Describe one task where you would not bother with it, and justify the trade-off using the token-feedback explanation from Section 5.3.
- The chapter argues a chain of thought is “a scaffold, not proof” [7]. Explain why a correct final answer reached by a broken process is still a bug, and describe one thing an agent should log so its real audit trail does not depend on the model’s narration.
- Sketch the reliability ladder from Figure 5.6 for two tasks: drafting a suggested reply a human will review, and issuing a refund. How high up the ladder would you climb for each, and what does the cost of being wrong have to do with your choice?
- Design a perturbation test for one reasoning step your agent depends on. List the variations you would apply (names, numbers, an irrelevant clause, a reversal, repeated samples) and state the pass criterion in one sentence.
- Explain the difference between grounding and verification using the double-charge example from Section 5.6.1. Why does a tool returning two charges fail to prove a duplicate, and what extra checks turn evidence into a conclusion?