7 Reasoning & Planning
“Plans are worthless, but planning is everything.”
— Dwight D. Eisenhower
After this chapter you will be able to apply the major reasoning strategies (chain-of-thought, ReAct, reflection, and search-based planning) and choose the right depth of deliberation for the task in front of you.
7.1 Opening intuition
The last chapter ended on a small but pregnant detail. We built the augmented LLM, a model with hands, a book, and a notebook, and in the final sketch we let it do something it had never done before: call a tool, look at the result, and decide what to do next. That tiny while loop was the whole difference between answering a question and working toward a goal. This chapter is about what happens when we take that loop seriously and let the model reason across many steps rather than one.
To feel why this matters, think about how you yourself handle two very different kinds of question. If someone asks you the capital of France, you simply answer; the response is already sitting in your memory and no deliberation is required. But if someone asks you to plan a two-week trip through a country you’ve never visited, on a fixed budget, you do something completely different. You think out loud. You look things up. You sketch a rough plan, notice that it blows the budget, and revise it. You might explore two possible routes before committing to one. The answer is not recalled; it is constructed, step by step, with plenty of checking and backtracking along the way. That second mode, deliberate, multi-step, self-correcting, is exactly what we want to give an agent, and it does not come for free from a model that was trained to produce one fluent response at a time.
The good news is that we do not need to invent this from scratch, because the field has worked out a family of reasoning strategies that coax exactly this behavior out of a language model. They form a natural progression, each one adding a capability the previous one lacked, and the whole chapter is organized around climbing that ladder. First the model learns to think before it answers, laying its reasoning out in a straight line. Then it learns to act as it thinks, interleaving reasoning with real tool calls so its thoughts stay grounded in the world. Then it learns to check its own work, criticizing a first attempt and trying again. And finally it learns to search, exploring several possible lines of reasoning and keeping the best rather than gambling everything on the first path it tries. Figure 7.1 lays out that progression, and it is the map for everything that follows.
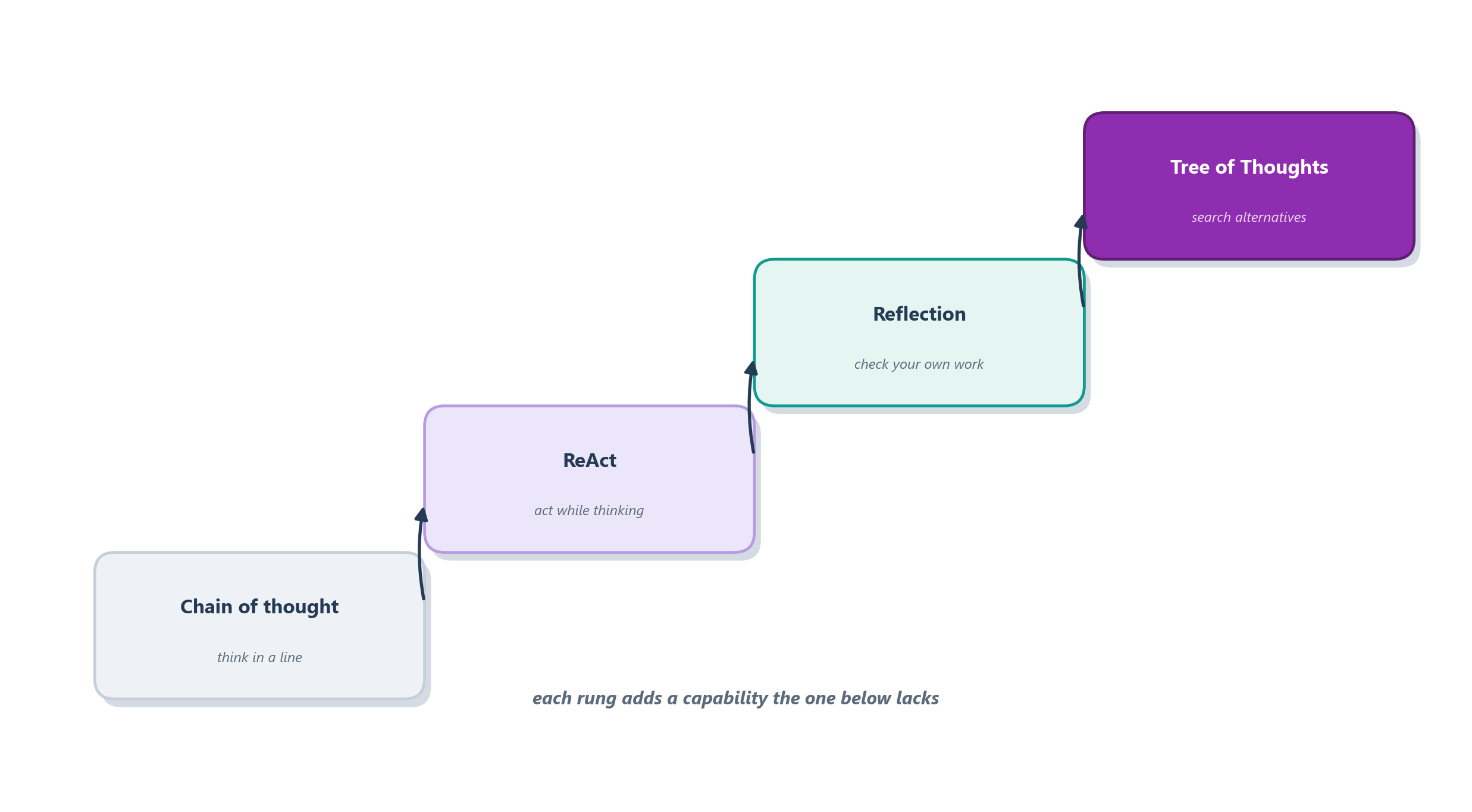
A word of honesty before we climb, because it is the theme the chapter closes on. More reasoning is not automatically better. Each rung up the ladder buys accuracy on harder problems, but it pays for that accuracy in tokens, latency, and cost, and pointing a tree-search at a question a single sentence could answer is simply waste. The real skill is not knowing the fanciest strategy; it is matching the depth of deliberation to the difficulty of the task. We will earn that judgment by understanding each strategy in turn. But before we climb, it pays to separate three jobs the ladder quietly bundles together, because a capable agent does more than think: it also plans and it controls itself.
7.2 Reasoning, planning, and control are different jobs
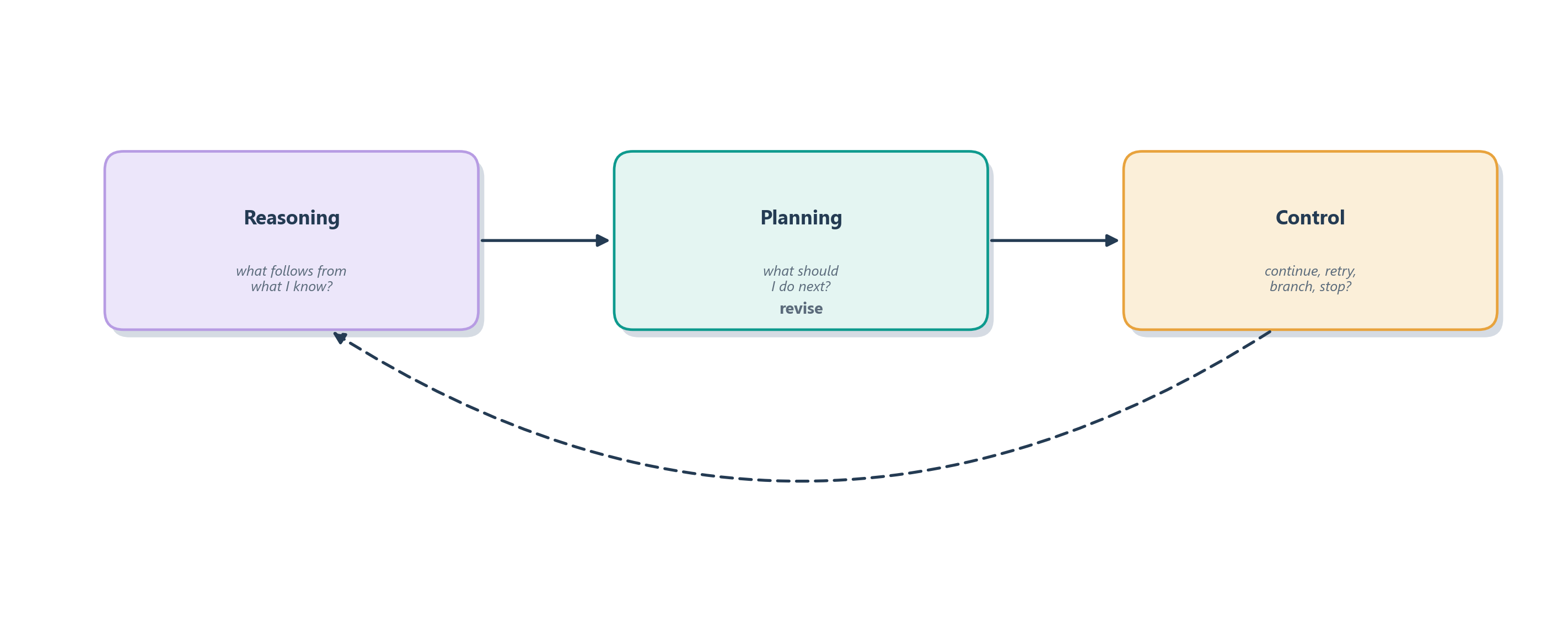
Watch a skilled emergency-room doctor for one shift and you will see three distinct jobs running at once, not one. When she reads a chart and concludes “these symptoms point to sepsis,” she is reasoning: drawing a conclusion from what she already knows. When she decides “so we draw blood, start fluids, and order a scan, in that order,” she is planning: laying out a sequence of actions toward a goal. And when the first result comes back inconclusive and she chooses whether to reorder the test, try a different one, or page a specialist, she is exercising control: deciding, at each moment, whether to continue, retry, branch, stop, or escalate. Every agent worth the name does all three, and keeping them distinct is the key that unlocks the rest of this chapter.
The three jobs answer three different questions, and Figure 7.2 lines them up. Reasoning asks what follows from what I know? Planning asks what should I do next? Control asks should I continue, retry, branch, stop, or escalate? The reasoning ladder we just sketched is really a ladder of better answers to the first question, but a system that only reasons will happily think itself into an elegant dead end, because nothing is choosing its actions or deciding when enough is enough. Planning and control are what turn a thinker into an agent.
Ledgerly makes the split concrete. A customer writes in claiming they were charged twice. Reasoning forms the hypothesis: two charges in one cycle might be a duplicate, or might be a valid proration from a mid-cycle plan change. Planning turns that hypothesis into a sequence of lookups: pull the invoice, check the billing periods, retrieve the plan history, read the current refund policy. Control watches over the whole thing, deciding to retry a billing lookup that times out, to escalate when the records conflict with the policy, and to stop and request human approval before issuing any refund above the agent’s auto-approval threshold. One complaint, handled by all three jobs at once.
This is the sentence to carry through the rest of the chapter: planning is reasoning under control. Reasoning supplies the raw inferences, planning arranges them into a course of action, and control decides, step by step, whether that action is still the right one to be taking. A good agent does not merely think longer than a bad one. It keeps state, acts, observes, revises, checks its progress against the goal, and knows when to stop. Every rung of the ladder we are about to climb, from a single chain of thought to a full tree search, is best understood as a way of doing one or more of these three jobs better. We start where all of them begin: with thinking itself, laid out in a straight line.
7.3 Chain-of-thought: thinking in a straight line
The bottom rung of the ladder is one we have already climbed once, in Section 5.3, so here we only need to recall it and see it in its new role. Chain-of-thought prompting is the simple, powerful move of letting the model reason step by step before it commits to an answer, rather than blurting a conclusion in one leap [1]. We saw why it works: every word the model writes is fed back in as context for the next word, so writing the steps down literally gives the model a scratch pad to think on, turning one hard leap into a staircase of small, safe steps. A model asked to “show its work” is measurably more reliable on arithmetic and logic than one forced to answer instantly, and remarkably, even an invitation as bare as “let’s think step by step” is enough to switch the behavior on [2].
For this chapter, the point is to see chain-of-thought as the foundation the other three strategies are built on, and to be equally clear about what it cannot do. Its power is that it lets the model deliberate; its limits are two, and each one is answered by a rung further up the ladder. First, a chain of thought is still just the model talking to itself; it cannot look anything up or take any action, so every step rests on the model’s own possibly mistaken beliefs, and a wrong fact early in the chain propagates confidently to the end. That is the gap ReAct will close by letting the model act. Second, a chain of thought commits to a single line of reasoning and rides it to the finish; if that line goes wrong, there is no mechanism to notice and no alternative in reserve. Those are the gaps reflection and search will close. Chain-of-thought, in other words, taught the model to think, and the rest of the chapter is about teaching it to think well. The very next step is to notice that a chain is not yet a plan, and to make the plan explicit.
7.4 Plan-and-solve: make the plan explicit
A chain of thought looks like a plan, but it usually is not one, and the difference matters more than it first appears. Chain-of-thought solves while it writes: it starts producing steps toward the answer immediately, discovering the shape of the problem as it goes. That works beautifully for a self-contained puzzle, but it has a characteristic failure. Because the model never pauses to lay out the whole task before diving in, it tends to skip a step, forget a sub-part of a multi-part question, or wander off the point partway through. Plan-and-solve prompting fixes this with a deceptively simple reordering: first devise a plan that divides the task into subtasks, then carry the subtasks out, rather than fusing the two into one continuous stream [3]. Naming the subtasks up front is what cuts the missing-step errors, along with the calculation slips and misreadings, that a terse chain tends to leave behind.
The everyday version is a cook and a recipe. A careful cook reads the whole recipe first, notices that the oven should be preheating and the butter should be softening before anything else happens, and only then starts. A hurried cook reads one line at a time and discovers, too late, that step four needed something that should have begun in step one. Plan-and-solve is simply the model reading the whole recipe before it starts to cook.
The difference between a chain and a plan shows in a single Ledgerly example. A terse chain-of-thought might reason, in one breath, “user says they were double charged, so check the invoice and issue a refund.” It reaches an action almost immediately, and it is almost certainly wrong, because it never established whether the second charge was actually a duplicate. A proper plan names the subtasks before touching anything:
- Identify the account and the billing period in question.
- Retrieve the charges for that period.
- Compare them by subscription, period, amount, and adjustment reason.
- If the dates straddle a plan change, retrieve the plan history.
- Retrieve the current refund policy.
- Decide eligibility from the evidence, not the customer’s framing.
- Act only within the approval rules, or escalate.
Same complaint, but now the refund is the last step, taken only if the evidence earns it, rather than the first reflex.
7.4.1 What a plan contains
Once you start writing plans explicitly, they turn out to share a skeleton, whatever the task. Figure 7.3 sketches its spine, and Table 7.1 fills it in for Ledgerly. A usable plan names its goal (what “done” means), the current state (what is known right now), the known constraints (rules that bound the actions), the missing information (what must be fetched before deciding), the candidate actions and their dependencies (what can be done, and in what order), the success criteria (how to tell it worked), the stop condition (when to stop reasoning), and the escalation criteria (when to hand off to a human).
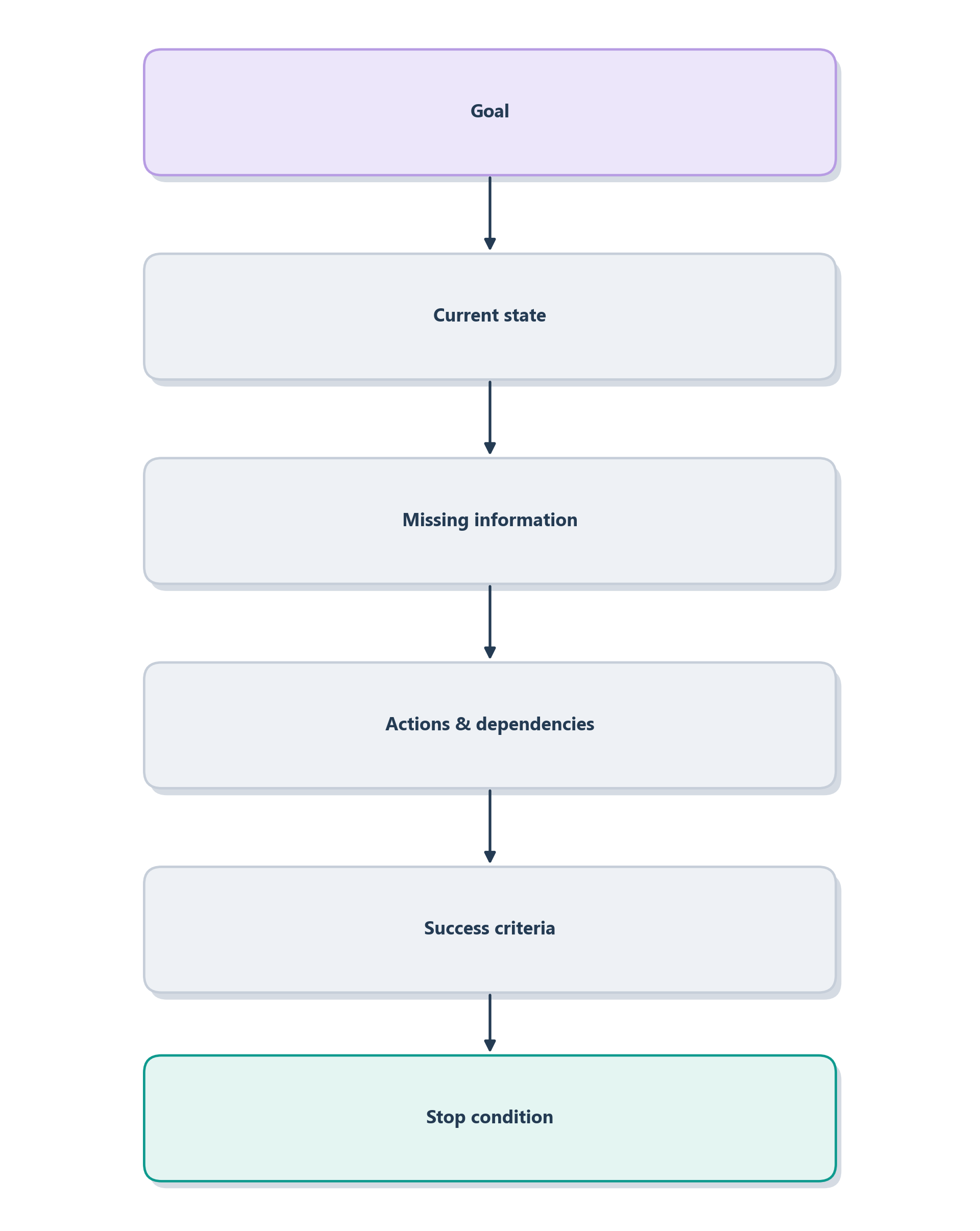
| Plan element | What it names | Ledgerly instantiation |
|---|---|---|
| Goal | what “done” means | resolve the double-charge claim correctly |
| Current state | what is known now | customer reports two charges last month |
| Known constraints | rules that bound actions | refund policy and the auto-approval threshold |
| Missing information | what to fetch first | invoice, billing periods, plan history, policy |
| Actions and dependencies | what to do, in order | fetch evidence, then compare, then decide, then act |
| Success criteria | how to tell it worked | charge classified and the customer’s issue resolved |
| Stop condition | when to stop reasoning | account cannot be identified, or evidence is sufficient |
| Escalation criteria | when to hand off | records conflict, or the refund exceeds the threshold |
A plan on paper, though, is still only a plan. The moment the agent starts fetching that missing information, its thoughts have to touch the world, and grounding them in what the world returns is the rung ReAct climbs.
7.5 ReAct: reasoning and acting together
Here is the rung that turns a thinker into a doer, and it is arguably the single most important pattern in this whole book. Chain-of-thought let the model reason, but only in its own head; the model could talk itself confidently into a wrong fact with nothing to check it against. ReAct, a compression of reasoning and acting, fixes this by interleaving the two, so the model alternates between having a thought and taking an action in the world, then folding what it observes back into its next thought [4]. It is the marriage of the reasoning from Chapter 5 with the tools from Chapter 6, and it is what most people actually mean when they say “an agent.”
The everyday analogy is the difference between solving a problem with your eyes closed and solving it with your eyes open. Imagine trying to fix a leaking tap purely by reasoning in an armchair: you would build an elaborate theory of the fault and might be completely wrong, because you never actually looked. Now imagine doing it with your hands on the pipe: you form a small hypothesis (“maybe the washer is worn”), you act on it (you open the valve and look), you observe the result (water still drips), and that observation reshapes your next thought (“not the washer, then; check the seal”). You are still reasoning, but every step is anchored to what the world just told you, so you can never drift too far from reality before being corrected. ReAct gives a model exactly this rhythm.
Concretely, the model’s output is structured into a repeating cycle of three moves, Thought, Action, and Observation, that runs until the model decides it has the answer. In the Thought it reasons about what to do next; in the Action it calls one of its tools; and the Observation is the real result that the runtime feeds back, exactly the function-calling handshake we drew in Section 6.3. Figure 7.4 shows the cycle, and it is worth noticing that it is simply the agent loop from Chapter 1, sense, decide, act, with an LLM installed in the “decide” box and its own thoughts added to what it senses.
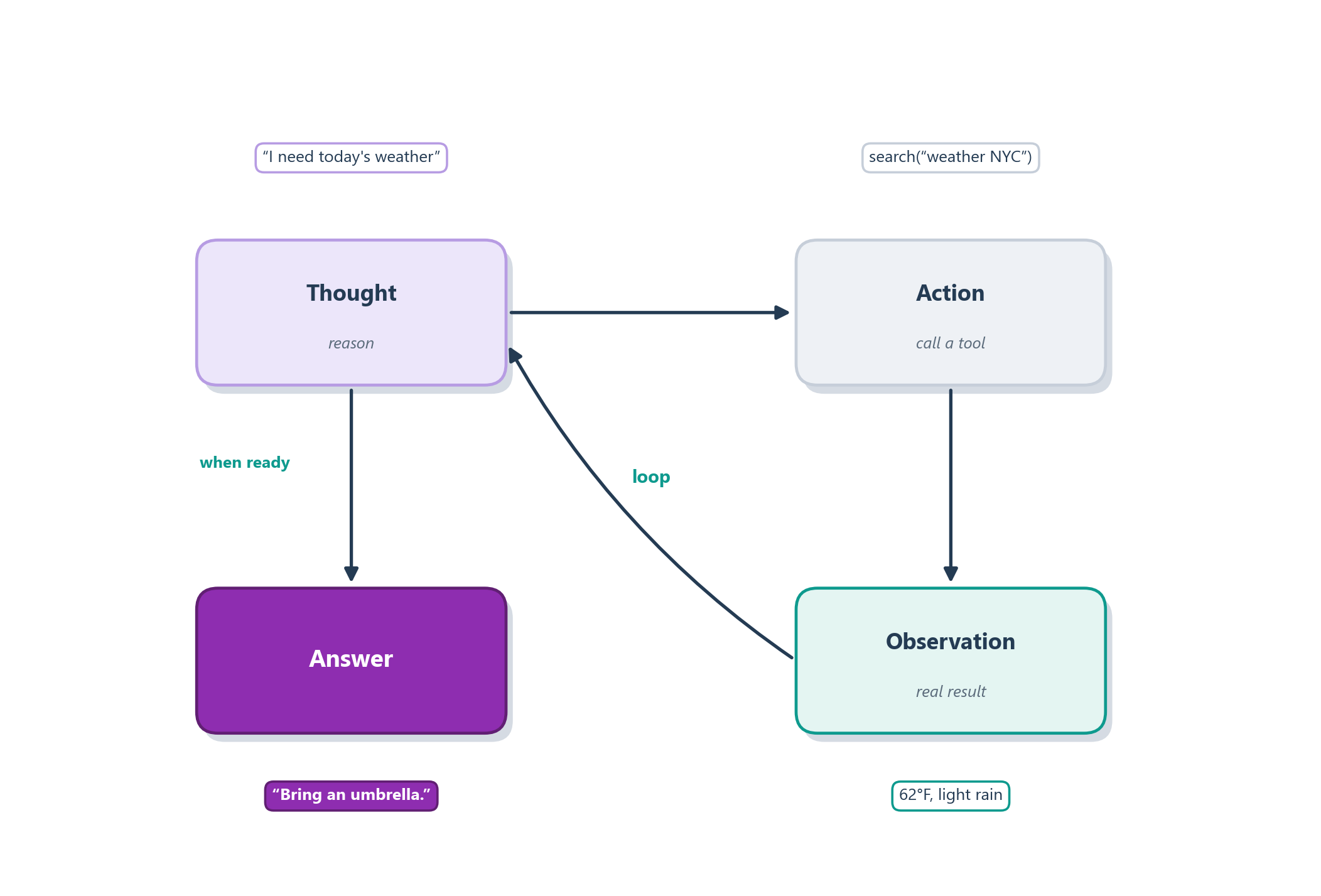
A short transcript makes the rhythm concrete. Suppose an agent is asked, “Which is taller, the Eiffel Tower or the Statue of Liberty, and by how much?” A pure chain-of-thought model would answer from memory and might misremember a number. A ReAct agent instead grounds each claim as it goes:
Thought: I need the height of each, then the difference. Start with the Eiffel Tower.
Action: search("height of the Eiffel Tower")
Observation: About 330 metres (including antennas).
Thought: Now the Statue of Liberty.
Action: search("height of the Statue of Liberty")
Observation: About 93 metres (ground to torch).
Thought: 330 minus 93 is 237. The Eiffel Tower is taller.
Answer: The Eiffel Tower, by roughly 237 metres.Notice what the loop bought us. Each height came from a real lookup rather than the model’s recollection, so the notorious hallucination risk is cut off at the source; the one piece of arithmetic could itself have been delegated to a calculator tool for the same reason. This is the deep reason ReAct is so central: it is the pattern that operationalizes the whole “grounding” idea from Chapter 5’s list of remedies. Reasoning tells the agent what it needs to find out, acting lets it actually find out, and observing keeps its reasoning honest. Almost every agent framework you will meet (and much of Part III) is, under the hood, a careful implementation of this Thought–Action–Observation cycle.
7.5.1 ReAct is a closed feedback loop
ReAct is easy to mistake for a prompting trick, a template that says “write a thought, then an action, then an observation.” It is really something stronger: a closed feedback loop [4]. Each move feeds the next. The thought updates the hypothesis, the action queries or changes the environment, and the observation brings a piece of the real world back into the model’s context. The crucial discipline is that the next thought must be conditioned on the observation, not on the guess that preceded it. An agent that ignores what a tool returned and keeps reasoning from its prior assumption has broken the loop, and it will drift exactly as far from reality as a pure chain of thought would.
A Ledgerly trace makes the loop visible. Suppose a customer writes, “I changed my plan last month and now I see two charges.” A grounded ReAct agent works like this:
Thought: Two charges could be a duplicate. Let me look at the recent charges.
Action: retrieve_charges(account, last_period)
Observation: Two charges. One has a different adjustment reason from the other.
Thought: A different reason suggests a plan change, not a duplicate. Check the plan history.
Action: retrieve_plan_history(account)
Observation: The plan changed mid-cycle last month.
Thought: Mid-cycle changes can be prorated. I need the refund policy before I decide.
Action: retrieve_refund_policy()
Observation: Refunds apply only to true duplicates, not to valid proration.
Thought: The evidence points to valid proration, not a duplicate. Continue validating,
and escalate if the records still conflict.Notice that the plan was not fixed in advance. Each observation reshaped the next thought: the different adjustment reason sent the agent to the plan history, and the plan history sent it to the policy. That is the loop doing its job, and it is why ReAct handles a tangled case that a straight chain of thought would have answered wrongly in one confident sentence.
An observation grounds the agent, but it is not automatically correct. A tool’s output can be partial, stale, ambiguous, filtered by permissions, wrong because of a system error, or simply misread by the model. At Ledgerly, a billing API that returns only settled charges will hide a pending one, and a plan-history tool that lags behind the billing system can make the agent conclude there was no migration when there was. This is the same lesson as Section 6.3: a tool’s output is an observation, not an instruction. Treat it as evidence to be weighed, and let the next thought question it when it looks incomplete.
But ReAct still has a blind spot: it reacts step by step and rarely stops to ask whether its overall approach is working. Teaching it to do that is the next rung.
7.6 Reflection: learning from your own mistakes
ReAct keeps an agent grounded moment to moment, but it is still, in a sense, always looking at the next step rather than at the whole attempt. Anyone who has written a first draft knows that this is not how good work gets made. The difference between a mediocre essay and a good one is rarely the first pass; it is the re-reading, the moment you step back, notice the argument doesn’t hold together, and rewrite. Reflection gives an agent that same capacity to critique its own output and try again.
The analogy that captures it best is a chess player reviewing a game they just lost. They do not simply feel bad and move on; they replay the game, find the move where it went wrong, put that lesson into words (“I overextended on the queenside”) and carry that verbal lesson into the next game. Reflection works exactly this way for an agent. After an attempt, the agent is asked to look back over what it did, judge whether it succeeded, and if it failed, articulate in words what went wrong and what it should do differently. That written self-critique is then added to its context for the next attempt, so the agent is quite literally learning from its own mistakes within a single session, without anyone retraining the underlying model. The research that introduced this called it verbal reinforcement learning, because the reward signal driving improvement is not a numeric gradient but a sentence of feedback the agent writes to itself [5]. Figure 7.5 shows the loop.
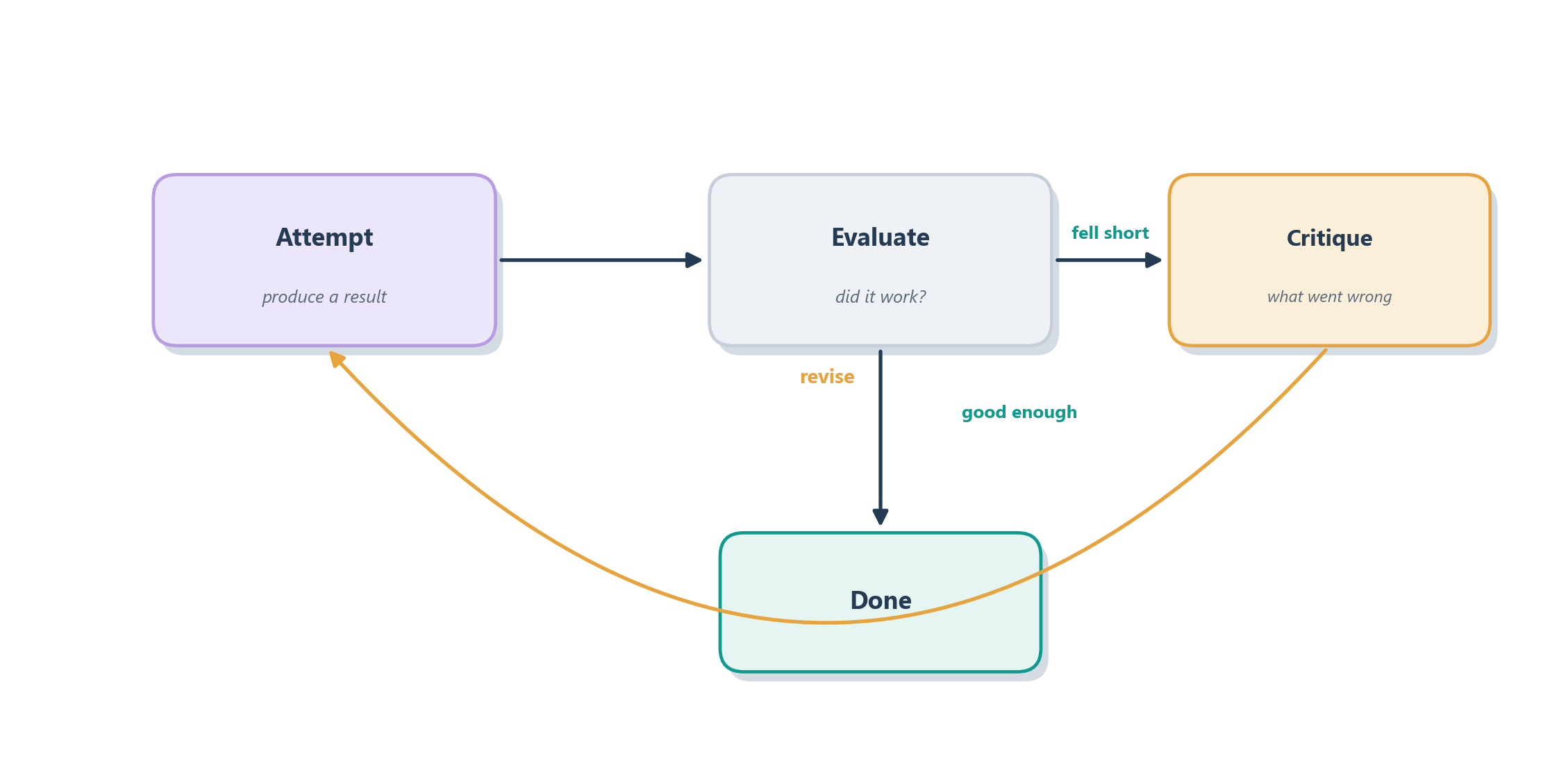
7.6.1 Reflection needs a judge
Reflection is the most over-sold rung on the ladder, so it is worth being precise about why it works when it works. Reflexion improved because a feedback signal drove each retry, not because a model can reliably grade itself in a vacuum [5]. The self-critique is only as good as the judge behind it. Give reflection a real judge and it becomes powerful; ask the model to be its own judge on a fuzzy target and it mostly rephrases its earlier confidence.
A good judge supplies evidence the model cannot argue with: a failing unit test, a tool error, a policy or constraint validator, direct user feedback, a human reviewer, a deterministic rule, a known benchmark answer, or a scoring rubric. Reflection turns weak in the opposite conditions: when the target is subjective, when the model is the sole judge, when the failure is subtle, when there is no concrete evidence to point at, or when the critique simply repeats the same wrong assumption that caused the first failure.
At Ledgerly, a refund-eligibility validator, a small deterministic check that compares the charges against the policy, is a far better judge than asking the model whether a refund “seems fair.” The validator can say no, these are prorated charges and the policy excludes them, and that verdict gives the reflection something real to correct. This is the same grounding that let Reflexion reach 91% pass@1 on HumanEval where a prior GPT-4 result sat at 80% [5]: the code either passed the tests or it did not, and the tests were the judge.
Reflection is the concrete form of the second remedy from Chapter 5 (verify rather than trust a single pass) and it pairs naturally with everything below it on the ladder. You can wrap a reflection loop around a chain of thought, asking the model to check its own reasoning, and you can wrap one around a whole ReAct trajectory, letting the agent notice that its overall strategy is failing and change tack. It is worth being honest about the catch, though, because it foreshadows a real limit: an agent’s self-critique is only as good as its ability to tell that it failed. When there is a clear external signal (code that won’t compile, a test that fails, a search that returns nothing) reflection is powerful, because reality is supplying the verdict. When success is fuzzy and the agent has to be the sole judge of its own work, reflection helps less, because a model that was confidently wrong the first time may be just as confidently wrong about whether it was wrong. Even reflection, then, benefits from being grounded. That still leaves one gap on the ladder: reflection improves an attempt after the fact, but what if we want the agent to weigh several possibilities before committing? For that we need to let it search.
7.7 Search-based planning: exploring many paths
Every strategy so far has followed a single thread. Chain-of-thought writes one line of reasoning; ReAct walks one trajectory of thought and action; reflection improves that one trajectory after the fact. But some problems cannot be solved by walking a single path, because the first move you make forecloses the answer before you even know whether it was right. Think back to the trip-planning example that opened this chapter: a good planner does not commit to the first route that comes to mind, they hold several possibilities open at once, weigh them, and only then commit. This final rung teaches an agent to do the same: to search across alternatives rather than gamble everything on its first idea.
The analogy to hold is exploring a maze. If you commit to the first turning at every junction and never look back, you will almost certainly hit a dead end and, worse, have no way to recover; you have already thrown away the choices that might have led out. A careful explorer instead treats the maze as a branching tree of possibilities: at each junction they consider the available turns, form a judgment about which look promising, explore those, and backtrack when a path dead-ends. This is one of the oldest ideas in artificial intelligence (Newell and Simon framed problem solving itself as search through a space of possible states half a century ago [6]), and Tree of Thoughts brings it to language models [7]. Instead of generating one chain of thought, the model generates several candidate “thoughts” at each step, evaluates how promising each one looks, and expands the best while abandoning the rest. Figure 7.6 contrasts the single line of chain-of-thought with this branching search.
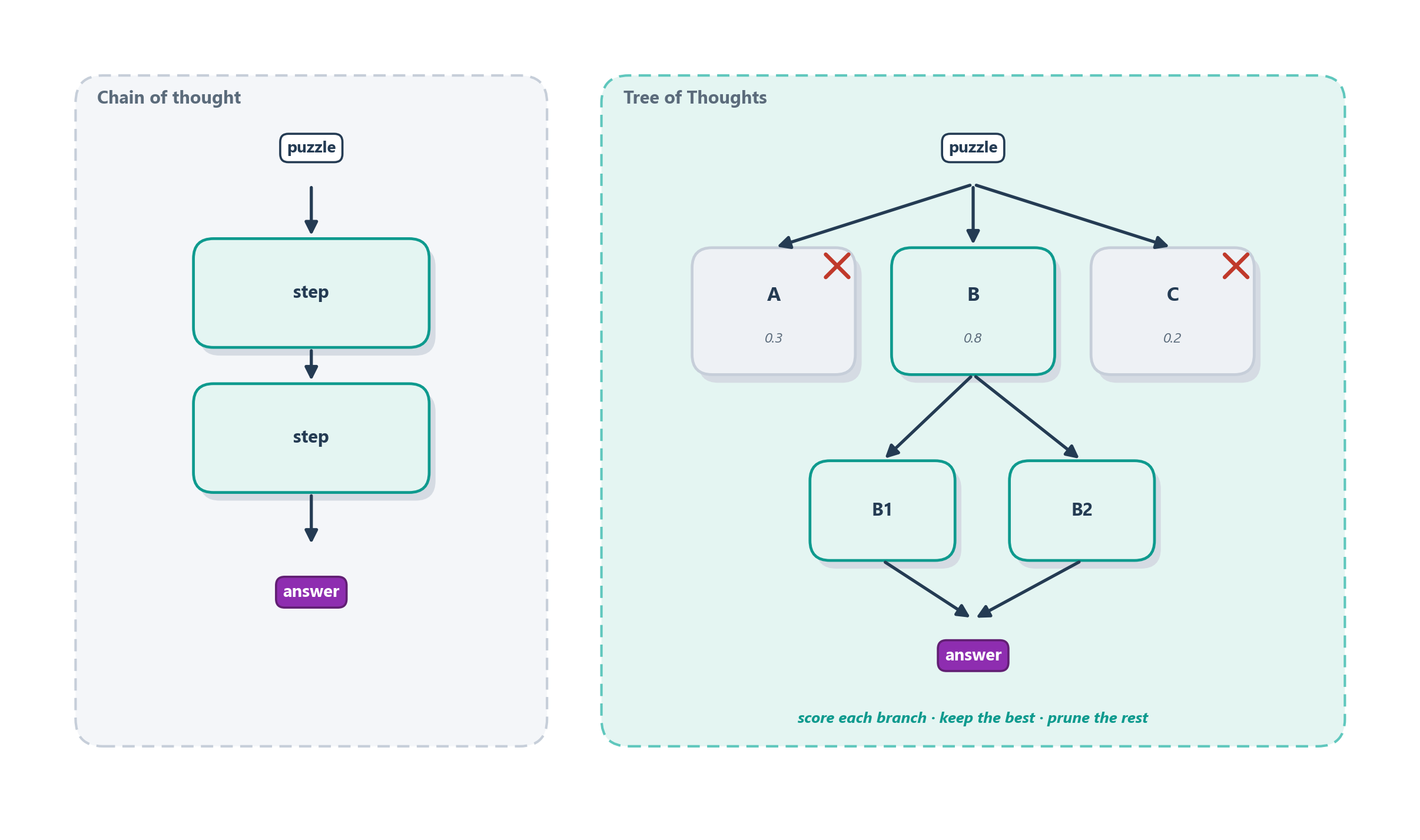
The payoff shows up precisely on the problems where a first guess is likely to be wrong and lookahead is essential. On the Game of 24 (a numbers puzzle where you must combine four values with arithmetic to reach 24, and a bad opening move quickly leads nowhere), GPT-4 using chain-of-thought solved just 4% of the puzzles, while the same model wrapped in a Tree of Thoughts search solved 74% [7]. That is not a subtle improvement; it is the difference between a method that mostly fails and one that mostly succeeds, and it comes entirely from letting the model explore and evaluate alternatives instead of committing to its first thought.
7.7.1 When branching is worth it
Tree search is powerful, but that 4% to 74% jump should come with a warning label: it happened on a problem practically designed for search, and most tasks are not. Branching earns its cost only under specific conditions. It is worth it when early choices strongly constrain later ones, when several plausible paths genuinely exist, when the search space is bounded, when partial solutions can be evaluated, when backtracking is possible, and when a wrong early move is expensive to undo. It is not worth it for a simple lookup, when tool evidence directly resolves the question, when the space is enormous, when partial progress cannot be judged, or when latency and cost budgets are tight.
Ledgerly shows both faces. There is no tree to grow for “show me invoice 4471”; one lookup answers it, and any branching is pure waste. But a genuinely tangled enterprise dispute, where the two charges could be a duplicate, a valid proration, a failed-and-retried refund, a plan-migration bug, an account-owner mismatch, or the result of two overlapping subscriptions, is exactly the kind of knot where holding several hypotheses open and weighing each against the evidence pays off. This is the classical picture Newell and Simon drew: a state to start from, actions that move between states, a plan as a path through that space, and heuristics to judge which paths look promising [6]. Branch when the problem is really a search; do not when it is really a lookup.
It is worth seeing that search and the earlier rungs are variations on one theme: considering more than one possibility. The simplest version of the idea needs no tree at all: self-consistency, which we met in Chapter 5, just samples several independent chains of thought and takes the answer they most agree on [8]. Tree of Thoughts is the richer, structured cousin that branches, evaluates, and backtracks step by step. Both trade the same currency: exploring many paths means running the model many times, and that is anything but free. There is a happier way several paths can play out, though, and it is worth a short detour before we tally the bill: sometimes the paths do not depend on each other at all.
7.8 Parallel planning: when actions are independent
Everything on the ladder so far has been sequential, and ReAct most of all: think, act, observe, then think again, one step at a time. That is the right shape when each step depends on the last, as it did in the plan-migration trace, where the agent could not know it needed the policy until the plan history came back. But not every subtask depends on the one before it. Some are simply independent, and running them one after another is a self-inflicted delay, like a manager who runs three unrelated errands in sequence when three people could have run them at once.
The idea is to let a planner build a small dependency graph of the subtasks, then run the independent ones in parallel while the dependent ones wait their turn. The LLM Compiler is the clearest statement of this: a Function Calling Planner decides the tasks and their dependencies, a Task Fetching Unit dispatches each call as soon as its inputs are ready, and an Executor runs the independent calls concurrently [9]. Because ordinary function calling forces a fresh round of reasoning before every single call, the sequential version is slow and expensive; parallelizing the independent calls, the authors report, cut latency by up to 3.7x, cost by up to 6.7x, and even improved accuracy by up to about 9% against a ReAct baseline. Parallelism, in other words, is not only about speed: it also removes the chance for the model to talk itself off course between calls.
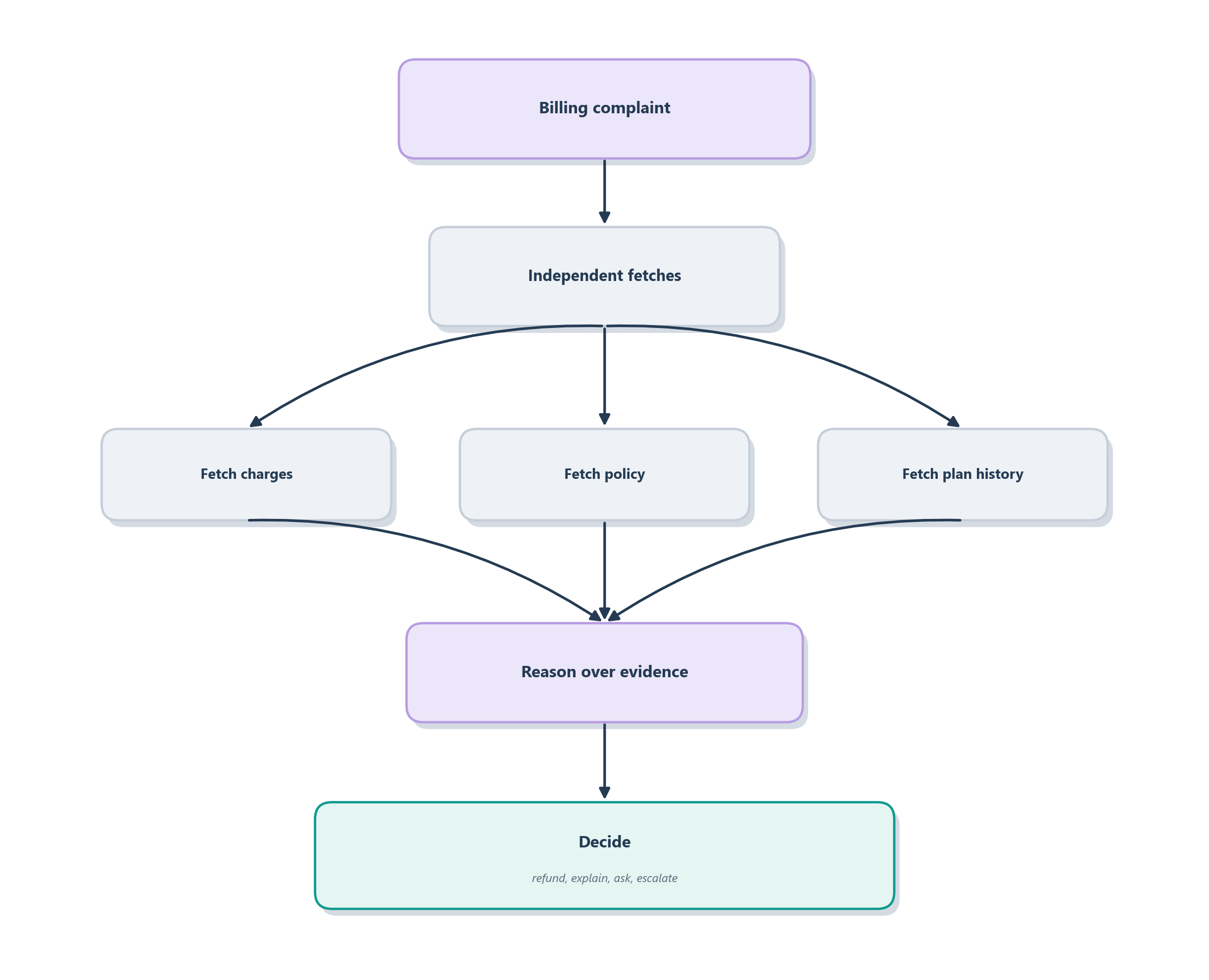
At Ledgerly, when the double-charge complaint arrives, several facts are needed and none of them depends on the others: the recent charges, the current refund policy, the subscription’s plan history, and the customer’s support history. A sequential agent fetches them one at a time, reasoning in between; a parallel planner fires them all at once and reasons only once they have arrived. Figure 7.7 shows that fan-out and join.
7.8.1 Planner, executor, controller
Pulling the loop apart this way reveals a clean separation of roles that will reappear throughout Part III. The planner decides which tasks to run and how they depend on each other. The executor actually runs the calls. The observer collects the outputs. The evaluator judges progress against the goal. And the controller makes the control decision we named at the start of the chapter: continue, retry, branch, stop, or escalate. In the Ledgerly investigation, the planner lays out the parallel fetches plus the later comparison, the executor calls the billing tools, the observer gathers the charges and policy, the evaluator checks whether the evidence classifies the charge, and the controller decides whether to refund, explain, ask, or escalate.
These are roles, not yet software. Full orchestration frameworks such as LangGraph (Chapter 12) and the OpenAI Agents SDK (Chapter 13) give each role a concrete home, and we build them there. For now the point is the mental model: an agent that plans is really running these five roles in a loop, whether or not you have named them.
7.9 Choosing a strategy: matching effort to difficulty
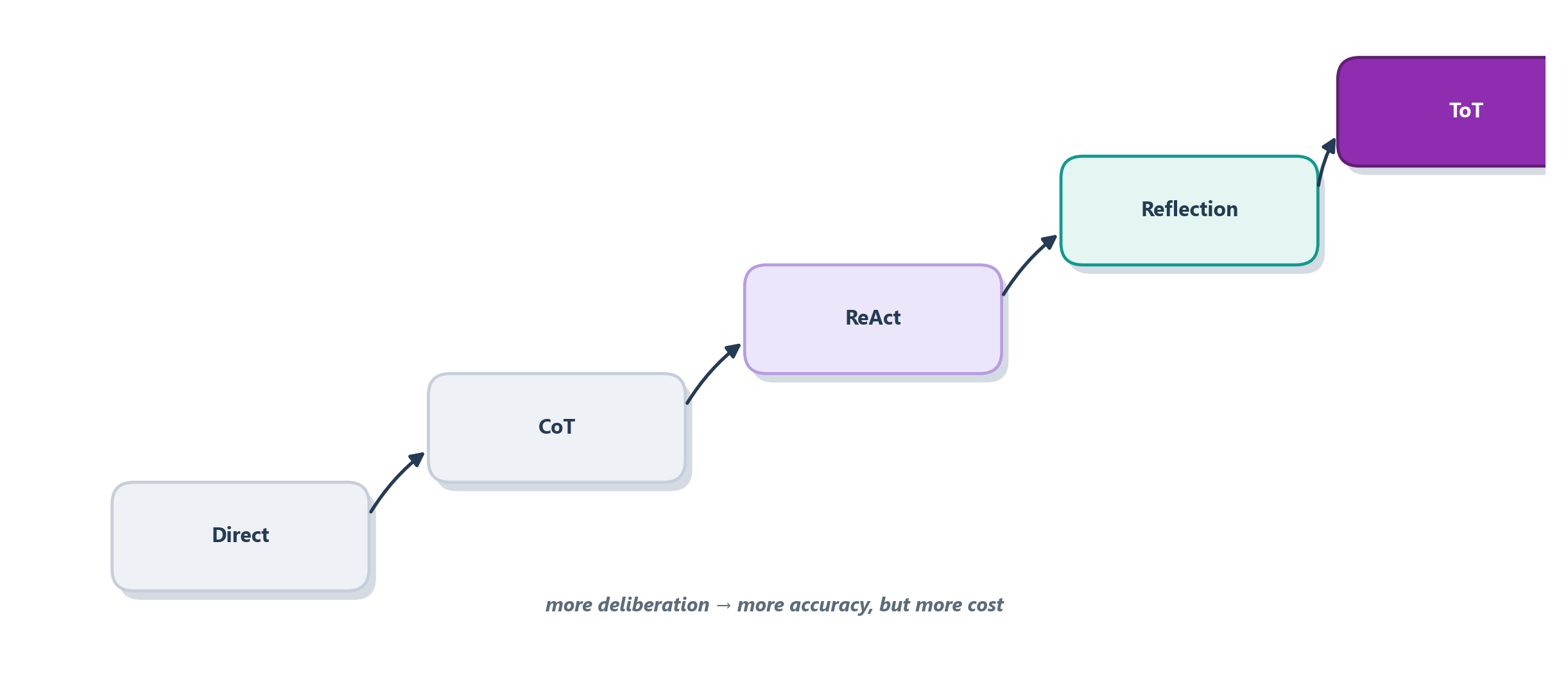
We promised at the start to be honest about the cost of all this thinking, and now we can pay that debt. Each rung of the ladder buys accuracy by spending computation, and the spending is not linear. A direct answer is one call to the model. Chain-of-thought is still one call, but a longer one, since the model now writes out its reasoning. ReAct multiplies that by the number of steps it takes, because each Thought–Action–Observation cycle is another round trip. Reflection multiplies it again by the number of retries. And search is the most expensive of all, because exploring a tree means generating and evaluating many thoughts at every branch. It is entirely possible to build an agent that answers a trivial question with a hundred model calls and a ten-second delay, and that is not sophistication, it is waste. Figure 7.8 lines the strategies up against their cost.
The guiding principle, then, is to match the depth of deliberation to the difficulty of the task, and it mirrors how you spend your own effort. You answer a colleague’s simple question off the top of your head; you would not convene a week-long planning offsite to decide where to eat lunch, nor would you pick a company’s five-year strategy by blurting the first idea that came to mind. An agent deserves the same judgment. If a task is a single, factual lookup, a direct answer or one tool call is plenty. If it needs a few steps of reasoning over facts it must fetch, ReAct is the natural fit. Reserve reflection for tasks where a first attempt can be checked (code that must pass tests, a plan that must satisfy constraints), and reserve full tree search for the genuinely hard problems where a wrong first move is fatal and lookahead earns its keep.
Table 7.2 gathers the whole ladder, now including the two planning ideas this chapter added, into one view: what each strategy is for, where it breaks, and what it looks like at Ledgerly.
| Strategy | Best for | Weakness | Ledgerly example |
|---|---|---|---|
| Direct answer | a known fact or simple lookup | no reasoning, no grounding | “show invoice 4471” |
| Chain-of-thought | self-contained multi-step reasoning | ungrounded, single path | explain how proration is computed |
| Plan-and-solve | multi-part tasks that skip steps | still ungrounded until it acts | lay out the double-charge investigation |
| ReAct | tasks needing fetched evidence | sequential, can drift on bad data | pull charges, plan history, and policy in turn |
| Reflection | attempts with a clear failure signal | weak when the model judges itself | retry after a refund-validator rejection |
| Tree of Thoughts | tangled problems with costly early moves | most expensive, needs evaluable partials | untangle a multi-hypothesis dispute |
| Parallel planning | independent subtasks | needs a correct dependency graph | fetch charges, policy, history at once |
Start with the cheapest strategy that could plausibly work and add deliberation only when you see it failing, rather than reaching for tree search on day one. In production, the depth of reasoning is itself a dial you can turn per task: many systems route easy requests to a single quick call and escalate only the hard ones to ReAct or search. Two levers keep this affordable: treat reasoning as a budget you spend deliberately rather than by default, and parallelize independent tool calls so extra grounding costs latency once, not once per step. Measured against a real evaluation set (the subject of Chapter 8 and, later, our chapter on evaluation), this “as much reasoning as the task needs, and no more” discipline is usually what separates an agent that is both accurate and affordable from one that is merely one or the other.
7.9.1 A plan needs a stop condition
Every plan so far has quietly assumed something we now have to make explicit: it ends. An agent without a stop condition is not thorough, it is a runaway loop, burning tokens and, worse, taking actions long after it should have paused. A plan should stop when the goal is satisfied, when the required evidence has been collected, when a hard constraint blocks further progress, when a tool has failed repeatedly, when a step limit is reached, when the next action is high-risk and needs approval, when the model is too uncertain and needs the user to clarify, or when further reasoning is unlikely to change the answer. This is the same discipline as the loop’s “repeat up to N times” bound from Chapter 1: a termination rule is not a nuisance, it is a safety feature, and it is flagged for exactly this reason in the OWASP guidance on unbounded agent behavior [10].
Ledgerly makes the three most important stops concrete. If the account cannot be identified, the agent stops and asks rather than guessing. If the refund tool fails twice, it stops and escalates rather than retrying forever. And if the refund would exceed the auto-approval threshold, it stops and requests human approval before acting. Each stop trades a little autonomy for a lot of safety.
7.9.2 Repairing the plan when the world disagrees
Stopping is one response to trouble; repairing the plan is the other, and it is worth separating from reflection. Reflection critiques an attempt after it finishes. Plan repair happens mid-flight, when an observation contradicts the plan the agent is currently executing. A plan can break for many ordinary reasons: a tool returns no data, a policy contradicts the hypothesis, a permission is missing, the user supplies new information, an assumption turns out false, or the environment simply changed since the plan was made. A capable agent treats its plan as provisional and rewrites it when the world disagrees.
The Ledgerly investigation shows a clean repair. The initial plan is straightforward: retrieve the charges, confirm the duplicate, issue the refund. Then the observation lands, and one of the two charges carries a valid proration reason, not a duplicate. The refund path is now wrong. The repair abandons it, switches to explaining how the two charges compose the month’s bill, and offers escalation if the customer still disputes the policy. Same goal, resolve the complaint correctly, but a completely different plan, chosen because the evidence demanded it.
These strategies (think, plan, act, check, search, and parallelize) are the vocabulary of agent reasoning, and almost every sophisticated behavior you will meet later is a combination of them. Before we leave reasoning behind, it is worth watching every one of them cooperate on a single realistic problem, the kind Ledgerly meets every day.
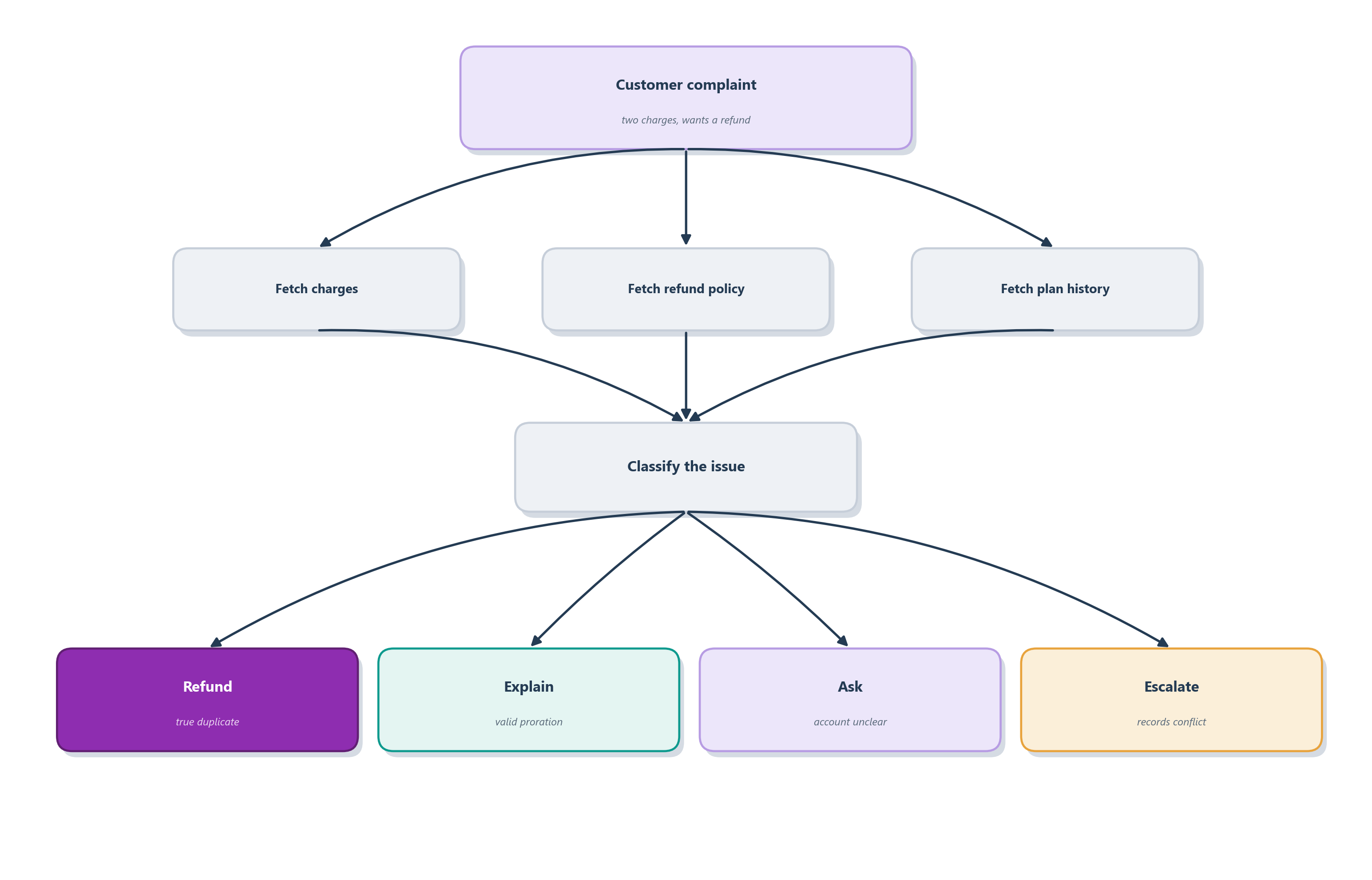
7.10 Case study: planning a Ledgerly billing investigation
Bring the whole chapter to bear on one message. A Ledgerly customer writes: “I changed my plan last month and now I see two charges. Why did this happen, and can you refund one of them?” It is the hardest kind of request the agent meets, because the customer has already proposed the answer, a refund, and the honest answer might be no. Reasoning, planning, and control all have to work together to get it right.
The plan the agent should follow reads like the anatomy from Section 7.4.1, made specific, and Figure 7.9 draws it:
- Identify the account and the billing period.
- In parallel, fetch the charges, the plan history, and the current refund policy.
- Compare the charges by subscription, period, amount, and adjustment reason.
- Classify the situation: duplicate, proration, renewal, or unresolved.
- If it is a duplicate and the policy allows, act within the approval rules.
- If it is a valid proration, explain how the two charges compose the bill.
- If the records conflict, escalate to a human.
- Save the outcome to memory for the next conversation.
The ways this goes wrong are predictable, and each maps to a lesson from this chapter. The agent issues the refund before checking the plan history (no plan, straight to action). It treats a valid proration as a duplicate (reasoning ungrounded by the policy). It keeps reasoning after a billing tool fails instead of stopping to ask (no stop condition). It quotes a stale refund rule from training instead of the current policy (no grounding). Or it presses ahead and refunds an amount that should have required sign-off (no approval gate).
The safeguards are the mirror image. Evidence comes from tools, not the customer’s framing. A policy validator, not the model’s sense of fairness, decides eligibility. A stop condition halts the loop when the account is unclear or a tool has failed. An approval gate guards any refund above the threshold. An audit log records what was decided and why. And reflection is used only when the failure signal is clear, such as a validator rejection, never as a vague “does this feel right?”
The agent grows a head for planning:
- It now plans before acting: name the subtasks, then carry them out.
- It tracks state across a ReAct loop and repairs the plan when the evidence disagrees.
- It runs independent lookups in parallel (charges, policy, plan history) and reasons once.
- It knows when to stop: ask when the account is unclear, escalate on conflict, and request approval above the refund threshold.
Ledgerly’s agent can now reason, plan, act, check its work, and stop itself. But that raises a prior question we have quietly stepped past: for a given billing request, do you even want a free-ranging agent that decides its own steps, or a fixed workflow that runs the same reliable path every time? That is one of the most important design decisions you will make, and Chapter 8 takes it up, arguing, perhaps surprisingly, that the simpler answer is often the right one.
7.11 Summary
- Reasoning, planning, and control are three different jobs: reasoning asks what follows from what it knows, planning asks what to do next, and control asks whether to continue, retry, branch, stop, or escalate. Planning is reasoning under control.
- Reasoning strategies form a ladder, each rung adding what the one below lacks: chain-of-thought (think), ReAct (act while thinking), reflection (check your work), and tree search (explore alternatives).
- Chain-of-thought lets the model deliberate in a straight line, but its steps rest on the model’s own beliefs and it commits to a single path [1].
- Plan-and-solve names the subtasks before solving them, cutting the missing-step errors a terse chain leaves behind: a chain is not always a plan [3].
- ReAct interleaves Thought, Action, and Observation so reasoning stays grounded in real tool results. It is the pattern most people mean by “an agent,” and the operational form of Chapter 5’s grounding remedy [4].
- Reflection has the agent critique its own attempt in words and retry, but it needs a real judge (a test, a validator, a signal); it is weak when the model must grade itself in a vacuum [5].
- Search (Tree of Thoughts) explores and evaluates many reasoning paths, dramatically helping on problems where a first move can be fatal (4% to 74% on the Game of 24), but only when branching truly matters [7].
- Parallel planning runs independent tool calls at once behind a dependency graph, cutting latency and cost rather than just accuracy [9].
- A plan needs a stop condition: knowing when to stop, ask, or escalate is a safety feature, not a nuisance [10].
- Deliberation costs tokens, latency, and money, and the cost rises steeply up the ladder; the real skill is matching the depth of reasoning to the difficulty of the task.
We now know how to make a single agent reason well, from a quick thought to a deliberate search. The next question is architectural rather than cognitive: given a problem, should you hand it to a flexible agent that chooses its own steps, or to a fixed workflow that runs a reliable path every time? Chapter 8 takes up that decision, and argues, perhaps surprisingly, that the simpler answer is often the right one.
7.12 Exercises
- For each rung of the ladder (chain-of-thought, ReAct, reflection, tree search) name a task where it is clearly the right amount of deliberation, and a task where it would be overkill. What feature of the task drives your choice?
- ReAct grounds each reasoning step in a real observation. Take the Eiffel Tower transcript from Section 7.5 and explain, step by step, where a pure chain-of-thought agent could have gone wrong and how the Thought–Action–Observation loop prevents it.
- Reflection is “only as good as the agent’s ability to tell that it failed.” Give one task where the success signal is crisp enough for reflection to work well, and one where it is too fuzzy, and explain what makes the difference.
- Tree of Thoughts turned 4% into 74% on the Game of 24 but is the most expensive strategy on the ladder. Describe a task where that trade is clearly worth it, and one where it clearly is not, using the cost picture from Figure 7.8.
- Sketch how you might combine two strategies for a coding agent, for example ReAct to gather context and run tests, wrapped in a reflection loop. What signal would trigger a reflection, and when would the loop stop?
- Write an explicit plan for a Ledgerly scenario of your choice using the anatomy from Section 7.4.1, and give it concrete stop and escalation conditions. Which condition fires first if the billing tool keeps timing out?
- Take the billing investigation in Section 7.10 and sort its subtasks into those that can run in parallel and those that must run in sequence. For each dependency you find, name the specific piece of evidence that forces the ordering.
- You are handed a new Ledgerly dispute. Using the rule in Section 7.7.1, decide whether tree search is worth its cost, and justify your answer from the features of the task rather than from the fanciness of the method.