9 Agentic Patterns
“We are what we repeatedly do. Excellence, then, is not an act, but a habit.”
— Will Durant, The Story of Philosophy
After this chapter you will have a toolbox of reusable agentic patterns and know when each applies.
9.1 Opening intuition
The previous chapter left us at a satisfying but incomplete place. We decided that a given task wants a workflow, an agent, or a hybrid, but “build a workflow” is not yet a design. It is like deciding to build a house out of brick rather than timber: a real and important choice, but it does not tell you where the walls go. This chapter hands you the floor plans. It turns out that the vast majority of production LLM systems, however elaborate they look from the outside, are built from a small handful of recurring shapes, combined and nested like rooms in a house. Learn the handful, and you can read almost any system, and design your own.
Here is the reassuring part, and the reason this chapter is shorter on new theory than you might expect: there are only about five of these shapes, and you have already met the ideas behind several of them. When Anthropic studied dozens of teams building LLM systems in production, the lesson that came back again and again was that the most successful ones did not reach for complex frameworks; they composed simple, reusable patterns [1]. Think of them as the standard joints a carpenter knows: the dovetail, the mortise and tenon. None is complicated on its own. The craft is in knowing which joint a given problem calls for, and how to combine a few of them into something sturdy.
We will walk through the five workflow patterns in order of increasing flexibility, exactly the way complexity tends to grow in a real project. Prompt chaining runs steps in a fixed line. Routing picks which line to run. Parallelization runs several lines at once and combines the results. Orchestrator–workers lets a lead model invent the lines on the fly. And evaluator–optimizer loops a maker against a critic until the work is good, a shape you will recognize from the reflection idea in Section 7.6. Figure 9.1 lays the five out side by side so you can see the progression before we take them one at a time. Each is a way of arranging augmented-LLM calls, from the most rigid to the most adaptive; where the arranging finally passes entirely to the model, the workflow has become an agent.
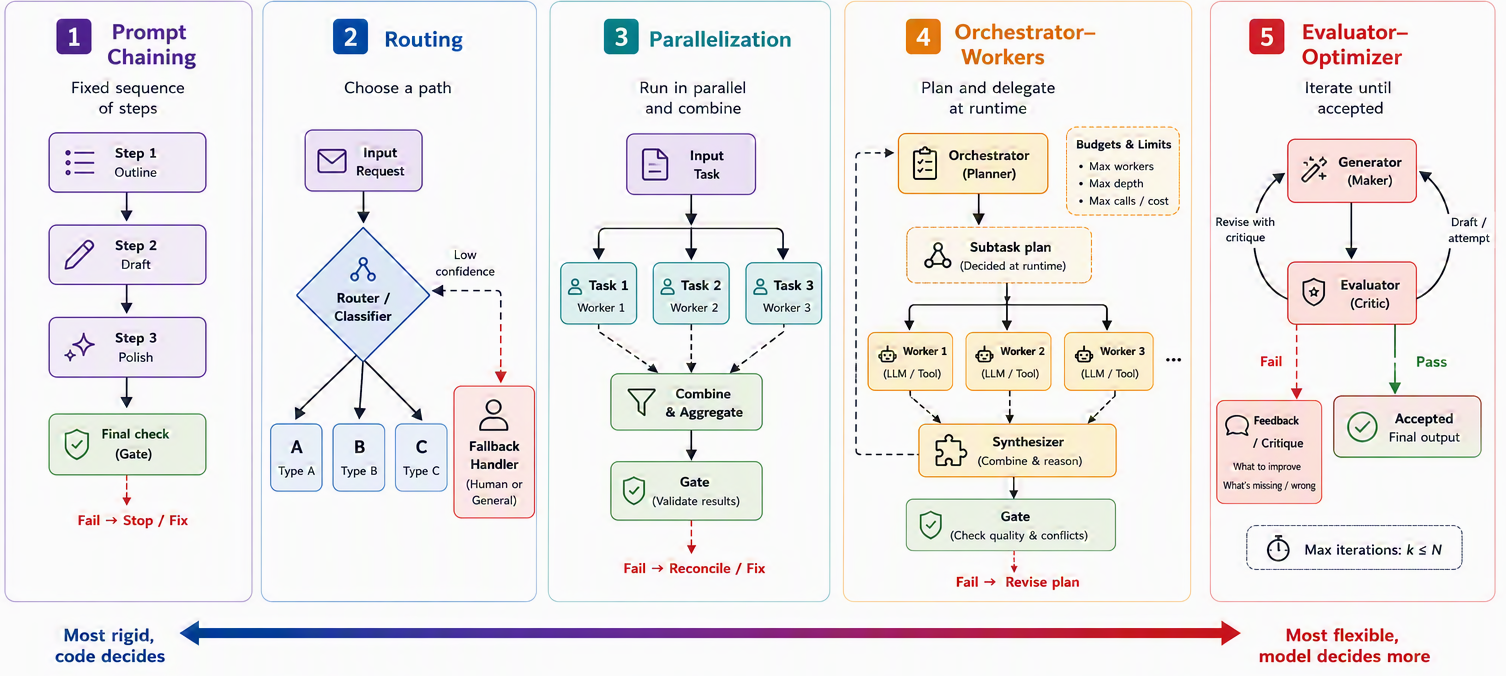
With the map in hand, let’s walk it. We start with the simplest shape of all: steps in a straight line.
9.2 Prompt chaining
The simplest pattern is the one you would invent yourself if you sat down with a hard task and a single instinct: break it into steps and do them one at a time. Prompt chaining decomposes a task into a fixed sequence of LLM calls, where each call works on the output of the one before it [1]. It is an assembly line. Think of writing a report the way a careful person actually does it: first draft an outline, then flesh the outline into prose, then polish the prose. Each station does one job and hands its work to the next. You would never try to do all three in your head at once, and neither should the model.
Why bother splitting a task this way when a single powerful call might, in principle, do the whole thing? Because each smaller call is an easier call, and easier calls are more accurate. By trading a little extra latency (you are now making three requests instead of one), you buy higher quality, because the model never has to juggle outlining and drafting and polishing simultaneously [1]. The pattern also gives you somewhere to stand between steps. You can insert a programmatic gate, a plain code check, that inspects the intermediate output and only lets the chain proceed if it looks right. Figure 9.2 shows the shape, gate and all.
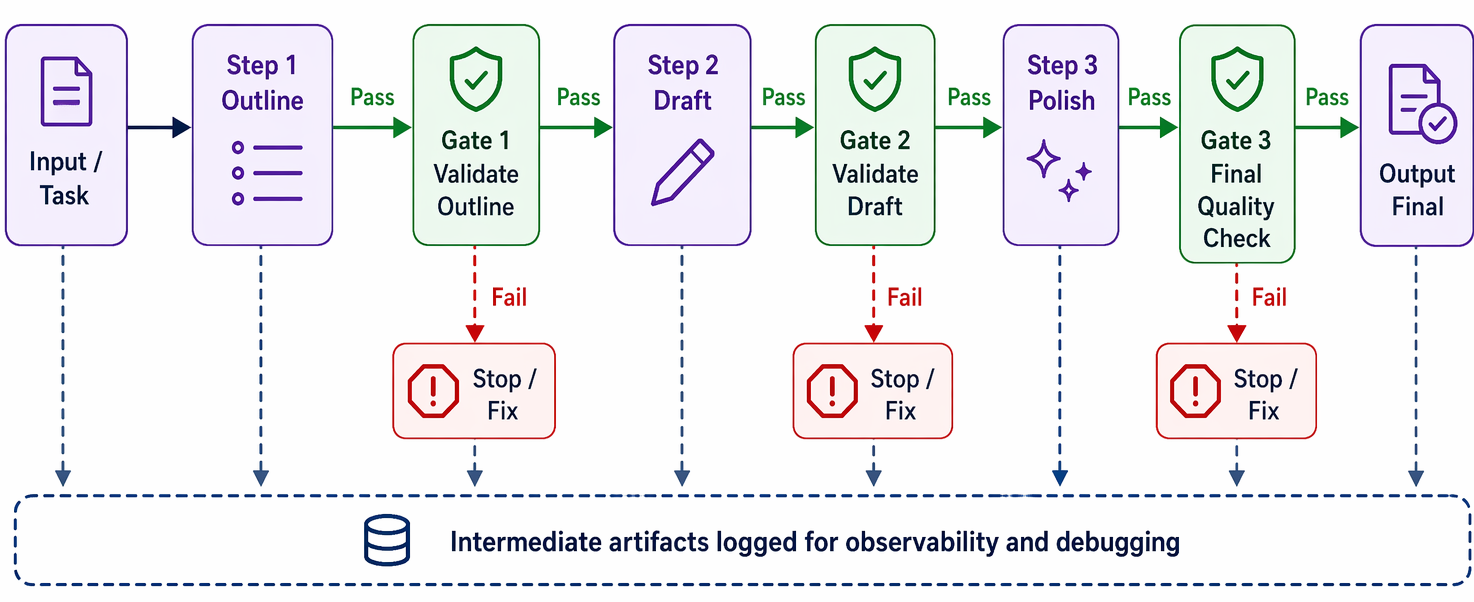
The gate is what makes chaining more than a fancy way of calling the model three times. Suppose the first call is meant to produce an outline that meets certain criteria; a small code check can confirm the outline actually has, say, the required sections before you spend money drafting from a bad plan. This is the pattern to reach for whenever a task cleanly decomposes into fixed subtasks whose order you already know, writing marketing copy and then translating it into another language, or drafting a document outline, verifying it, and only then writing the full document [1]. Notice the boundary condition, because it matters for the whole chapter: chaining assumes the steps are fixed and known in advance. The moment the right sequence depends on the input, when some requests should be handled one way and others another, a straight line is the wrong shape, and you need something that can branch. That is routing, and it is where we turn next.
Every pattern is a quiet bet on the shape of the task, so it pays to name the bet out loud. Prompt chaining assumes the sequence of steps is fixed and known before the first call runs. Its gate is a check on each intermediate output before you spend the next call. Its failure mode is silent contamination: a bad intermediate slips through, and every downstream step inherits the mistake without complaint. The signal that it is working is a healthy intermediate-gate pass rate alongside final-output quality; when the gate starts failing often, the task has drifted out of the fixed shape chaining depends on.
9.3 Routing
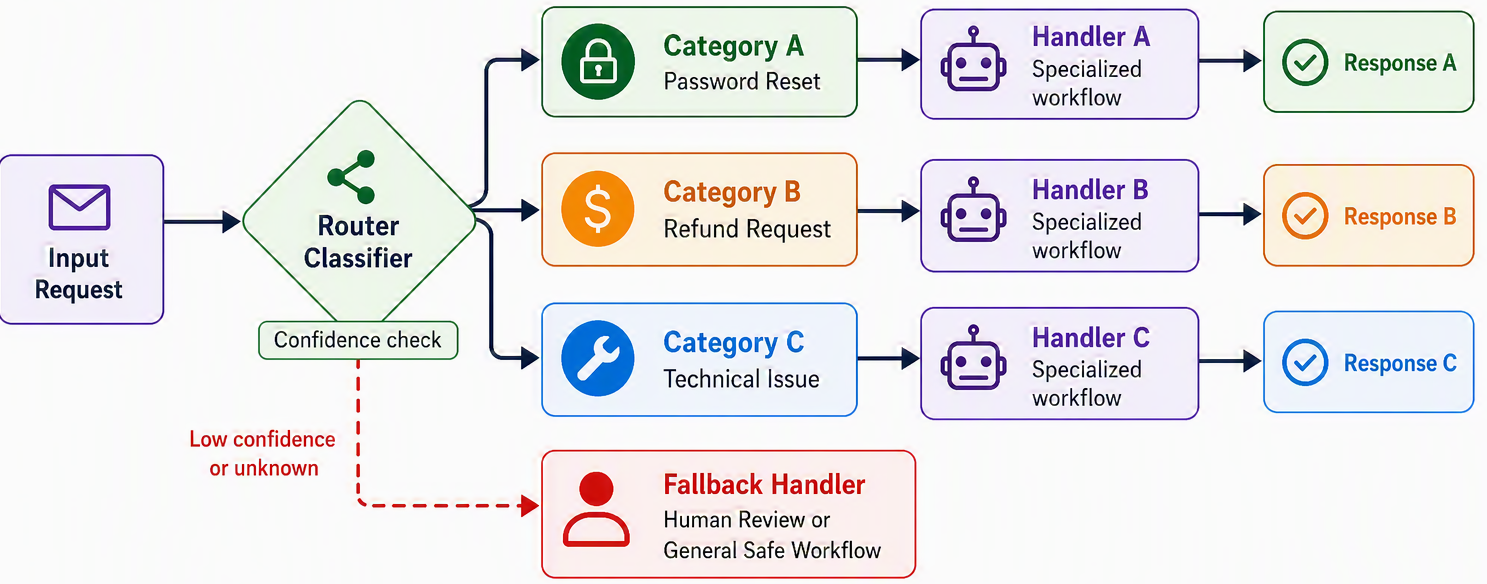
Chaining assumes every input travels the same line. But real inputs are rarely so uniform. The emails arriving at a support desk are not all the same kind of email: some are simple password resets, some are refund demands, some are gnarly technical failures. Trying to handle all of them with one all-purpose prompt is like asking a single employee to be your receptionist, your accountant, and your engineer at once, they will be mediocre at all three, because the instructions that make them good at one job pull against the instructions for another. Routing fixes this by adding a step at the front that classifies the input and sends it to a handler built specially for that kind of input [1].
The value of routing is separation of concerns. Once you split the traffic, each downstream path can have a prompt tuned narrowly for its job, without the compromises that come from trying to serve every case at once. Figure 9.3 shows the shape: a classifier at the door, and behind it a set of specialized handlers, each its own prompt (or even its own small workflow).
There is a second, quietly economical use of routing that is worth calling out. The categories you route on need not be topics at all; they can be difficulty. You can send easy, common questions to a small, cheap, fast model and reserve a larger, more capable, more expensive model for the hard and unusual ones [1]. Most traffic then runs on the cheap path, and you pay for the powerful model only when a question truly needs it, the same “spend the expensive resource only where it earns its place” instinct we met with hybrids in Section 8.6, now applied to model choice.
Push that idea one step further and it becomes a ladder, because difficulty and risk usually travel together. An easy, common FAQ can go to a small, cheap model. A medium policy question can go to retrieval plus a standard model, so the answer is grounded in the actual document rather than the model’s memory. A genuinely ambiguous case can be escalated to a stronger model that can reason through the tangle. And a high-risk or irreversible action, issuing a refund, changing an account, deleting data, does not climb to a bigger model at all; it steps sideways into an approval workflow with a human in the loop. Read the rungs top to bottom and you are routing by difficulty and risk, not merely by topic, spending the expensive resource (a bigger model, or a person’s attention) only on the rungs that earn it.
Routing works well whenever a task splits into distinct categories that are genuinely better handled separately, and the classification itself can be done accurately, by an LLM or by a plain old classifier [1]. So far, though, every pattern has done one thing at a time. Sometimes the fastest, most reliable answer comes from doing several things at once, which brings us to parallelization.
Routing assumes inputs fall into classes separable enough to tell apart early, before much work is done. Its gate is a confidence check on the classifier, with a fallback route for the low-confidence and ambiguous cases, so a shaky guess never commits a case to the wrong lane. Its failure mode is the misroute: a case sent down the wrong handler comes back with a confident, well-crafted, wrong answer. The signals to watch are routing accuracy (are cases landing in the right lane?) and per-lane quality (is each specialized handler actually better on its own traffic than one all-purpose prompt would be?).
9.4 Parallelization
The patterns so far move through their work one step at a time. Parallelization breaks that habit: it runs several LLM calls at the same time and then combines their outputs with a bit of code [1]. Think of a newspaper editor who, facing a deadline, hands the sports section, the weather, and the front-page story to three different reporters at once rather than writing them one after another. The work finishes sooner, and, just as importantly, each reporter gets to concentrate on a single beat. Parallelization comes in two flavors that look similar on a diagram but solve genuinely different problems, so it is worth keeping them straight.
The first flavor is sectioning: you split a task into independent subtasks and run them side by side. The subtasks are different from one another, and each result is a distinct piece of the final whole. A classic use is guardrails: one model instance answers the user’s question while a second, running in parallel, screens the same input for anything inappropriate. Splitting the two jobs works better than asking one call to both answer and police itself, because each call keeps its full attention on one concern [1]. The second flavor is voting: you run the same task several times and aggregate the answers, exactly the self-consistency idea we met in Section 7.7. Here the calls are identical in intent but may disagree, and you use their agreement as a confidence signal, for instance, having several prompts each review a piece of code for security flaws and flagging it if any of them raises a concern [1]. Figure 9.4 shows both.
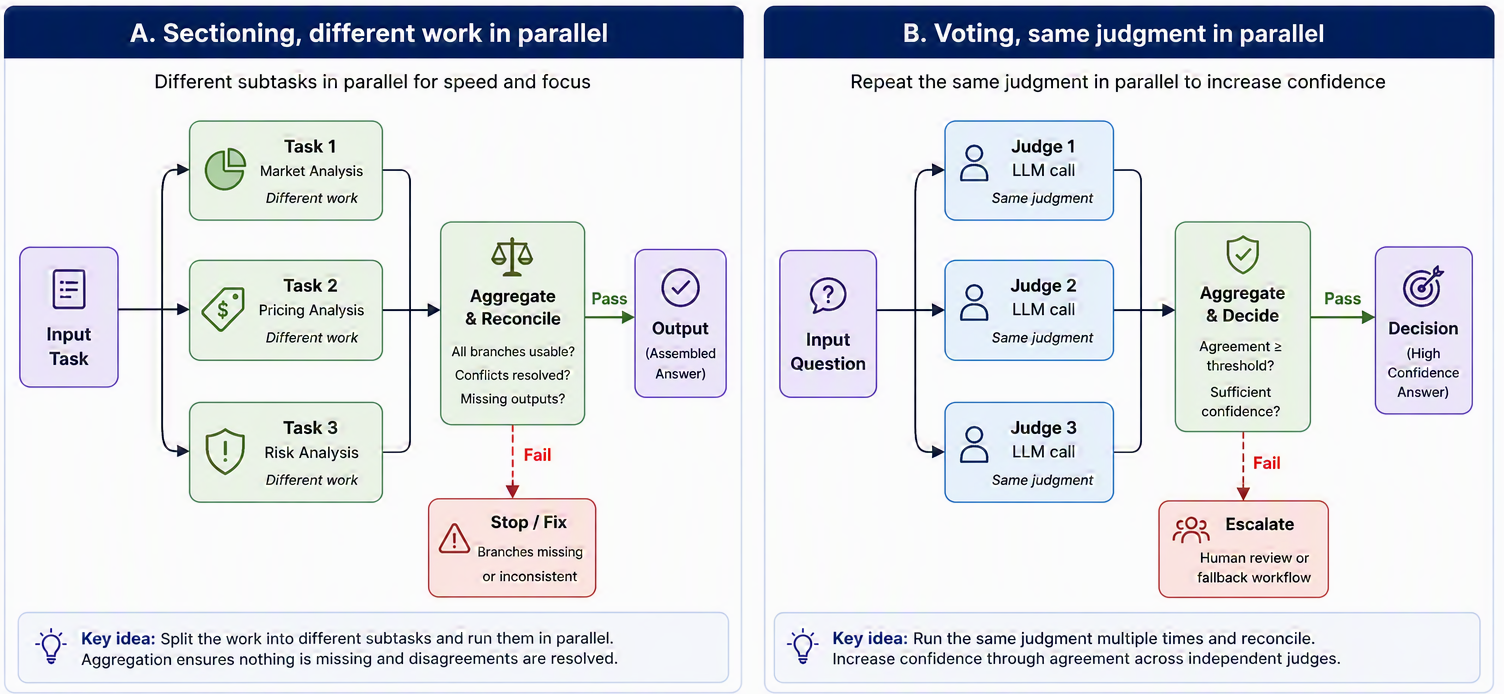
To make the split concrete, picture two very different jobs. To build a product brief, you might section the work: one call analyzes the market, another the pricing, another the risks, and a bit of code stitches the three into a single document. The pieces are different by design, and running them together simply gets you there faster. To classify a borderline support ticket, you might vote: three independent calls each label the ticket, and their agreement becomes your confidence. If all three agree, you trust the label; if they split, you send the ticket to a human. Same diagram shape, opposite purpose: sectioning divides different work, while voting repeats the same judgment.
The two flavors point at the two reasons you would ever parallelize. Sectioning is about focus and speed: independent concerns run faster together and each is handled better in isolation. Voting is about confidence: several attempts at the same judgment, aggregated, are more trustworthy than one, and you can tune the threshold, demanding unanimity when a false negative is dangerous or a simple majority when it is not [1]. Both, though, share a limit that sets up the next pattern: you decide in advance how the work is divided. In sectioning you choose the sections; in voting you choose how many votes. What if the task is one where you genuinely cannot know the subtasks ahead of time, where the way the work should be split depends on the specific input? For that, you need to promote one of the models from worker to manager. That is the orchestrator–workers pattern.
Parallelization assumes the subtasks are independent enough to run without waiting on one another. Its gate is the aggregation step, which checks that every branch returned usable output and reconciles any disagreement before combining. Its failure mode appears when subtasks that were secretly dependent run in isolation and produce pieces that do not fit together. The signal depends on the flavor: for sectioning, watch the latency you save; for voting, watch the agreement rate, since that agreement is exactly the confidence you are buying.
9.5 Orchestrator–workers
Everything up to now has had one thing in common: you fixed how the work was divided. In the orchestrator–workers pattern, that decision moves to the model [1]. A central LLM, the orchestrator, looks at the incoming task, breaks it into subtasks on the spot, hands each to a worker LLM, and then synthesizes the workers’ results into a final answer. Picture a general contractor who arrives at a building site, sizes up the job, and only then decides she needs two electricians, a plumber, and a painter, a call she could not have made from the blueprint alone, because it depends on what she finds when she gets there.
This is what separates orchestrator–workers from the parallelization we just saw, and the distinction is the whole point of the pattern. On a diagram the two look almost identical: a central node fanning out to several workers and gathering their results. But in parallelization the subtasks are predetermined: you wrote the sections into your code. In orchestrator–workers the subtasks are discovered: the orchestrator invents them based on the specific input, so neither you nor it knows the number or shape of the subtasks until the task arrives [1]. Figure 9.5 captures that difference; notice the orchestrator deciding the split at run time.
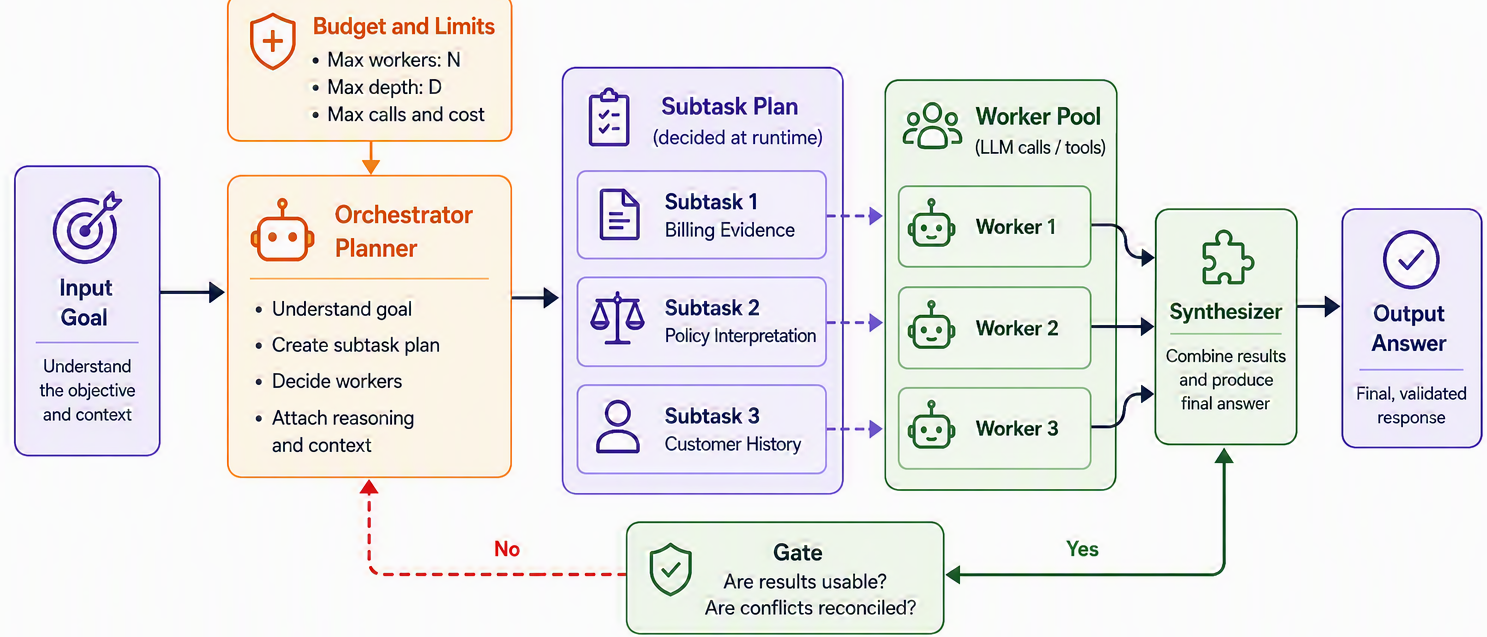
The canonical home for this pattern is coding. When you ask a system to make a change across a codebase, nobody, not you, not the model, knows in advance how many files must change or what each change looks like; it depends entirely on the task and the code it touches [1]. An orchestrator can read the request, figure out which files are involved, dispatch a worker to edit each one, and stitch the edits together. The same shape fits open-ended research, where a lead model decides which sources are worth chasing and sends workers to gather from each. You can feel the pattern edging toward true agency here: we have handed the model control over how the work is divided, which is a real slice of the control flow. It is still a workflow (the orchestrator’s job is bounded to “divide, delegate, synthesize”), but the line to an agent is getting thin. The last pattern crosses a different frontier: instead of dividing work, it loops on quality.
Orchestrator–workers assumes a model can produce a useful decomposition of the task at run time. Its gate is a budget and a required, structured subtask plan (the next callout spells this out). Its failure mode is decomposition gone wrong: over-splitting, redundant or missing workers, or a synthesis that never reconciles what the workers found. The signals to watch are the worker count against the size of the task (is it spawning a sensible number?) and the quality of the final synthesis.
Runtime decomposition is the most powerful shape in this chapter and the most dangerous when it is left unbounded. A poor orchestrator can over-split a simple task, spawn redundant workers, miss a critical one, or synthesize outputs that contradict each other. What keeps it safe is a set of hard constraints, the orchestrator’s version of the agentic step contract from Section 8.6.2: a maximum number of workers, a maximum delegation depth, a required subtask schema so every delegation is structured rather than free-form, a required reason attached to each worker so a spurious one is easy to spot, aggregation that cites the evidence each worker returned, a fallback for when workers disagree, and a hard budget cap on total calls or spend. Give the orchestrator freedom to decide the decomposition, but never freedom without a ceiling.
9.6 Evaluator–optimizer
The final pattern is the one closest to how a careful human actually produces good work, and you have already met its core idea. In Section 7.6 we saw a model improve its own answer by critiquing a first draft and trying again. The evaluator–optimizer pattern turns that instinct into a structured two-role loop: one LLM call generates a response (the optimizer) and a second LLM call evaluates it against explicit criteria and hands back feedback, and the optimizer revises, around and around until the work is good enough [1]. It is the difference between a writer who submits a first draft and a writer who works with an editor: the editor reads, says “the middle drags and the ending is unclear,” and the writer rewrites, a cycle that lifts the result far above what a single pass produces.
Splitting the two roles is what makes this more than “ask the model to try harder.” The generator can pour its attention into producing, and the evaluator can pour its attention into judging against a checklist, without the two jobs blurring together. Figure 9.6 shows the loop: generate, evaluate, and either accept or send pointed feedback back for another round.
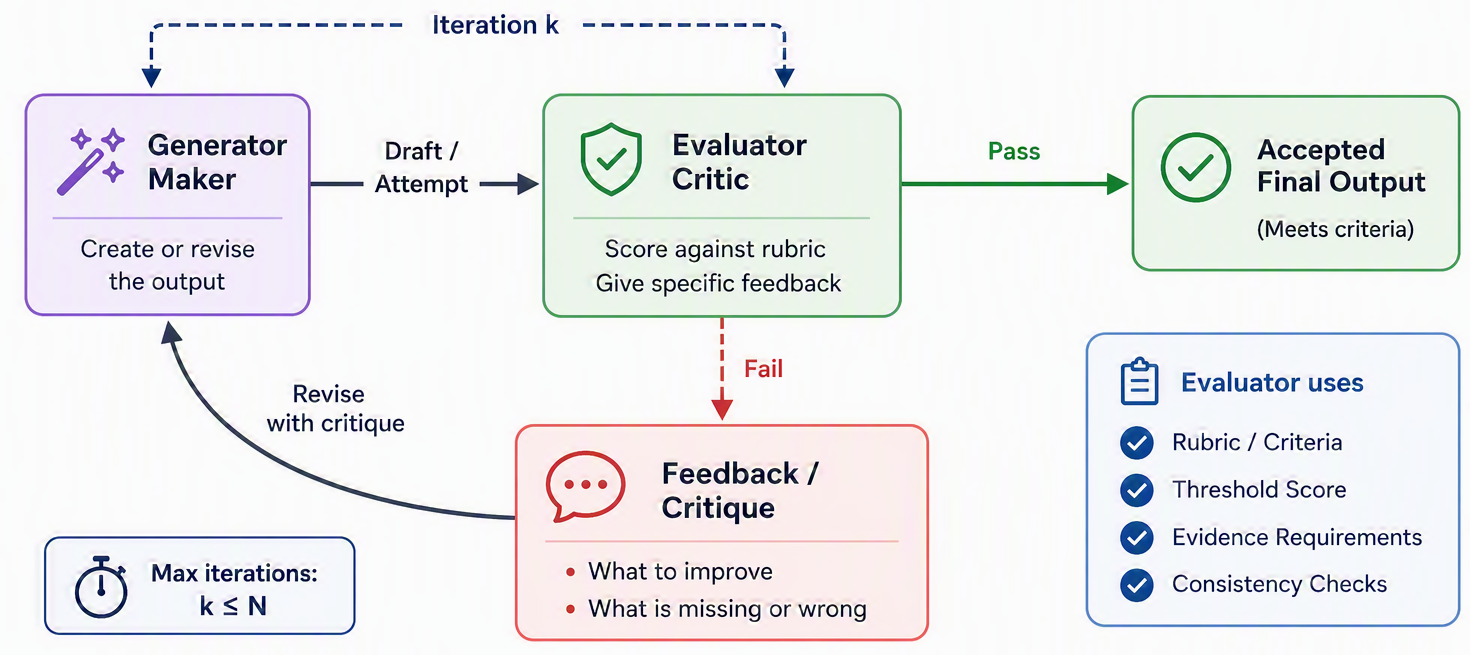
This pattern earns its keep under two specific conditions, and it is worth checking for both before reaching for it. First, you must have clear evaluation criteria, a way to say concretely what “better” means, because a vague critic just adds noise. Second, iteration has to actually help: the tell-tale sign of a good fit is that a human giving written feedback would visibly improve the output, and that the model is capable of producing feedback of that kind [1]. Literary translation is the textbook case: a first pass may miss nuances of tone that an evaluator can name (“this idiom reads too literally”), prompting a better rendering the generator would not have reached alone [1]. Complex research fits too, with the evaluator deciding whether the gathered material is thorough enough or another round of searching is warranted.
It is worth grounding this in Ledgerly before we move on, because the pattern’s strength has an edge to it. Evaluator–optimizer is a natural fit for drafting a customer reply: an evaluator can check the tone, confirm that a required policy citation is actually present, and verify that the reply answers the question that was asked. It is a poor fit for deciding whether a refund qualifies, unless the evaluator checks the draft against the real policy text and the actual billing evidence rather than whether it merely sounds right. The general lesson is to separate style feedback from correctness feedback: an evaluator can judge tone on its own, but it can only judge correctness when it is grounded in a real check [1].
Evaluator–optimizer assumes there is a meaningful, statable way to judge whether one attempt is better than another. Its gate is an explicit rubric, an acceptance threshold, and an iteration cap, so the loop cannot spin forever. Its failure mode is a vague evaluator that adds noise instead of signal: the loop churns without converging because “better” was never pinned down. The signals to watch are the quality gained per iteration (is each round actually improving the work?) and the number of iterations it takes to reach acceptance.
With that, we have all five shapes in hand. The real skill, though, is not any one pattern but knowing how to combine them, and, just as important, when to stop.
9.7 Patterns are assumptions, not recipes
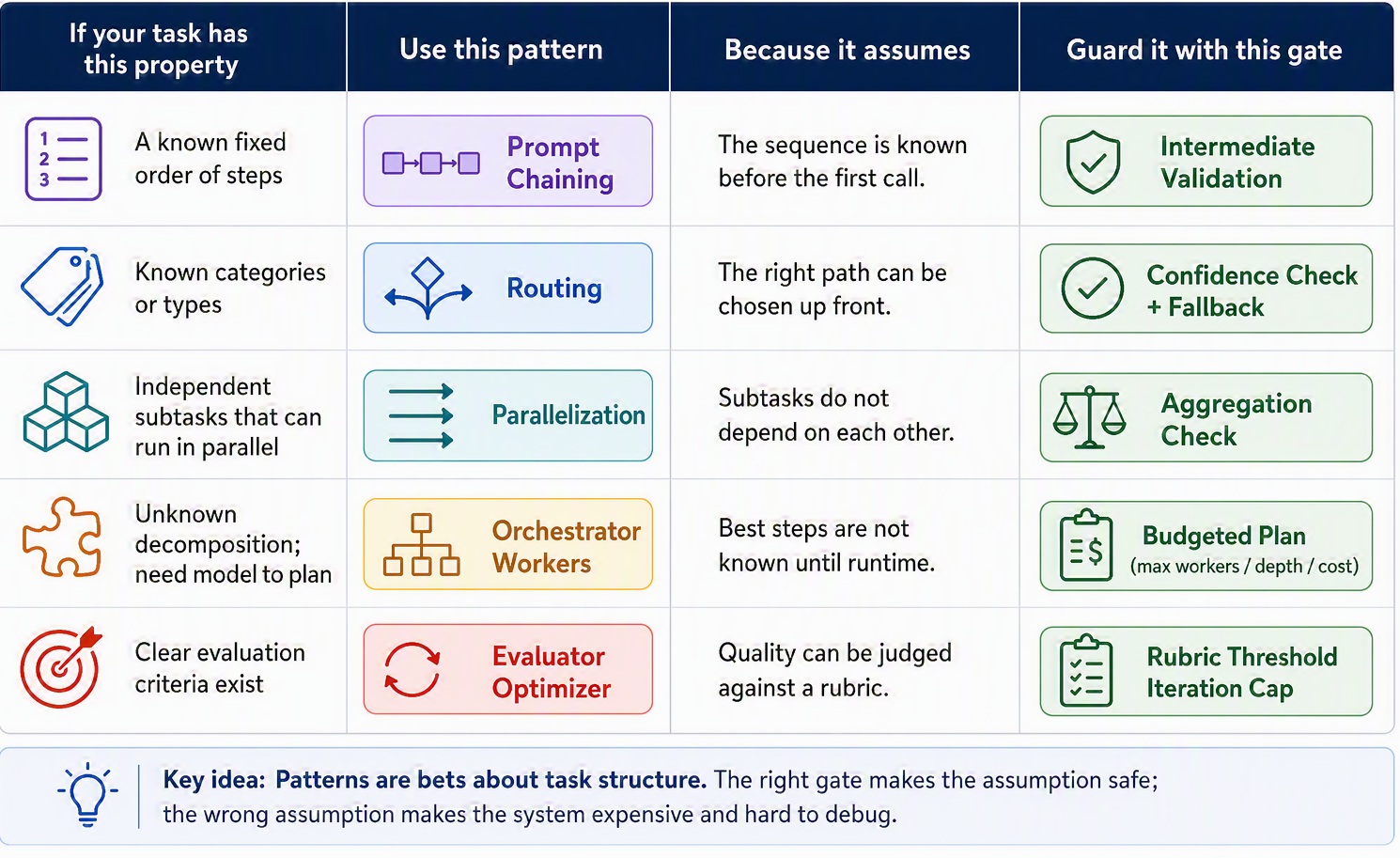
Before we start stacking these shapes into bigger systems, it is worth seeing each pattern for what it really is. A pattern is not a prompt trick or a template you drop in. It is a decision about where control lives, and it works only because it assumes something specific about the problem in front of you. Prompt chaining works because it assumes the order of steps is known. Routing works because it assumes inputs fall into recognizable categories. Change the assumption and the pattern quietly stops fitting, no matter how carefully you wrote the prompts inside it.
Figure 9.7 lines up each pattern with the single assumption that lets it work. Read it as a diagnostic: if you can name which assumption your task satisfies, you have found your pattern; if none of them holds cleanly, that is a sign the task wants a combination, or a genuine agent.
9.7.1 Where control lives
That phrase, where control lives, is the same question Chapter 8 put at the center of the last chapter: who owns the control flow, your code or the model? The five patterns are five different answers, and lining them up that way makes the migration we keep mentioning concrete. In prompt chaining, your code owns the order, and the model only fills in each step. In routing, your code still owns the branch structure, but a classifier picks which branch a given input takes. In parallelization, your code owns the fan-out and the aggregation, and the model works inside the branches. In orchestrator–workers, control crosses a real line: the model decides the decomposition, so it, not your code, determines what the subtasks are. And in evaluator–optimizer, the evaluator owns the one decision that matters most in a loop, whether another iteration happens at all. Walk that list top to bottom and you are watching ownership of the control flow pass, one handhold at a time, from your code to the model.
9.7.2 Every pattern needs a gate
We introduced the idea of a gate back in prompt chaining, a plain code check between steps, but it was never a chaining-only idea. Every pattern has a natural place where a check belongs, and naming them together turns “gate” into a habit rather than a one-off trick:
- Prompt chaining: did the intermediate output meet its requirement, for example did the outline contain the required sections, before we spend the next call?
- Routing: is the classifier confident enough to commit, and if not, does the input fall through to a safe fallback route?
- Parallelization: did every branch return usable output, and does the aggregation reconcile any disagreement rather than silently pick one?
- Orchestrator–workers: did the orchestrator create a sensible number of subtasks, neither over-splitting nor missing a critical one, and does each carry a reason?
- Evaluator–optimizer: did the evaluator apply the rubric consistently, and did we stop at the iteration cap instead of looping forever?
In production these gates rarely stand alone. They pair with durable execution: checkpointing so a long run can resume after a failure, retry policies so a transient error does not sink the whole workflow, and human-in-the-loop steps for the decisions a machine should not make by itself [2]. The gate is not an afterthought bolted on at the end; it is part of the shape of the workflow, designed in from the start.
9.7.3 Choose the pattern whose assumptions your cases support
Put the assumptions and the gates side by side and pattern selection stops being a matter of taste. Table 9.1 collects the five into a single decision aid: what each pattern is good for, where it breaks, and the one gate you should never ship without.
| Pattern | Use when | Avoid when | Key gate |
|---|---|---|---|
| Prompt chaining | the steps are fixed and known in advance | the right sequence depends on the input | validate each intermediate output before the next call |
| Routing | inputs fall into classes you can tell apart early | categories blur and cases resist classification | classifier-confidence check with a fallback route |
| Parallelization | subtasks are independent and can run at once | subtasks secretly depend on one another | aggregation that checks all branches and reconciles them |
| Orchestrator–workers | a useful decomposition can only be found at run time | the subtasks are known ahead of time (just parallelize) | a budget plus a required structured subtask plan |
| Evaluator–optimizer | there is a clear, statable way to judge “better” | “better” is vague, or iteration does not help | an explicit rubric, an acceptance threshold, and an iteration cap |
The habit this table is meant to build is a single question you ask before adding any pattern: what assumption am I making about this task, and do my real cases support it? If you can answer it with evidence, the pattern will hold. If you cannot, no amount of prompt engineering inside the pattern will save you, because the mismatch is in the shape, not the wording. With each pattern understood as an assumption guarded by a gate, we are finally ready to do the thing real systems do: combine them.
9.8 Combining patterns
Here is the secret that makes the five patterns worth learning: they are not five separate machines but five bricks, and real systems are built by stacking them. None of the patterns is prescriptive; each is a shape you can nest inside another to fit the problem in front of you [1]. A routing step can send a refund request into a prompt chain and a technical issue into an orchestrator–workers subsystem. Any single step in a chain can itself be an evaluator–optimizer loop. A worker inside an orchestrator can be running its own little parallelization. The patterns compose the way rooms compose into a house, and almost every production system you will ever read about is just a particular arrangement of these few rooms.
But composability is a temptation as much as a gift, and this is the part to take to heart. Every brick you add buys some capability and charges you in latency, cost, and things that can go wrong: more calls to wait on, more places to debug, more surface for errors to compound. The guiding rule is the same one that opened Chapter 8, now sharpened to a test: add a pattern only when it demonstrably improves the outcome, measured against real cases, not when it merely makes the architecture feel more sophisticated [1]. The goal is never the most elaborate system; it is the simplest one that meets the need.
When a system misbehaves, resist the reflex to add another pattern on top. More often the fix is to remove a layer, tighten a prompt, or sharpen an evaluator’s criteria. Measure first, then change one thing, then measure again. Complexity you cannot justify with numbers is complexity that will cost you later: in dollars, in latency, and in the hours you spend debugging it.
9.8.1 If patterns compose, traces must compose
There is a hidden cost to all this stacking that the diagrams do not show, and it is worth naming before we build anything. A composed system is only as debuggable as its trace. When a router feeds a chain that contains an evaluator loop, a wrong final answer could have come from a misroute, a bad intermediate, or an evaluator that gave up too early, and if all you logged was the final reply you cannot tell which. Composed systems act over many steps, and mistakes in early steps propagate and compound downstream, so you have to be able to see the whole trajectory, not just the answer at the end [3].
Concretely, log something at every pattern boundary:
- the input to the step, so you can reproduce it;
- the chosen path or route, and the classifier’s confidence when there was one;
- the intermediate outputs each step produced;
- the gate results, so you know which checks passed and which failed;
- which model handled the step, since routing by difficulty means it varies;
- the tool calls made and what they returned;
- any errors, and the iteration counts for loops;
- the final decision, and any human handoff that occurred.
This is exactly the payoff of expressing a workflow as an explicit graph: when the control flow is a structure your code can see rather than logic buried in prompts, tracing and debugging become possible, because every node and edge is a place you can instrument [4]. The later implementation chapters make these graphs concrete; for now, the rule to carry is that a system you cannot trace is a system you cannot trust, so design the trace at the same time as the patterns.
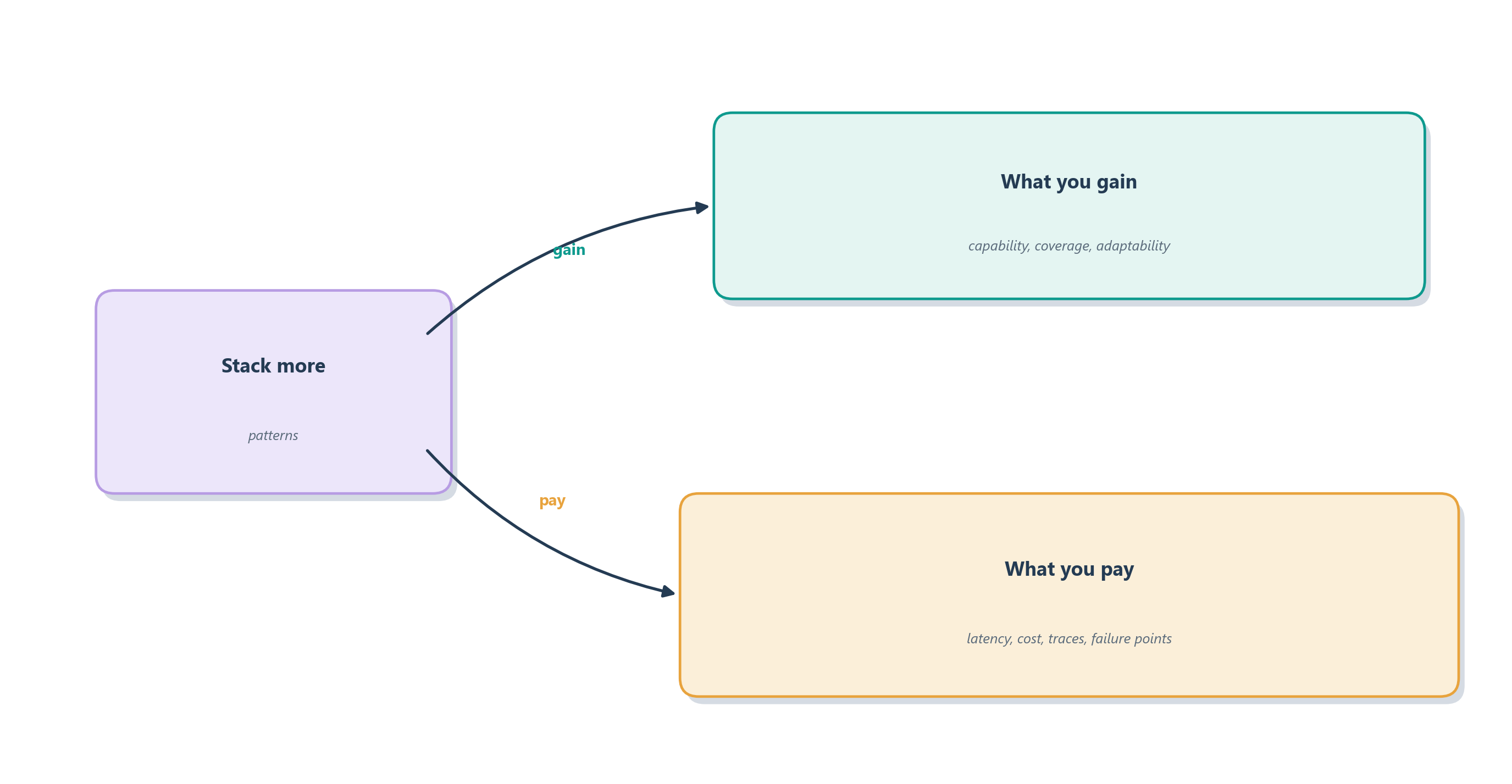
Figure 9.8 is why this matters in practice. Each pattern you add buys capability and charges you back in latency, cost, trace volume, and places to debug. Seeing the bill laid out next to the benefit is what turns “add a pattern only when a measurement earns it” from a slogan into a habit.
There is one more thing to notice as we close the toolbox. Walk the five patterns from left to right and you can watch control quietly migrate from your code to the model: fixed in a chain, branching in a router, discovered by an orchestrator, looping under an evaluator’s judgment. Push that migration to its conclusion, let the model decide every step, not just how the work is divided or when it is done, and the workflow has become an agent, the autonomous loop we first opened up in Section 7.5. The patterns in this chapter are the well-lit path you should walk as far as it takes you before handing the model the wheel. To make all of this concrete, let’s build one modest system out of these bricks, end to end.
9.9 A worked example: a support desk, assembled
Patterns are easiest to trust once you have watched them snap together on a real problem, so let’s build the customer-support system we kept using as an illustration, this time wiring the actual bricks. The goal is ordinary and concrete: a ticket comes in, and the system should produce a good reply (or escalate) without a human touching every one. Watch how each pattern earns its place, and notice that we reach for the fancier ones only where the simpler shapes run out.
We start at the door with routing. A classifier reads the incoming ticket and sorts it into one of three lanes: a simple FAQ, a refund request, or a complex multi-part problem. That single decision lets each lane be built differently, which is the whole reason to route. The FAQ lane is the simplest thing that works: a single well-crafted LLM call with the relevant help article in context, no more. The refund lane is a prompt chain: look up the order, check it against the refund policy with a programmatic gate, then draft the reply, a fixed, auditable line of steps, exactly what you want when money is involved. The complex lane is the one no fixed path fits, so it hands off to an orchestrator–workers step that breaks the tangled ticket into its parts and works each one. Before anything is sent, every draft passes through a shared evaluator–optimizer gate that checks tone and correctness and sends weak drafts back for a rewrite. Figure 9.9 shows the assembled system.
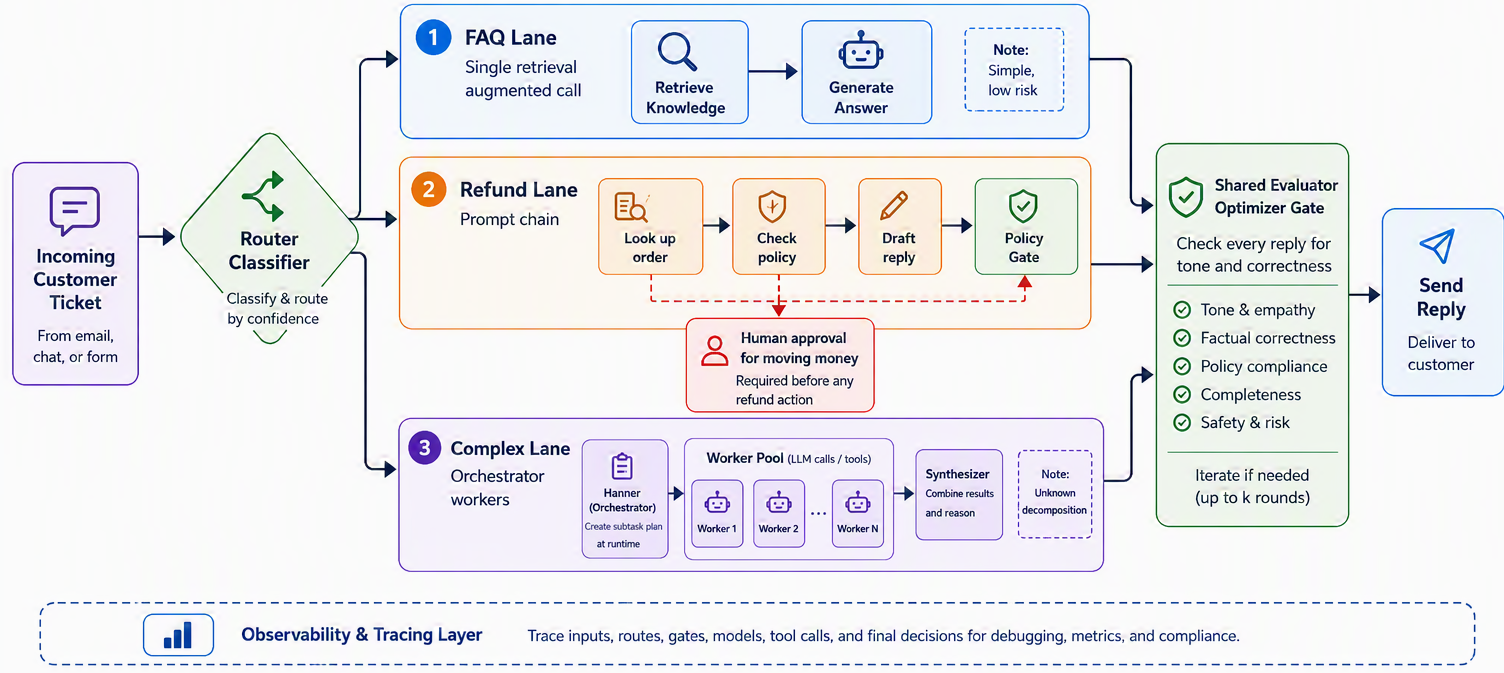
Read the design back and you can see every principle of the chapter at work. Each lane uses the simplest pattern that fits its job, not the most powerful: the FAQ lane never gets an orchestrator it does not need. Control migrates rightward exactly where the problem demands it: the refund lane stays on a fixed chain because refunds have a fixed procedure, while the complex lane hands the model more freedom precisely because its tickets have no predictable shape. And the evaluator gate is shared, added once, because measurement showed drafts occasionally went out with the wrong tone, a pattern introduced to solve a real, observed problem rather than a hypothetical one. If a hand-drawn pseudocode sketch helps, the spine is just this: lane = route(ticket), then draft = lane.handle(ticket), then while not evaluate(draft): draft = revise(draft), then send(draft). Four patterns, one modest system, and nothing in it that a measurement did not justify. That restraint, building only what the problem asks for, is the real lesson to carry out of this chapter.
9.10 Case study: the Ledgerly support agent
Where we left off, Section 8.9 sorted Ledgerly’s traffic into three lanes but left us without the machinery to run them. The worked example you just read, the assembled support desk in Section 9.9, is that machinery: it is the Ledgerly support desk, built from this chapter’s patterns. It is worth naming which pattern fills each lane, because that mapping is the whole design.
The three lanes from Section 8.9 land on the three shapes in Figure 9.9. Routing at the door sorts a ticket into FAQ, refund, or complex, the classification we described by hand last chapter now done by a real classifier. The FAQ lane is the single well-crafted call, the simplest thing that works. The refund lane is the prompt chain, a fixed and auditable procedure, which is exactly right because Section 8.9 argued a refund’s steps never change even though it moves money. The complex lane hands off to orchestrator–workers, the one place Ledgerly spends real autonomy. And a single shared evaluator–optimizer gate reviews every draft before it is sent, so tone and correctness are checked no matter which lane produced the reply.
Stated as decisions, the whole design is five deliberate choices, one per Ledgerly need:
| Ledgerly need | Design decision | Pattern |
|---|---|---|
| Answer a policy or how-to question | a single retrieval-augmented call | RAG call |
| Decide whether a refund qualifies | a fixed, auditable workflow | prompt chain |
| Untangle a messy multi-charge complaint | an agent with room to investigate | orchestrator–workers |
| Check every reply before it ships | a shared quality gate | evaluator–optimizer |
| Actually move the money | a human approval step | human-in-the-loop |
The first four are built in this chapter. The fifth, approval before any refund is paid, is the human-in-the-loop gate already sketched into the blueprint (Figure 9.10) and wired up in Section 12.7; it is a design decision now even though its machinery arrives later.
The lesson the worked example draws, that you should build only what a measurement justifies, is the discipline Ledgerly carries into production. The evaluator gate was not added on a hunch; it earned its place because drafts occasionally went out with the wrong tone. That habit of adding a layer only when the evidence asks for it is what keeps the growing system from collapsing under its own cleverness.
9.10.1 Inside the complex lane
The complex lane is worth opening up, because it is where three of this chapter’s patterns nest inside one another. When a messy multi-charge ticket arrives, the first thing Ledgerly needs is evidence, and the pieces of evidence do not depend on each other: the recent charges, the plan history, the relevant refund policy, and any prior tickets from this customer can all be fetched at once. That is parallelization by sectioning, and it is here purely for speed, since making four independent lookups one after another would keep the customer waiting for no reason.
Most complex tickets are answered from that evidence alone. But some are genuinely unusual, a tangle no fixed set of lookups anticipated, and for those Ledgerly escalates to an orchestrator–workers step. The orchestrator reads the assembled evidence and decides, at run time, which role-scoped workers the case actually needs: a billing analyst to reconcile the charges, a policy worker to interpret the rules, a support-history worker to weigh the customer’s past, and a customer-communication worker to shape the tone. Crucially, it runs under the budget from Section 8.6.2 and this chapter’s orchestrator caution: a cap on workers, a required subtask schema, a reason attached to each worker, and a fallback for when they disagree, so the added freedom never becomes a runaway.
Whatever the complex lane produces, the draft still passes through the same shared evaluator–optimizer gate as every other lane, which checks tone and correctness before a word reaches the customer. Notice what this lane is and is not. It is not sophisticated because it uses three patterns; a simpler ticket would use none of them. It is sophisticated because each pattern is used exactly where it fits: parallelization where the work is independent, an orchestrator where the decomposition cannot be known in advance, and an evaluator where quality has to be guaranteed. That is the whole discipline of the chapter, seen in one lane.
Step back from the individual lanes and you can see Ledgerly whole. Figure 9.10 is the blueprint we will carry to the end of the book. This chapter builds its left half: the router at the door, the three lanes, and the shared evaluator gate that checks every reply. The other parts, the shared tools, the memory store, the human-approval gate, and the observability layer beneath everything, are already sketched in because each comes online in a chapter still ahead. From here on, every installment lights up one more part of this same picture instead of drawing an unrelated diagram.
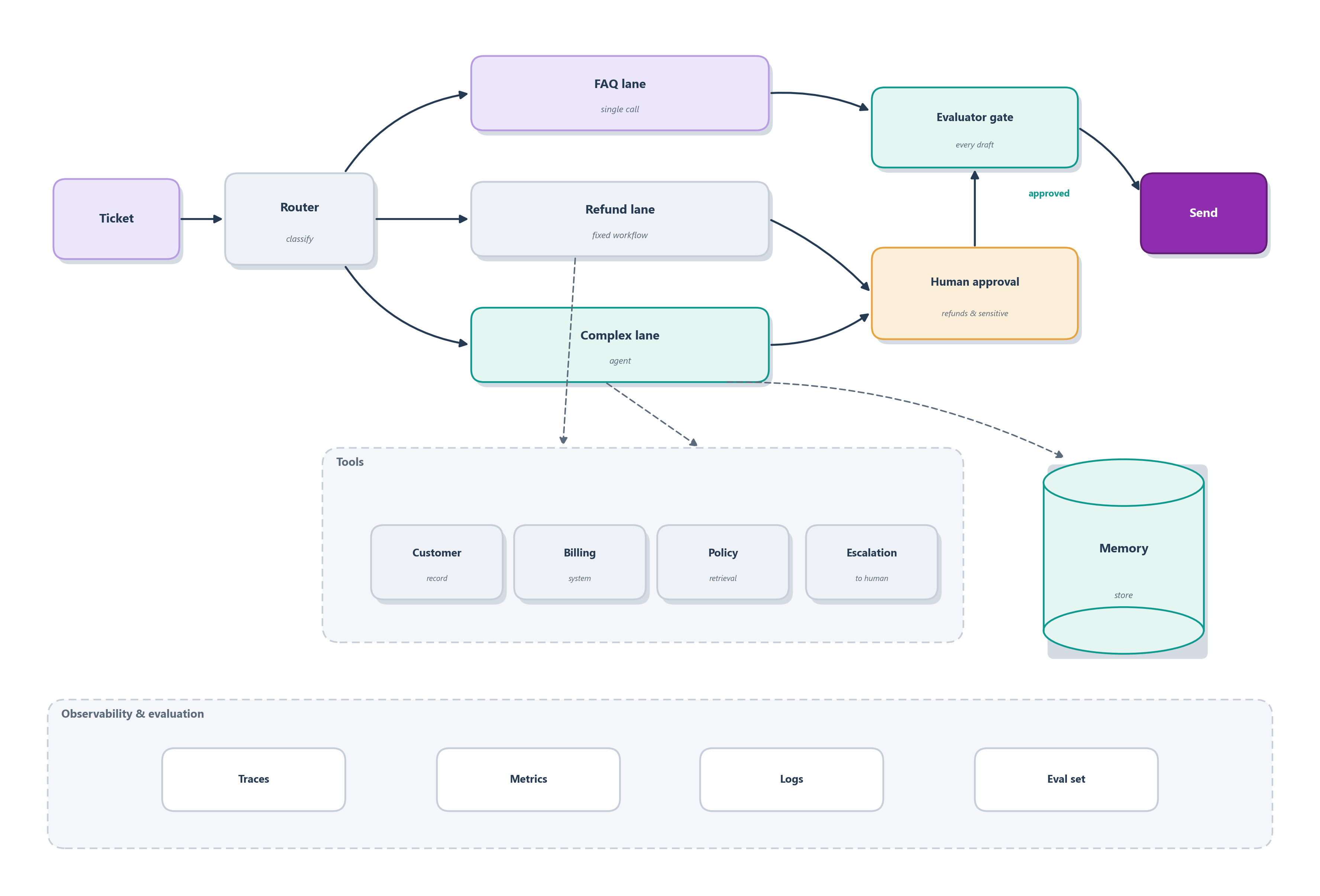
The patterns give Ledgerly its floor plan, but two lanes assume the agent can actually do things: look up a charge, issue a refund. Section 10.9 designs those tools properly and puts them behind an MCP server the whole desk can share.
The lanes now have machinery, drawn in Figure 9.10:
- A router at the door sends each ticket to the FAQ, refund, or complex lane.
- Lanes are built from named patterns: single call, prompt chain, orchestrator–workers.
- Tools, retrieval, and memory back every lane.
- New this chapter: a shared evaluator gate reviews every draft before it is sent.
9.11 Summary
This chapter handed you the floor plans of agentic systems: a small set of reusable shapes that, combined, describe almost everything built in production.
- Prompt chaining runs a task as a fixed line of steps, each working on the last one’s output, with optional gates between them. It trades a little latency for higher accuracy and fits tasks whose steps you already know.
- Routing classifies each input and sends it to a specialized handler, giving separation of concerns, and, as a bonus, a way to send easy cases to cheap models and hard ones to capable ones.
- Parallelization runs work concurrently: sectioning splits a task into different subtasks for focus and speed, while voting repeats the same task for confidence.
- Orchestrator–workers lets a lead model divide a task into subtasks at run time, which is what you need when the subtasks cannot be known in advance, as in editing an unknown set of files.
- Evaluator–optimizer loops a generator against a critic until the work meets explicit criteria, a structured form of the reflection idea from Section 7.6.
- Compose freely, but add complexity only when it demonstrably helps. The patterns nest like rooms in a house; the craft is building the simplest arrangement that meets the need, and measuring before you add another layer.
- Patterns are assumptions, not recipes. Each pattern works only because it assumes something about the task (a known order, known categories, independent subtasks, an unknown decomposition, or a clear notion of “better”); choose the one your real cases actually support, and ask what assumption you are making before you reach for it.
- Every pattern needs a gate. An intermediate check, a routing-confidence fallback, an aggregation check, a worker budget, an evaluator rubric: the gate is what turns a pattern from a hopeful call into a dependable step, and in production these gates pair with durable execution.
- Route by difficulty and risk, not only topic. Sending easy cases to cheap models, hard ones to capable models, and irreversible actions to a human is routing that spends the expensive resource only where it earns its place.
- Give an orchestrator a budget, and give a composed system a composed trace. Runtime decomposition needs hard limits to stay safe, and a system built from many patterns is only debuggable if you log the input, path, gates, models, and decisions at every boundary.
Read the patterns left to right and you watched control migrate from your code toward the model, step by step, until, at the far end, the model owns every decision and the workflow has become a true agent. Two of these patterns, though, quietly assumed something we have not yet examined closely: that the model can reach out and do things in the world, look up an order, edit a file, search a source. That capability is the augmented LLM’s hands, and it deserves a chapter of its own. Next we open up tools and the standard that is fast becoming their common language, the Model Context Protocol, in Chapter 10.
9.12 Exercises
- Name that pattern. For each system, identify which pattern (or combination) it uses:
- a translator that drafts a translation, has a second model critique it, and revises;
- a moderation system where one model answers and another simultaneously screens the input;
- a help desk that sends billing questions and technical questions down different prompts;
- a coding tool that decides which files to change and edits each one.
- Chain with a gate. Design a three-step prompt chain for turning a rough set of meeting notes into a polished summary. Where would you put a programmatic gate, and what would it check?
- Sectioning vs. voting. Give one task where sectioning is the right form of parallelization and one where voting is, and explain what each buys you that the other would not.
- Draw the line. Explain, in your own words, the difference between parallelization and orchestrator–workers. Why can the two look identical on a diagram yet solve different problems?
- Resist the upgrade. Take the assembled support desk from Section 9.9 and propose one pattern you could add to make it “smarter.” Then argue the other side: what evidence would you want before adding it, and what might it cost you?
- Name the assumption. Pick a task you would build with one of the five patterns. State the hidden assumption that pattern makes about the task, then describe a real, specific case that would violate it and quietly break the pattern.
- Gate every stage. Take a composed pipeline, say routing into a prompt chain whose last step is an evaluator loop, and design the gate for each stage: what does it check, and what happens when the check fails?
- Budget the orchestrator. Write an explicit budget for Ledgerly’s complex lane: a maximum number of workers, the structured subtask schema each worker must receive, and the fallback to apply when two workers disagree.
- Design the trace. List the fields you would log to debug a routing-plus-chain-plus-evaluator pipeline, and for each field explain which failure it would help you diagnose.